ChatGPT's data usage and GDPR compliance
ChatGPT's approach to data usage and adherence to GDPR compliance is of utmost importance. By utilizing data effectively, businesses can unlock new insights and opportunities that can help drive growth. However, ensuring that this data is handled responsibly and securely is where GDPR compliance comes into play.


The European Union’s General Data Protection Regulation (GDPR) represents the most comprehensive and stringent data protection framework globally. Its enforcement has profound implications for the development and deployment of data-intensive technologies, none more so than generative artificial intelligence (AI) and Large Language Models (LLMs) like OpenAI's ChatGPT. An analysis of OpenAI's operations through the lens of the GDPR reveals not merely a set of compliance hurdles to be cleared, but fundamental, structural tensions between the current architecture of LLMs and the foundational principles of European data protection law. These principles are not aspirational guidelines; they are legally binding requirements, and failure to adhere to them can result in severe financial penalties, including administrative fines of up to €20 million or 4% of a company's total worldwide annual turnover, whichever is higher.
The Seven Principles as a Benchmark for AI Systems
Article 5 of the GDPR establishes seven core principles that must govern all processing of personal data. These principles serve as the essential benchmark against which the lawfulness of any data processing activity, including those performed by AI systems, is measured. They are:
Lawfulness, fairness, and transparency: Personal data must be processed lawfully, fairly, and in a transparent manner in relation to the data subject.
Purpose limitation: Data must be collected for specified, explicit, and legitimate purposes and not be further processed in a manner that is incompatible with those purposes.
Data minimisation: Data processing must be adequate, relevant, and limited to what is necessary in relation to the purposes for which it is processed.
Accuracy: Personal data must be accurate and, where necessary, kept up to date; every reasonable step must be taken to ensure inaccurate data is erased or rectified without delay.
Storage limitation: Data must be kept in a form which permits identification of data subjects for no longer than is necessary for the purposes for which the data are processed.
Integrity and confidentiality: Data must be processed in a manner that ensures appropriate security, including protection against unauthorized or unlawful processing and accidental loss, destruction, or damage.
Accountability: The data controller is responsible for, and must be able to demonstrate compliance with, all of the preceding principles.
These principles are not independent silos but form an interconnected framework. For an organization like OpenAI, demonstrating compliance requires a holistic approach that addresses each principle throughout the entire data lifecycle, from the initial collection of training data to the generation of output for an end-user.
Inherent Tensions: The Collision of "Data Minimisation" with "Large" Language Models
A primary point of friction arises between the principle of data minimisation and the fundamental design of LLMs. The GDPR mandates that personal data collected must be "adequate, relevant and limited to what is necessary" for the stated purpose. This principle is a cornerstone of privacy by design, intended to limit an organization's data footprint and reduce the potential harm from a data breach.
Conversely, the efficacy and power of models like ChatGPT are predicated on being trained on vast quantities of information. OpenAI itself states that the first stage of its model training involves learning from "a large amount of data," including public sources and licensed third-party data. The very name "Large Language Model" signals a technological paradigm that appears to be in direct opposition to the legal principle of minimisation. This has become a significant concern for regulators and privacy advocates, who question whether the indiscriminate scraping and processing of immense internet datasets, which inevitably include personal and even sensitive personal data, can ever be considered "limited to what is necessary". The legal question this tension raises is profound: is the processing of billions of data points, including personal information of individuals who have no relationship with OpenAI, truly necessary to achieve the purpose of creating a conversational AI, or does it represent an excessive and therefore unlawful collection of data?
The Crux of "Lawful Basis": Distinguishing Between Model Training and Service Provision
Under Article 6 of the GDPR, all processing of personal data must be justified by one of six lawful bases, such as consent, contractual necessity, or legitimate interests. The Italian data protection authority, the Garante, centered its investigation on this very point, concluding that OpenAI lacked an "adequate legal basis" for the mass processing of personal data used to train its algorithms.
This highlights a critical distinction between two separate processing activities: providing the ChatGPT service to a user and training the underlying model. When a user signs up for ChatGPT, the processing of their account information and prompts to provide a response can be justified under "contractual necessity." However, the use of that same data, or data scraped from the internet, for the secondary purpose of training and improving the model is a separate processing activity that requires its own distinct lawful basis.
OpenAI's approach to this has been reactive. Following the Garante's intervention, which noted the absence of a valid legal basis, OpenAI updated its policies to clarify that the processing for training algorithms is based on "legitimate interest". Relying on legitimate interests requires the data controller to conduct a balancing test, weighing its commercial interests against the fundamental rights and freedoms of the data subjects. European regulators have consistently taken the view that this balance is difficult to strike when the processing is opaque, involves vast quantities of personal data from non-users, and carries significant risks to individual rights. The Garante's findings suggest that, at least for the initial training phase, OpenAI's balancing test failed.
