Addressing Ethical Considerations in AI Deployment under GDPR
Discover how the General Data Protection Regulation (GDPR) impacts AI deployment and how businesses must adhere to its ethical framework to ensure consumer privacy and data protection while fostering innovation.
Staff


The deployment of Artificial Intelligence (AI) systems within the European Union is governed by a sophisticated and evolving legal architecture. This framework is anchored by two principal pillars: the General Data Protection Regulation (GDPR), which establishes a comprehensive regime for the protection of personal data, and the nascent EU AI Act, which introduces a product-safety-oriented, risk-based approach to the regulation of AI technologies themselves. Understanding the distinct yet overlapping requirements of these two instruments is fundamental for any organization seeking to innovate responsibly within the EU's digital single market. This regulatory duality creates a complex compliance landscape where the protection of individual rights and the assurance of technological safety are inextricably linked.
Section 1: Foundational GDPR Principles in the Age of AI
The General Data Protection Regulation provides the foundational legal framework for any AI system that processes personal data. Its core principles, articulated in Article 5, are not abstract ideals but concrete legal obligations that apply with full force throughout the entire AI lifecycle, from initial data sourcing and model training to final deployment and ongoing operational use. The application of these principles to the unique characteristics of AI—its data-intensive nature, its probabilistic outputs, and its potential for opacity—creates significant compliance challenges.
Core Principles and Lifecycle Application
The GDPR establishes a set of fundamental principles that must govern all personal data processing activities. These principles are technologically neutral and form the bedrock of compliance for AI systems.
Lawfulness, Fairness, and Transparency: All data processing must be lawful, fair, and transparent. For AI, this means establishing a clear legal basis under Article 6 for each processing activity. It also requires organizations to be transparent with individuals about how their data is being used by AI systems, a task complicated by the algorithmic complexity of many models.
Purpose Limitation: Personal data must be collected for "specified, explicit, and legitimate purposes" and not further processed in a manner that is incompatible with those purposes. This presents a direct challenge to the development of general-purpose AI models, where all potential future applications cannot be foreseen at the training stage.
Data Minimization: Processing must be limited to what is "adequate, relevant and necessary" for the specified purpose. This principle is in direct tension with the "data hungry" nature of many machine learning models, which often achieve higher performance with larger datasets.
Accuracy: Personal data must be accurate and, where necessary, kept up to date. In the AI context, this applies not only to the input data but also to the inferences and predictions the model generates. Inaccurate training data can lead to biased and harmful outputs.
Storage Limitation: Personal data should be kept in a form which permits identification of data subjects for no longer than is necessary for the purposes for which the data are processed. This affects how long AI training datasets containing personal data can be retained and reused.
Integrity and Confidentiality: Personal data must be processed in a manner that ensures appropriate security, including protection against unauthorized or unlawful processing and against accidental loss, destruction, or damage. This requires robust cybersecurity measures for AI systems and the data they handle.
Accountability: The data controller is responsible for, and must be able to demonstrate, compliance with all of the above principles. This is the cornerstone of GDPR governance, requiring comprehensive documentation, risk assessments, and clear internal policies.
A critical aspect of navigating this landscape is recognizing that compliance obligations shift and evolve as an AI system moves through its lifecycle. The legal justification for training a model is not the same as for deploying it. The development and operational phases of an AI system are considered distinct processing activities, each requiring its own specific purpose and lawful basis assessment. For instance, an organization might rely on "legitimate interest" as the lawful basis for processing publicly available data to train a model. However, when that model is deployed to make automated decisions about individuals in the context of a service, the lawful basis might shift to "performance of a contract," which could in turn trigger the specific requirements of GDPR Article 22 concerning automated decision-making. This dynamic nature of compliance means that a single, static assessment is insufficient. Organizations must adopt a stage-gate approach, re-evaluating their legal and ethical posture at key inflection points: before data acquisition, before model training, before deployment, and during ongoing monitoring. Failure to manage these transitions can render a lawfully trained model non-compliant at the moment of its use, creating significant legal and reputational risk.
Data Subject Rights in the AI Context
The GDPR grants individuals a suite of powerful rights to control their personal data, and these rights apply fully to AI systems. Implementing these rights, however, poses significant technical challenges.
Right of Access (Article 15): Individuals have the right to access their personal data and receive information about how it is processed, including meaningful information about the logic involved in automated decision-making.
Right to Rectification (Article 16): Individuals can demand the correction of inaccurate personal data.
Right to Erasure ('Right to be Forgotten') (Article 17): This right is particularly difficult to implement in AI. Once an individual's data has been used to train a model, it becomes embedded in the model's parameters. Fully removing its influence may require costly and complex retraining of the model from scratch.
Right to Object (Article 21): Individuals have the right to object to processing based on legitimate interests.
Rights Related to Automated Decision-Making (Article 22): Individuals have the right not to be subject to a decision based solely on automated processing, including profiling, which produces legal or similarly significant effects. This right is not absolute and has exceptions, but it requires safeguards like the right to obtain human intervention and to contest the decision.
The technical difficulty of facilitating these rights does not absolve organizations of their legal duty. Regulatory guidance, such as from the UK's Information Commissioner's Office (ICO), emphasizes that models must be engineered from the outset to accommodate data subject rights, for instance by implementing mechanisms to filter outputs or "unlearn" specific data points. This reinforces the principle of Privacy by Design, making it a legal and practical necessity for AI development.
Section 2: The EU AI Act: A New Pillar of Technology Regulation
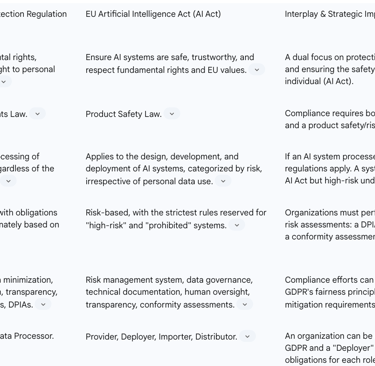
Complementing the GDPR's focus on data protection, the EU AI Act establishes a horizontal regulatory framework for Artificial Intelligence itself. It operates not as a data privacy law, but as a product safety law, designed to ensure that AI systems placed on the EU market are safe, trustworthy, and aligned with fundamental rights and EU values. Its introduction signals a new era of technology regulation, focusing on the tool rather than just the data it processes.
A Product Safety Paradigm and Risk-Based Approach
The fundamental logic of the AI Act is its risk-based approach, which categorizes AI systems into a pyramid of four distinct risk levels. This structure concentrates the most stringent regulatory obligations on the applications deemed to pose the greatest potential harm to health, safety, and fundamental rights.
Unacceptable Risk: The Act outright prohibits certain AI practices considered a clear threat to people. This includes systems that deploy manipulative subliminal techniques, exploit the vulnerabilities of specific groups to cause harm, or are used for social scoring by public authorities. The European Commission has provided detailed guidance clarifying that this also covers real-time and post remote biometric identification in publicly accessible spaces for law enforcement, with very narrow exceptions.
High-Risk: This is the most heavily regulated category and forms the core of the AI Act's compliance regime. The Act provides an exhaustive list of high-risk use cases in its Annex III. These include AI systems used as safety components in products (e.g., medical devices), as well as systems in critical sectors such as employment (e.g., CV-sorting software), education (e.g., scoring exams), access to essential services (e.g., credit scoring), law enforcement, and the administration of justice. Providers of high-risk systems must adhere to a strict set of requirements, including implementing a risk management system, ensuring high-quality data governance, maintaining extensive technical documentation, enabling effective human oversight, and achieving a high level of accuracy and cybersecurity.
Limited Risk: AI systems that pose a limited risk, such as chatbots or systems that generate "deepfakes," are subject to specific transparency obligations. Users must be clearly informed that they are interacting with an AI system or that content is artificially generated or manipulated, allowing them to make informed decisions.
Minimal Risk: The vast majority of AI applications, such as AI-enabled video games or spam filters, are expected to fall into this category. The Act imposes no new legal obligations on these systems, encouraging voluntary adherence to codes of conduct.
The AI Act's risk-based framework fundamentally recalibrates the compliance journey for organizations. Unlike the GDPR, where obligations apply to all processing of personal data, the AI Act creates a critical initial gateway: the classification of the AI system. The entire compliance pathway, and its associated cost and effort, hinges on the determination of whether a system falls into the high-risk category. This places immense strategic importance on the initial legal and technical assessment of any AI use case against the criteria in Annex III. An incorrect classification could lead either to a massive over-investment in compliance for a system that does not require it, or to a catastrophic regulatory failure and market exclusion for a high-risk system that was not properly managed. Therefore, the first operational step for any robust AI governance program must be the implementation of a rigorous, documented process for classifying AI systems according to the Act's risk tiers.
Scope and Key Roles
The AI Act defines specific roles and responsibilities for different actors in the AI value chain, extending obligations beyond just the initial developer.
Provider: The entity that develops an AI system with a view to placing it on the market or putting it into service under its own name or trademark. Providers bear the primary responsibility for compliance, especially for high-risk systems.
Deployer (formerly "User"): Any entity using an AI system under its authority, except where the use is in the course of a personal non-professional activity. Deployers of high-risk systems have obligations to ensure proper human oversight and use the system in accordance with its instructions.
Importer and Distributor: These actors in the supply chain have obligations to verify that the provider has met its compliance duties.
The Act possesses significant extraterritorial reach. It applies to providers and deployers regardless of their location if the AI system is placed on the EU market or if the output produced by the system is used within the EU. This effectively makes compliance a prerequisite for accessing the EU's digital single market.
Section 3: Regulatory Convergence and Divergence: Navigating the GDPR-AI Act Nexus
While the GDPR and the AI Act operate on different legal foundations—one rooted in fundamental rights to data protection, the other in product safety—they are designed to be complementary. For the many AI systems that process personal data, compliance is not a matter of choosing between the two regulations, but of navigating their dual application. An organization can simultaneously be a "data controller" under GDPR and a "provider" or "deployer" under the AI Act, with distinct but overlapping obligations for each role.
This dual framework, with its combined extraterritorial reach, is creating a powerful "Brussels Effect" for AI governance. Just as the GDPR became the de facto global standard for privacy, the GDPR-AI Act nexus is establishing a comprehensive model for trustworthy AI that is influencing regulation worldwide. For multinational corporations, developing separate AI governance programs for different regions is becoming increasingly inefficient and risky. The most strategically sound path forward is to adopt the stringent, dual-framework of the EU as a global baseline for all AI development and deployment. This approach simplifies internal governance, mitigates risk, and future-proofs the organization against emerging regulations in other jurisdictions that will inevitably draw inspiration from the EU's pioneering model.
Leveraging Compliance Synergies
Despite their differences, the two regulations share a common logic in several key areas, allowing organizations to create integrated compliance frameworks that avoid duplicative effort.
Accountability and Documentation: Both laws demand robust documentation. The GDPR's requirement to maintain a Record of Processing Activities (RoPA) under Article 30 can serve as a foundational element for the more detailed technical documentation mandated for high-risk AI systems under the AI Act.
Risk Assessments: The GDPR's Data Protection Impact Assessment (DPIA), required for high-risk data processing, shares a common purpose with the AI Act's conformity assessments and the Fundamental Rights Impact Assessments (FRIAs) required of certain deployers. All are designed to proactively identify, assess, and mitigate risks to individuals. Organizations can develop unified risk assessment templates that address both data protection impacts and broader AI safety and fundamental rights risks.
Fairness and Bias Mitigation: The GDPR's principle of "fairness" directly aligns with the AI Act's requirements for data governance (Article 10) and accuracy (Article 15), both of which compel providers of high-risk systems to examine datasets for potential biases and take measures to mitigate them.
Human Oversight: The right to obtain human intervention under GDPR Article 22 is reinforced and expanded by the AI Act's explicit requirement in Article 14 for high-risk AI systems to be designed for effective human oversight.
The table below provides a comparative analysis of the two regulations to help clarify their distinct and overlapping domains.

Part II: High-Friction Zones: Core Challenges at the Intersection of AI and Data Protection
While the legal frameworks provide a map for compliance, the journey is fraught with high-friction zones where the inherent nature of AI technology clashes with the principles of data protection. These areas of tension represent the most significant legal and ethical challenges for organizations. Successfully navigating them requires not only legal interpretation but also technical innovation and a deep commitment to ethical governance.
Section 4: The 'Black Box' Dilemma and the Right to Explanation
One of the most profound challenges in AI governance is the "black box" problem, where the internal decision-making processes of complex models, particularly deep neural networks, are opaque and not easily interpretable by humans. This inherent opacity creates a direct conflict with the GDPR's principles of transparency and accountability, and it lies at the heart of the debate over the "right to explanation."
The Contested Right to Explanation
The GDPR does not contain an explicit, standalone "right to explanation." Instead, this concept is derived from a combination of provisions that, taken together, create a powerful transparency obligation for automated decisions.
Information Rights (Articles 13, 14, and 15): These articles require data controllers to provide individuals with "meaningful information about the logic involved, as well as the significance and the envisaged consequences" of automated decision-making. This information must be provided both proactively at the time of data collection (ex-ante) and upon request (ex-post).
Right to Human Intervention (Article 22): This article grants individuals the right not to be subject to a decision based solely on automated processing that has legal or similarly significant effects. It also provides the right to obtain human intervention, express one's point of view, and contest the decision.
The interpretation of "meaningful information about the logic involved" has been a subject of intense academic and legal debate. Early analysis suggested the right was limited or even non-existent due to the narrow scope of Article 22 (applying only to "solely" automated decisions) and the protection of trade secrets. However, recent regulatory guidance and jurisprudence have moved toward a more robust interpretation.
A landmark decision by the Court of Justice of the European Union (CJEU) on February 27, 2025, confirmed the existence of a "right of explanation". The Court ruled that "meaningful information" requires the controller to provide relevant information on the procedure and principles applied, in a concise, intelligible, and easily accessible form. Crucially, the CJEU stated that the complexity of an algorithm does not relieve the controller of the duty to "translate" its logic into layman's terms. This means burying a user in complex mathematical formulas is insufficient; organizations must find simple ways, such as infographics or clear criteria-based explanations, to convey the rationale behind a decision. This ruling places a significant burden on companies to move beyond mere disclosure and toward genuine comprehensibility.
The Role and Limits of Explainable AI (XAI)
In response to this regulatory pressure, the field of Explainable AI (XAI) has emerged, offering technical methods to demystify black box models and make their decisions more transparent and auditable. XAI techniques are a critical tool for regulatory compliance, helping organizations meet their transparency obligations and build trust with users and regulators.
XAI methods can be broadly categorized:
Intrinsic Methods: These involve using models that are inherently interpretable due to their simple structure, such as linear regression or decision trees. While highly transparent, these models often lack the predictive power of more complex architectures, creating a trade-off between interpretability and performance.
Post-Hoc Methods: These techniques are applied to pre-trained, complex models to provide explanations for their outputs. They are model-agnostic, meaning they can be used with any type of model. Prominent examples include:
LIME (Local Interpretable Model-agnostic Explanations): Explains individual predictions by creating a simpler, interpretable model that approximates the behavior of the complex model in the local vicinity of that specific prediction.
SHAP (Shapley Additive exPlanations): Based on game theory, SHAP assigns each feature an importance value for a particular prediction, showing how much each input contributed to the final output.
While XAI provides essential tools, it is not a silver bullet. Legal experts participating in focus studies have found that many current XAI outputs are hard to understand and lack sufficient information to be truly "meaningful" for a non-expert user. Furthermore, an explanation generated by a post-hoc method is an approximation of the model's logic, not a perfect representation, which raises questions about its reliability for legal accountability. The ultimate challenge remains to bridge the gap between what is technically explainable and what is legally and ethically meaningful to the individual affected by the decision.
Section 5: Algorithmic Bias, Fairness, and Non-Discrimination
Beyond legal compliance with GDPR's fairness principle, the deployment of AI systems raises profound ethical questions about algorithmic bias and justice. AI models, trained on historical data, can inadvertently learn, codify, and even amplify existing societal biases, leading to discriminatory outcomes in critical areas like hiring, lending, and healthcare. Addressing this challenge requires a proactive, multi-faceted approach that integrates technical solutions with robust organizational governance.
A Typology of Algorithmic Bias
Bias can creep into an AI system at multiple stages of its lifecycle. Understanding the different sources of bias is the first step toward mitigating it.
Data Bias: This is the most common source of bias and arises from the data used to train the model.
Historical Bias: Occurs when the data reflects past prejudices and societal inequalities. For example, Amazon's recruiting AI, trained on a decade of predominantly male résumés, learned to penalize female candidates.
Sample/Selection Bias: Arises when the training data is not representative of the real-world population the model will be deployed on. A facial recognition system trained primarily on light-skinned faces will perform poorly on darker-skinned individuals.
Measurement Bias: Results from inconsistencies or errors in how data is collected or measured across different groups. A healthcare algorithm that used cost of care as a proxy for health needs falsely concluded that Black patients were healthier because they historically had lower healthcare expenditures due to unequal access to care.
Label Bias: Stems from inaccuracies or stereotypes in the labels applied to data by human annotators.
Algorithmic Bias: This bias is introduced by the model itself or the choices made by its developers. It can occur if the model's objective function is flawed or if it optimizes for a narrow definition of accuracy that ignores fairness considerations across different demographic groups.
Human/Confirmation Bias: This occurs during the interaction between humans and the AI system. Decision-makers may interpret the AI's output through the lens of their own biases or over-rely on the system's recommendations, a phenomenon known as automation bias.
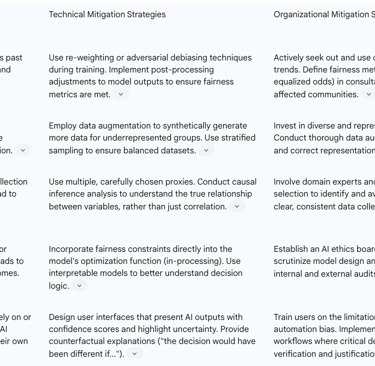
Mitigation Strategies: A Technical and Organizational Approach
Mitigating bias is not a purely technical problem to be solved with a better algorithm; it is a complex sociotechnical challenge that requires a holistic strategy. The goal is not to achieve a mythical state of perfect "de-biasing" but to actively manage and reduce unfairness through a combination of technical tools and organizational change.
The following table outlines a typology of common biases and maps them to corresponding mitigation strategies.

A cornerstone of effective bias mitigation is fostering diversity within the teams that build and govern AI systems. Homogeneous teams are more likely to have blind spots that lead to biased designs. By bringing together individuals from different backgrounds, disciplines (including computer science, law, and social sciences), and with diverse lived experiences, organizations can build a culture of critical self-reflection that is essential for developing equitable AI. This approach, championed by research communities like FAccT (Fairness, Accountability, and Transparency), moves beyond a compliance-only mindset toward a genuine commitment to responsible innovation.
Section 6: The Paradox of Data: AI's Data Hunger vs. GDPR's Data Minimization
A fundamental and persistent conflict exists between the operational needs of modern AI and a core tenet of EU data protection law. Many state-of-the-art machine learning models, particularly in fields like generative AI, are "data hungry"—their performance, accuracy, and nuance improve significantly with the volume and variety of data they are trained on. This reality clashes directly with the GDPR's principle of data minimization, which mandates that organizations collect and process only the personal data that is strictly necessary for a specific, defined purpose.
This tension is not merely theoretical; it creates practical dilemmas throughout the AI lifecycle. During development, there is a strong incentive to collect vast datasets, often through methods like web scraping, to build more powerful models. However, this practice raises immediate questions about necessity and proportionality under GDPR. If a model is trained on a massive, undifferentiated corpus of text from the internet, it is almost certain to contain personal data that is not strictly necessary for any single, specific application of that model.
Regulatory authorities have begun to provide nuanced guidance on this issue. The French DPA, the CNIL, has clarified that the principle of data minimization does not constitute an outright ban on using large datasets for AI training. Instead, it imposes a duty of diligence. Organizations must be able to justify why a large dataset is necessary and must take active steps to select and clean the data to avoid the unnecessary processing of personal data. This implies a shift from a mindset of "collect everything" to one of "collect what is justifiably needed and filter out the rest." Similarly, the EDPB has emphasized that when relying on legitimate interest as a legal basis for processing, the necessity of the processing must be rigorously demonstrated, and less intrusive means must be considered.
This regulatory stance forces organizations to move beyond simply asserting that "more data is better." They must now perform and document a careful assessment before training begins. This involves:
Defining the Purpose with Specificity: Clearly articulating the capabilities the model is intended to have.
Justifying Data Volume: Providing a rationale for why a large-scale dataset is necessary to achieve that purpose (e.g., to capture linguistic diversity, reduce bias, or handle rare edge cases).
Implementing Data Pruning: Using technical measures to filter and remove personal data that is irrelevant to the training objective before it is ingested by the model.
This paradox highlights a central theme in AI governance: innovation cannot be pursued in a regulatory vacuum. The drive for technological advancement must be balanced against the legal and ethical imperative to protect individual privacy. The solution lies not in abandoning data-intensive methods, but in embedding data protection principles into the very architecture of AI development, ensuring that data collection is purposeful, justified, and as minimal as functionally possible.
Part III: Strategic and Operational Pathways to Compliance and Ethical Governance
Navigating the complex regulatory landscape of AI in the EU requires more than just legal knowledge; it demands the implementation of robust, proactive, and integrated governance structures. Organizations must move from a reactive, compliance-checking posture to a proactive model where privacy and ethics are embedded into the AI lifecycle from its inception. This involves establishing clear governance frameworks, conducting rigorous risk assessments tailored to AI, and strategically leveraging technologies that can enhance privacy.
Section 7: Governance by Design: Integrating Privacy into AI Architecture
The most effective approach to ensuring compliance and ethical AI deployment is to adopt the principles of "Privacy by Design and by Default," as mandated by GDPR Article 25. This means integrating data protection considerations into the earliest stages of AI system development, rather than attempting to retrofit them as an afterthought. This proactive stance is not only a legal requirement but also a strategic imperative that reduces long-term compliance costs and builds stakeholder trust.
Establishing AI Governance Structures
A successful AI governance program requires a cross-functional approach, breaking down silos between legal, compliance, engineering, and product teams. Key components of a robust governance structure include:
A Comprehensive AI Use Policy: The first step is to develop a clear, organization-wide policy that governs the permissible use of AI. This policy should serve as a practical guide for all employees, outlining ethical principles, data protection requirements, and clear boundaries for AI application. It must address data governance (how data is collected, stored, and secured for AI), model explainability, user consent, and risk management procedures.
A Cross-Functional Oversight Committee: Many organizations are establishing an AI Center of Excellence (COE) or an AI Ethics Board. This committee should be composed of representatives from various departments, including legal, privacy, data science, security, and ethics. Its role is to review and approve proposed AI projects, provide guidance on complex ethical questions, and ensure consistency in the application of the AI use policy across the organization.
Defined Roles and Responsibilities: Clear accountability is crucial. Organizations should designate specific individuals or teams with responsibility for AI governance, such as a Data Protection Officer (DPO) with an expanded AI remit, or a dedicated AI Ethics Lead. This ensures that there is clear ownership for monitoring compliance, managing risks, and serving as a point of contact for regulatory inquiries.
Privacy by Design in Practice
Integrating privacy into the AI development lifecycle requires concrete actions at each stage:
Design Phase: Before any code is written, a Privacy Threshold Analysis (PTA) should be conducted to determine if a project involves personal data and is likely to pose a high risk, thereby triggering the need for a full DPIA. This is also the stage to define the system's purpose, assess its necessity and proportionality, and build in mechanisms to facilitate data subject rights from the start.
Data Sourcing and Preparation: Implement data minimization strategies by default. This includes carefully selecting data sources, pruning irrelevant data, and using techniques like anonymization or pseudonymization wherever possible to reduce the privacy footprint.
Model Development: Integrate fairness and bias checks throughout the development process. Document all design choices, data sources, and validation procedures to ensure transparency and accountability.
Deployment and Monitoring: Ensure that privacy settings are enabled by default in any user-facing application. Implement continuous monitoring to detect model drift, performance degradation, or the emergence of new biases over time.
By embedding these practices into standard development workflows, organizations can create a culture where responsible innovation is the default, ensuring that AI systems are not only powerful but also trustworthy and compliant.
Section 8: Proactive Risk Mitigation: The AI-Centric Data Protection Impact Assessment (DPIA)
The Data Protection Impact Assessment (DPIA) is a cornerstone of the GDPR's accountability framework and a critical tool for managing the risks associated with AI systems. Under Article 35 of the GDPR, a DPIA is mandatory for any processing that is "likely to result in a high risk to the rights and freedoms of natural persons". The use of innovative technologies like AI is explicitly listed by regulators, including the ICO, as a criterion that often triggers the need for a DPIA.
A DPIA is not a mere compliance checkbox; it is a structured process designed to systematically identify, analyze, and mitigate data protection risks before a project begins. For AI systems, a standard DPIA must be adapted to address the unique risks posed by algorithmic processing.
Key Components of an AI-Centric DPIA
Based on templates and guidance from authorities like the ICO and the Spelthorne Borough Council, an effective DPIA for an AI system should include the following key steps and components :
Step 1: Identify the Need and Scope:
Project Description: Clearly describe the AI project's aims, the type of processing involved (e.g., profiling, automated decision-making, generative content), and its intended benefits.
Scope of Processing: Detail the nature and sources of the data to be processed. Specify if it includes special category data, the volume of data, the number of individuals affected, and the data retention period.
Step 2: Describe the Data Flows and Processing Context:
Nature of Processing: Map out how data is collected, used, stored, shared, and deleted throughout the AI lifecycle.
Context: Analyze the nature of the relationship with the data subjects. Would they reasonably expect their data to be used in this way? Does the processing involve children or other vulnerable groups?.
Step 3: Assess Necessity and Proportionality:
Lawful Basis: Identify and document the lawful basis for processing under GDPR Article 6 (and Article 9, if special category data is involved).
Purpose Achievement: Critically assess whether the AI processing is necessary to achieve the stated purpose. Is there a less intrusive way to achieve the same outcome?.
Data Minimization: Justify why the specific data points being collected are necessary and how "function creep" (using data for unintended purposes) will be prevented.
Step 4: Identify and Assess AI-Specific Risks: This is the core of the AI-centric DPIA. In addition to standard privacy risks (e.g., data breaches), the assessment must systematically evaluate risks unique to AI:
Bias and Fairness Risks: Assess the risk of the AI system perpetuating or amplifying biases, leading to unfair or discriminatory outcomes. This involves analyzing the training data for representativeness and historical biases.
Transparency and Explainability Risks: Evaluate the "black box" risk. If the model is opaque, how will the organization provide meaningful explanations for its decisions to individuals and regulators?.
Accuracy and Robustness Risks: Assess the risk of the AI producing inaccurate or unreliable outputs and the potential harm this could cause.
Security Risks: Analyze vulnerabilities specific to AI models, such as data poisoning or adversarial attacks.
Autonomy Risks: Consider the risks associated with the level of autonomy of the AI, particularly in automated decision-making contexts, and the potential for unforeseen consequences.
Step 5: Identify Mitigation Measures:
For each identified risk, document the specific measures that will be taken to reduce or eliminate it. This could include technical measures (e.g., implementing XAI tools, using PETs), organizational measures (e.g., establishing human oversight procedures, training staff), and legal measures (e.g., clear contractual terms with vendors).
Step 6: Sign-off and Integration:
The DPIA must be reviewed and signed off by relevant stakeholders, including the DPO. The DPO's advice and the decisions taken in response must be recorded. If the DPIA identifies a high residual risk that cannot be mitigated, the organization is legally required to consult with the supervisory authority (e.g., the ICO) before commencing the processing.
By conducting a thorough, AI-centric DPIA, organizations can proactively address potential harms, demonstrate accountability, and build a solid foundation for trustworthy AI deployment.
Section 9: The Role of Privacy-Enhancing Technologies (PETs)
As organizations grapple with the tension between data-intensive AI innovation and stringent privacy obligations, Privacy-Enhancing Technologies (PETs) have emerged as a crucial set of tools. PETs are a family of technologies designed to minimize personal data use, maximize data security, and empower individuals with greater control over their information. When integrated thoughtfully, they can help operationalize the principles of Data Protection by Design and by Default, enabling beneficial data analysis while mitigating privacy risks.
Key PETs for AI Compliance
Several PETs are particularly relevant for building privacy-preserving AI systems:
Federated Learning: This decentralized machine learning approach allows an AI model to be trained across multiple devices or servers without the raw data ever leaving its original location. Instead of centralizing data, only aggregated, anonymized model updates are sent to a central server to improve a global model. This inherently supports the principles of data minimization and purpose limitation. For example, Google uses federated learning to improve its Gboard keyboard predictions by training models locally on users' phones without collecting their sensitive text messages. This approach is especially valuable in sensitive sectors like healthcare, where multiple hospitals could collaborate to train a diagnostic model without sharing confidential patient records.
Differential Privacy: This is a mathematical framework for adding carefully calibrated statistical "noise" to a dataset's outputs. The noise is significant enough to make it impossible to determine whether any single individual's data was included in the computation, thus protecting individual privacy, while being minimal enough to preserve the overall statistical accuracy of the aggregate results. Apple, for instance, uses differential privacy to gather usage insights from its users' devices to improve services without accessing their personal data.
Homomorphic Encryption: This advanced cryptographic technique allows for computations to be performed directly on encrypted data without ever decrypting it. An AI model could, in theory, be trained on an encrypted dataset, ensuring that the underlying sensitive information is never exposed, even to the party performing the analysis. This offers a very high level of security, though it is computationally intensive.
Synthetic Data: This involves creating an entirely artificial dataset that mimics the statistical properties and patterns of a real dataset. AI models can then be trained on this synthetic data without using any real personal information, which can be a powerful tool for testing and development while minimizing privacy risks.
The Limitations and Challenges of PETs
Despite their immense potential, PETs are not a panacea for all privacy challenges and come with significant limitations and trade-offs.
Utility vs. Privacy Trade-off: There is often an inherent trade-off between the level of privacy protection and the utility of the data. For example, adding too much noise in differential privacy can degrade the accuracy of the AI model, potentially rendering it useless for its intended purpose. Similarly, synthetic data may not perfectly capture all the complex nuances and outliers of the original data, which can affect model performance.
Complexity and Expertise: Implementing PETs correctly requires a high level of specialized technical and cryptographic expertise. A flawed implementation can create a false sense of security while providing little actual protection, or even introduce new vulnerabilities.
Computational Overhead: Advanced PETs like fully homomorphic encryption and secure multi-party computation are extremely computationally expensive. This can make them impractical for large-scale, real-time AI applications due to high costs and slow processing times.
Not a "Silver Bullet": PETs address specific privacy risks but do not solve all ethical issues. For instance, federated learning reduces the risk of data breaches by keeping data local, but it does not inherently address the issue of algorithmic bias if the local datasets themselves are biased. PETs should be viewed as one component of a comprehensive risk mitigation strategy, not a standalone solution.
Consolidation of Power: The development and deployment of the most advanced PETs often require vast computational resources and expertise, which are primarily available to large technology companies. This creates a risk that PETs could be used to further entrench the market dominance of these players, allowing them to conduct large-scale data analysis under the guise of privacy protection while smaller competitors are left behind.
Ultimately, the strategic deployment of PETs requires a careful, case-by-case assessment of the specific risks, the desired utility, and the available resources. They are powerful tools in the privacy engineer's toolkit, but they must be wielded with a clear understanding of their limitations and as part of a broader ethical and governance framework.
Part IV: Enforcement, Liability, and the Future Outlook
The robust legal frameworks of the GDPR and the EU AI Act are not merely theoretical constructs; they are backed by a formidable enforcement machinery with the power to levy significant financial penalties and mandate operational changes. Understanding the enforcement landscape—including the guidance issued by data protection authorities (DPAs), the precedents set by enforcement actions, and the cooperative mechanisms between regulators—is essential for any organization operating in the EU.
Section 10: The Regulatory Gaze: DPA Guidance and Enforcement Precedents
European data protection authorities have been actively interpreting how GDPR applies to AI, issuing guidance and taking enforcement action that provides crucial insights into regulatory expectations. The European Data Protection Board (EDPB), which comprises representatives from all national DPAs, plays a key role in ensuring a consistent application of the law, while influential national authorities like France's CNIL and the UK's ICO provide more detailed, practical guidance.
Key DPA Guidance on AI
Recent guidance from European DPAs has focused on clarifying some of the most contentious issues at the intersection of AI and data protection:
Lawful Basis for Training: In a highly anticipated opinion in December 2024, the EDPB confirmed that "legitimate interest" can be a valid lawful basis for processing personal data to train AI models. However, it set a high bar, requiring organizations to conduct and document a rigorous three-part balancing test: demonstrating a real and non-speculative legitimate interest, proving the processing is strictly necessary, and ensuring the rights and freedoms of individuals are not overridden. The EDPB and ICO have both stressed that the reasonable expectations of data subjects are a key factor, and that simply because data is publicly available (e.g., via web scraping) does not give organizations a blank check to use it.
Anonymity of AI Models: The EDPB has adopted a narrow interpretation of when an AI model can be considered truly anonymous and thus outside the scope of GDPR. A model is only anonymous if the risk of re-identifying an individual from its outputs is negligible. This assessment must be done on a case-by-case basis, and the burden of proof is on the controller. The fact that personal data may remain "absorbed" in a model's parameters means that many models will likely be considered to be processing personal data, even after training is complete.
Purpose Limitation and Fairness: The CNIL has provided pragmatic guidance, acknowledging that the purpose for a general-purpose AI cannot be fully specified at the training stage. It allows for a more flexible description of the type of system being developed. The ICO has updated its guidance to focus heavily on fairness, providing detailed considerations for evaluating and mitigating bias throughout the AI lifecycle and clarifying the link between fairness and the accuracy of AI outputs.
Landmark Enforcement Actions
Enforcement actions provide the most concrete evidence of regulatory priorities and the tangible risks of non-compliance. Several high-profile cases have underscored the seriousness with which DPAs are treating AI-related GDPR violations.
The following table summarizes key enforcement actions, illustrating the types of violations being targeted and the significant penalties being imposed.
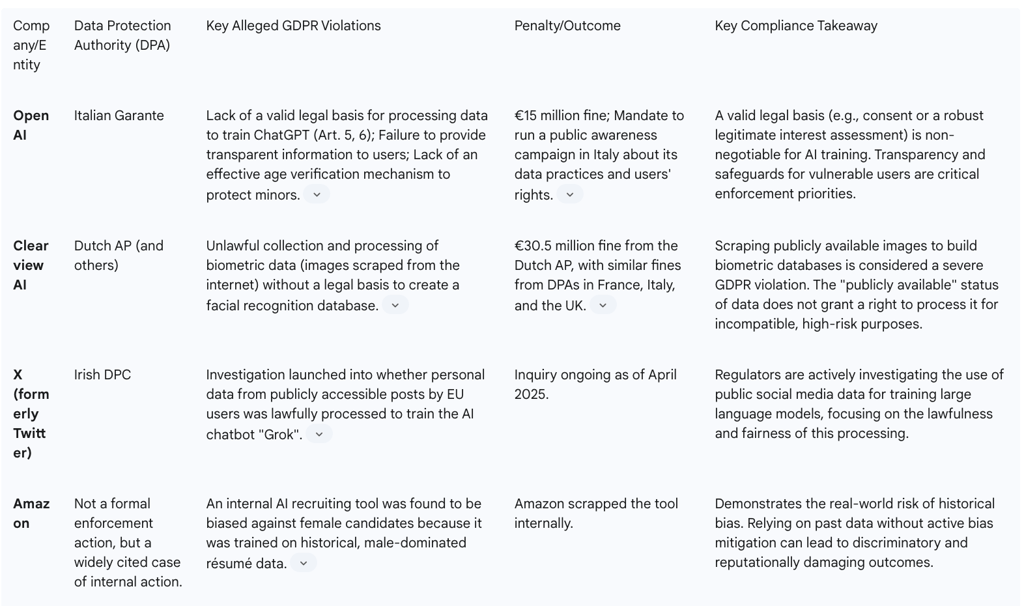
These cases demonstrate a clear regulatory focus on the foundational principles of GDPR: lawfulness, fairness, and transparency. They show that DPAs are willing to impose multi-million euro fines and are scrutinizing the entire AI supply chain, from data collection and training to deployment.
Section 11: The Enforcement Machinery: Cooperation and Sanctions
The enforcement of the EU's AI rules involves a complex interplay between new and existing regulatory bodies. The AI Act establishes a new enforcement structure, while the GDPR's established network of DPAs continues to hold authority over data protection matters. The effectiveness of this dual system will depend heavily on the cooperation between these authorities.
The AI Act's Enforcement Structure
The AI Act creates a multi-tiered enforcement system combining national and EU-level oversight :
National Market Surveillance Authorities (MSAs): Each Member State must designate one or more MSAs responsible for supervising the AI Act's implementation on their territory. These authorities will have the power to conduct investigations, request access to documentation and even source code, and impose corrective measures and fines.
The EU AI Office: Housed within the European Commission, the AI Office has a central role. It has exclusive enforcement powers over providers of general-purpose AI models. It also supports the national MSAs, develops guidelines, and fosters the development of trustworthy AI across the Union.
The European AI Board: Composed of representatives from each Member State's MSA, the AI Board's role is to advise the Commission and facilitate the consistent application of the Act across the EU, similar to the role the EDPB plays for the GDPR.
Cooperation between AI Regulators and DPAs
A critical feature of the new landscape is the mandated cooperation between AI-specific regulators and data protection authorities. The AI Act explicitly recognizes that many AI risks are intertwined with data protection.
DPA Designation as MSAs: The AI Act allows and, in some cases, encourages Member States to designate their national DPA as the MSA, particularly for high-risk systems that process biometric data or are used in law enforcement and the administration of justice. This leverages the existing expertise of DPAs in handling fundamental rights issues.
Mandatory Cooperation: Where the MSA is a separate body, the AI Act mandates that it must inform and cooperate with the relevant DPA whenever an investigation touches upon fundamental rights related to personal data protection.
Joint Investigations and Shared Information: The framework provides for joint investigations and information sharing between authorities to ensure a holistic approach to enforcement. The AI Board will serve as a platform to coordinate these efforts.
This cooperative model means that organizations deploying AI systems may find themselves interacting with multiple regulators. An issue could trigger a parallel investigation by both the MSA (for AI Act compliance) and the DPA (for GDPR compliance). While the AI Act includes provisions to prevent double jeopardy for the same infringement, the potential for cumulative sanctions and a complex, multi-authority regulatory process is a significant new reality for compliance teams.
Section 12: Strategic Recommendations for Responsible Innovation
Navigating the intricate and evolving landscape of AI regulation in the EU requires a strategic, proactive, and ethically grounded approach. Organizations that view compliance merely as a legal hurdle to be cleared will likely fail. In contrast, those that embed principles of privacy, fairness, and safety into their core innovation processes will not only mitigate risk but also build the stakeholder trust necessary for long-term success. The following recommendations provide a strategic roadmap for balancing innovation with protection.
Adopt a Unified Governance Framework: Do not treat GDPR and AI Act compliance as separate silos. Create a single, integrated AI governance framework that addresses both data protection and AI safety requirements. This should be led by a cross-functional committee—including legal, privacy, data science, engineering, and ethics—that oversees the entire AI lifecycle. This unified approach prevents duplication of effort, ensures consistency, and allows for a holistic assessment of risk.
Prioritize Lifecycle-Based Risk Assessment: Shift from a static, one-time compliance check to a dynamic, lifecycle-based risk management process. Implement a stage-gate system where every AI project undergoes a formal review and risk assessment at critical junctures: ideation, data sourcing, model training, pre-deployment, and post-deployment monitoring. Use an AI-centric DPIA as the core tool for this process, ensuring it systematically evaluates risks of bias, opacity, and security alongside traditional privacy concerns.
Make Explainability a Core Design Requirement: The "black box" is no longer a viable excuse for a lack of transparency. Mandate that development teams prioritize interpretability from the outset. For high-risk or high-impact decisions, this may mean choosing intrinsically interpretable models over more complex but opaque ones. For all systems, invest in and implement robust XAI tools and, crucially, develop processes to translate their technical outputs into explanations that are genuinely meaningful and understandable to non-expert users and regulators.
Operationalize Fairness and Bias Mitigation: Move beyond acknowledging the risk of bias to actively operationalizing fairness. This requires three key actions:
Invest in Diverse Data and Teams: Proactively seek and curate diverse, representative datasets. Foster diversity in your AI development and governance teams to challenge assumptions and identify blind spots.
Define and Measure Fairness: Establish clear, context-specific fairness metrics for your AI systems before deployment. These metrics should be developed in consultation with domain experts, ethicists, and representatives of affected communities.
Audit and Iterate: Conduct regular, rigorous audits for bias and fairness. Treat fairness not as a one-time fix but as an ongoing process of monitoring, evaluation, and iteration.
Strategically Deploy Privacy-Enhancing Technologies (PETs): View PETs not as a compliance panacea but as a strategic toolkit. Conduct a careful cost-benefit analysis for each use case, weighing the privacy gains of technologies like federated learning or differential privacy against their potential trade-offs in accuracy, cost, and computational overhead. Use PETs as part of a layered defense to operationalize data minimization, but do not allow them to create a false sense of security that masks underlying ethical issues.
Embrace Radical Transparency: In an environment of increasing public and regulatory scrutiny, the default posture should be transparency. Be clear and upfront with users about when they are interacting with an AI system. Provide accessible, easy-to-understand privacy notices that explain in simple terms how their data is being used to train and operate AI models. Document and be prepared to defend your legitimate interest assessments and risk mitigation strategies.
By adopting these strategic recommendations, organizations can transform the challenge of regulatory compliance into an opportunity. They can build AI systems that are not only innovative and powerful but also safe, fair, and worthy of the trust of their users and society at large. This is the mandate for responsible leadership in the algorithmic age.
FAQ
1. What are the two primary legal frameworks governing AI deployment in the EU, and how do they interact?
The deployment of Artificial Intelligence (AI) systems within the European Union is principally governed by two evolving legal frameworks: the General Data Protection Regulation (GDPR) and the EU AI Act. The GDPR provides the foundational legal framework for any AI system that processes personal data, focusing on the protection of individual rights and data privacy. Its core principles, such as lawfulness, fairness, transparency, purpose limitation, and data minimisation, apply throughout the entire AI lifecycle.
Complementing this, the EU AI Act introduces a product-safety-oriented, risk-based approach to the regulation of AI technologies themselves. It categorises AI systems into different risk levels (unacceptable, high, limited, and minimal), with the most stringent obligations placed on high-risk systems that could pose significant harm to health, safety, or fundamental rights.
While distinct in their primary goals – GDPR on data protection and AI Act on product safety – they are designed to be complementary. Many AI systems process personal data, meaning both regulations often apply simultaneously. An organisation can be both a "data controller" under GDPR and a "provider" or "deployer" under the AI Act, with overlapping obligations. This dual framework creates a "Brussels Effect," setting a comprehensive global standard for trustworthy AI. Organisations can leverage compliance synergies, as requirements for accountability, documentation, risk assessments (like GDPR's DPIA and the AI Act's conformity assessments), fairness, and human oversight often align between the two.
2. How do GDPR's core principles apply to the AI lifecycle, and what challenges do they present?
GDPR's core principles apply with full force across the entire AI lifecycle, from data sourcing and model training to deployment and ongoing operation. However, the unique characteristics of AI — its data-intensive nature, probabilistic outputs, and potential for opacity — create significant compliance challenges:
Lawfulness, Fairness, and Transparency: AI systems must have a clear legal basis for processing data. Transparency is particularly challenging given the complexity of many AI models, making it difficult to explain their internal logic to individuals.
Purpose Limitation: Data must be collected for "specified, explicit, and legitimate purposes." This clashes with the development of general-purpose AI models, where future applications cannot always be foreseen.
Data Minimisation: Processing should be limited to what is "adequate, relevant and necessary." This directly conflicts with the "data hungry" nature of many machine learning models, which often perform better with larger datasets.
Accuracy: This applies not only to input data but also to the inferences and predictions generated by the AI model, as inaccurate training data can lead to biased outputs.
Storage Limitation: Limits how long AI training datasets containing personal data can be retained.
Integrity and Confidentiality: Requires robust cybersecurity measures for AI systems and the data they handle.
Accountability: Data controllers must be able to demonstrate compliance through comprehensive documentation and risk assessments.
Furthermore, compliance obligations evolve as an AI system moves through its lifecycle; for instance, the legal basis for training a model may differ from that required for its deployment. Data subject rights (e.g., access, rectification, erasure, objection, and rights related to automated decision-making) also apply fully, yet their technical implementation in AI (e.g., "unlearning" data from a trained model) can be profoundly difficult, reinforcing the need for "Privacy by Design."
3. What is the "black box" dilemma in AI, and how does the "right to explanation" address it in the EU?
The "black box" dilemma refers to the opacity of complex AI models, particularly deep neural networks, whose internal decision-making processes are not easily interpretable by humans. This inherent opacity directly conflicts with the GDPR's principles of transparency and accountability, particularly concerning automated decision-making.
While the GDPR does not contain an explicit, standalone "right to explanation," the concept is derived from a combination of provisions, notably Articles 13, 14, and 15 (information rights), and Article 22 (rights related to automated decision-making). These provisions require data controllers to provide "meaningful information about the logic involved, as well as the significance and the envisaged consequences" of automated decisions, and the right to obtain human intervention and contest the decision.
A landmark decision by the Court of Justice of the European Union (CJEU) on 27 February 2025 confirmed a "right of explanation," ruling that the complexity of an algorithm does not absolve the controller of the duty to "translate" its logic into understandable terms for non-experts. This necessitates providing clear, concise, and accessible explanations, potentially using infographics or criteria-based rationales, rather than complex technical details. Explainable AI (XAI) techniques, such as LIME and SHAP, have emerged to help demystify these models, though challenges remain in ensuring these explanations are truly "meaningful" and legally reliable for affected individuals.
4. What are the main types of algorithmic bias, and how can organisations mitigate them?
Algorithmic bias occurs when AI models, often trained on historical data, inadvertently learn and amplify societal prejudices, leading to discriminatory outcomes. Understanding the sources of bias is crucial for mitigation:
Data Bias: This is the most common source, arising from the data used for training.
Historical Bias: Reflects past societal inequalities (e.g., an HR AI biased against women due to male-dominated training data).
Sample/Selection Bias: Occurs when training data isn't representative of the real-world population (e.g., facial recognition systems performing poorly on darker skin tones).
Measurement Bias: Results from inconsistencies or errors in data collection across different groups (e.g., using cost of care as a proxy for health needs, leading to skewed outcomes for certain demographics).
Label Bias: Stems from inaccuracies or stereotypes in human-applied data labels.
Algorithmic Bias: Introduced by the model's design, objective function, or optimisation choices that overlook fairness.
Human/Confirmation Bias: Arises from human interpretation of AI outputs, leading to over-reliance or selective interpretation.
Mitigating bias requires a holistic, socio-technical approach:
Technical Strategies: Re-weighting or adversarial debiasing during training, post-processing adjustments, data augmentation, stratified sampling, incorporating fairness constraints into model optimisation, and using interpretable models.
Organizational Strategies: Actively seeking diverse and representative datasets, defining clear fairness metrics (e.g., demographic parity) in consultation with ethicists and affected communities, investing in diverse development teams, conducting thorough data audits, establishing AI ethics boards or review committees, mandating regular fairness audits, and training users on AI limitations and automation bias.
The goal is continuous management and reduction of unfairness, moving beyond a compliance-only mindset towards responsible innovation.
5. What is the "paradox of data" in AI governance, and how are regulators addressing it?
The "paradox of data" describes the fundamental conflict between the operational needs of modern AI and the GDPR's principle of data minimisation. Many state-of-the-art AI models, especially generative AI, are "data hungry" – their performance, accuracy, and nuance improve significantly with larger volumes and varieties of training data. This clashes directly with the GDPR's mandate that organisations collect and process only the personal data strictly necessary for a specific, defined purpose.
This tension creates practical dilemmas, as the incentive to collect vast datasets (e.g., via web scraping) for more powerful models raises immediate questions about necessity and proportionality. Regulators are addressing this by clarifying that data minimisation does not outright ban large datasets but imposes a "duty of diligence."
Organisations must:
Justify Data Volume: Provide a clear rationale for why a large-scale dataset is necessary to achieve the defined purpose (e.g., capturing linguistic diversity, reducing bias).
Define Purpose with Specificity: Clearly articulate the model's intended capabilities.
Implement Data Pruning: Use technical measures to filter and remove irrelevant personal data before ingestion.
This approach requires a shift from "collect everything" to "collect what is justifiably needed and filter out the rest," ensuring that innovation is balanced against the imperative to protect individual privacy by embedding data protection principles into the very architecture of AI development.
6. How can organisations integrate privacy and ethics into AI architecture through "Governance by Design"?
"Governance by Design," specifically adopting "Privacy by Design and by Default" (mandated by GDPR Article 25), means embedding data protection and ethical considerations into the earliest stages of AI system development rather than retrofitting them later. This proactive stance is both a legal requirement and a strategic imperative for building trust and reducing compliance costs.
Key steps for integrating privacy and ethics by design include:
Establishing AI Governance Structures:
Comprehensive AI Use Policy: Develop an organisation-wide policy outlining ethical principles, data protection requirements, and clear boundaries for AI application (e.g., data governance, explainability, consent, risk management).
Cross-Functional Oversight Committee: Establish an AI Centre of Excellence or AI Ethics Board with representatives from legal, privacy, data science, security, and ethics to review and approve AI projects and provide guidance.
Defined Roles and Responsibilities: Designate specific individuals or teams (e.g., an expanded DPO role, an AI Ethics Lead) with clear accountability for AI governance.
Implementing Privacy by Design in Practice at Each Stage:
Design Phase: Conduct a Privacy Threshold Analysis (PTA) early to assess personal data involvement and risk, triggering a Data Protection Impact Assessment (DPIA) where necessary. Define purpose, necessity, and proportionality, and build in mechanisms for data subject rights.
Data Sourcing and Preparation: Implement data minimisation by default through careful selection, pruning irrelevant data, and using anonymisation or pseudonymisation.
Model Development: Integrate fairness and bias checks throughout, documenting design choices, data sources, and validation procedures for transparency.
Deployment and Monitoring: Ensure privacy settings are default, and implement continuous monitoring for model drift, performance degradation, or new biases.
This approach fosters a culture where responsible innovation is the default, ensuring AI systems are powerful, trustworthy, and compliant.
7. What is an AI-centric Data Protection Impact Assessment (DPIA), and why is it crucial for AI systems?
A Data Protection Impact Assessment (DPIA) is a mandatory cornerstone of the GDPR's accountability framework (Article 35) for processing "likely to result in a high risk to the rights and freedoms of natural persons." The use of innovative technologies like AI explicitly triggers the need for a DPIA.
An AI-centric DPIA is not a mere checkbox but a structured, proactive process to identify, analyse, and mitigate data protection risks specific to algorithmic processing before an AI project begins. It extends a standard DPIA to address the unique challenges of AI:
Key Components of an AI-Centric DPIA:
Identify the Need and Scope: Clearly describe the AI project's aims, type of processing (e.g., profiling, automated decision-making), intended benefits, and the nature and volume of data to be processed, including any special category data.
Describe Data Flows and Processing Context: Map how data is collected, used, stored, shared, and deleted throughout the AI lifecycle, considering data subjects' reasonable expectations and vulnerability.
Assess Necessity and Proportionality: Document the lawful basis, critically assess if the AI processing is necessary for the stated purpose (considering less intrusive means), and justify data minimisation.
Identify and Assess AI-Specific Risks: Beyond standard privacy risks, evaluate:
Bias and Fairness Risks: Analysing training data for representativeness and historical biases.
Transparency and Explainability Risks: Addressing the "black box" problem and how meaningful explanations will be provided.
Accuracy and Robustness Risks: Potential harm from inaccurate or unreliable outputs.
Security Risks: Vulnerabilities specific to AI models (e.g., data poisoning).
Autonomy Risks: Potential for unforeseen consequences from AI's level of autonomy.
Identify Mitigation Measures: For each risk, document specific technical (e.g., XAI, PETs), organisational (e.g., human oversight, training), and legal measures.
Sign-off and Integration: The DPO must review and sign off, with advice recorded. If high residual risk remains unmitigated, consultation with the supervisory authority is legally required before processing commences.
By conducting a thorough, AI-centric DPIA, organisations proactively address potential harms, demonstrate accountability, and build a solid foundation for trustworthy AI deployment.
8. What are Privacy-Enhancing Technologies (PETs), and what role do they play in AI compliance?
Privacy-Enhancing Technologies (PETs) are a family of technologies designed to minimise personal data use, maximise data security, and empower individuals with greater control over their information. They are crucial tools for operationalising "Data Protection by Design and by Default" in AI, enabling beneficial data analysis while mitigating privacy risks.
Key PETs relevant for AI compliance include:
Federated Learning: Decentralised machine learning where models are trained locally on devices without raw data leaving its source. Only aggregated, anonymised model updates are sent to a central server. This inherently supports data minimisation and purpose limitation.
Differential Privacy: A mathematical framework that adds carefully calibrated statistical "noise" to data outputs, making it impossible to identify individual contributions while preserving overall statistical accuracy.
Homomorphic Encryption: Allows computations to be performed directly on encrypted data without decryption, ensuring sensitive information is never exposed during AI training or processing.
Synthetic Data: Creating artificial datasets that mimic the statistical properties of real data, allowing AI models to be trained without using any actual personal information.
While offering immense potential, PETs are not a panacea. They involve a utility vs. privacy trade-off (more privacy might mean less accuracy), require specialised expertise for correct implementation, often incur significant computational overhead, and are not a "silver bullet" for all ethical issues (e.g., they don't inherently address algorithmic bias if underlying data is biased). Furthermore, their development often requires vast resources, potentially consolidating power among large tech companies. Strategic deployment of PETs requires careful case-by-case assessment of risks, desired utility, and available resources, as part of a broader ethical and governance framework.