The "Accuracy" Principle in an Era of AI "Hallucination"
Perhaps the most intractable conflict between the GDPR and current LLM technology lies with the principle of accuracy. Article 5(1)(d) of the GDPR is unequivocal: personal data must be "accurate," and controllers must take "every reasonable step" to rectify or erase inaccurate data. This principle is directly and systematically challenged by the phenomenon of AI "hallucinations," where a model generates "false or misleading information presented as fact".
When these hallucinations pertain to individuals—fabricating incorrect birth dates, professional histories, or even false criminal accusations—it is not merely a technical glitch but a direct violation of a core data protection principle. This issue forms the central argument of multiple legal complaints filed by the privacy advocacy group noyb (None of Your Business), which has documented instances of ChatGPT generating seriously damaging false information about individuals. The problem is compounded by OpenAI's reported admission that it is technically unable to correct specific pieces of false data within the trained model, a point that noyb has repeatedly emphasized. This inability to comply with the "right to rectification" (Article 16) transforms a technical limitation into a persistent legal liability.
The convergence of these issues demonstrates that the GDPR poses a systemic challenge to the current paradigm of LLM development. The conflict is not with a single feature or policy but with the foundational architecture of scraping vast, unconsented datasets and processing them in a probabilistic manner that cannot guarantee accuracy or facilitate fundamental data subject rights like rectification and erasure. The principle of purpose limitation is challenged when data posted on a public forum is repurposed for the incompatible goal of training a commercial AI. The principle of data minimisation is challenged by the "more is better" ethos of LLM training. The rights to erasure and rectification become technically infeasible once data is amalgamated into a trained model's weights. Consequently, achieving genuine, proactive GDPR compliance may necessitate a fundamental shift in how LLMs are designed, built, and trained—moving away from indiscriminate data collection toward curated, consented, and verifiable data sources.
OpenAI's Data Architecture: A Review of Stated Policies and Technical Controls
To assess OpenAI's GDPR compliance, it is first necessary to establish a baseline of its official policies and technical commitments. OpenAI's data handling practices vary significantly across its different service tiers, creating distinct risk profiles for consumer and business users. The company's public-facing documentation, including its Privacy Policy, Terms of Use, and enterprise-focused materials, outlines its approach to data collection, purpose of use, retention, and security.
Data Collection Across Service Tiers: A Comparative Analysis
OpenAI's data collection practices are bifurcated, with a clear distinction drawn between its consumer-facing services and its offerings for businesses and developers.
Consumer Services (ChatGPT Free and Plus): For users of the free and Plus versions of ChatGPT, OpenAI collects a broad range of data. This includes Account Information (name, contact details, date of birth, payment information), User Content (the prompts, questions, and files users input), Communication Information (emails and other correspondence), and Technical Data (log data such as IP address, browser type, usage data on features used, and location information derived from IP addresses). A critical aspect of this service tier is that User Content is, by default, used to improve OpenAI's services, which includes training its models. Users must proactively opt out of this data use through their settings or by using the "Temporary Chats" feature, which is not used for training.
Business Services (API, ChatGPT Team, Enterprise, and Edu): In stark contrast, a central commitment for OpenAI's business offerings is that it does not use customer data submitted via these platforms to train or improve its models by default. This is a cornerstone of its enterprise compliance narrative. For these services, the customer retains ownership of their inputs and outputs, where allowed by law. This distinction is crucial for organizations seeking to use OpenAI's technology while maintaining control over their proprietary or personal data.
Data for Model Training: Independent of user-submitted content, OpenAI is transparent about the sources used for the initial training of its foundational models. These sources include vast amounts of data from public sources on the internet, licensed third-party datasets, and information created by human reviewers. It is this large-scale collection of publicly accessible data that has become a primary focus of regulatory scrutiny.
Stated Purposes for Data Processing and Use
OpenAI's Privacy Policy enumerates several purposes for which it processes personal data. These include core operational functions such as providing, analyzing, and maintaining its services; communicating with users about service updates and events; preventing fraud and misuse; and complying with legal obligations.
However, the most significant purpose from a GDPR perspective is the one stated as "to improve and develop our Services and conduct research". This broad purpose serves as the justification for using content from consumer services to train the models that power ChatGPT. While users can opt out, the default-in status for this secondary processing purpose is a key area of regulatory concern under the GDPR's purpose limitation principle. OpenAI also states that it may use aggregated or de-identified data for analysis and research, committing not to attempt re-identification unless required by law.
Data Retention, Deletion, and Security Protocols
OpenAI has implemented specific policies for data retention and security, which are essential for complying with the GDPR's principles of storage limitation and integrity and confidentiality.
Retention and Deletion: For its API platform, OpenAI may retain inputs and outputs for up to 30 days for the purposes of abuse and misuse monitoring. After this period, the data is removed from its systems, unless there is a legal requirement for longer retention. For consumer services, users can delete their conversations, and this data is permanently removed from OpenAI's systems within 30 days, again, subject to legal retention obligations. For ChatGPT Enterprise, organizations are given controls to manage how long their data is retained. Furthermore, OpenAI offers a
Zero Data Retention (ZDR) option for eligible API use cases, which means inputs and outputs are not stored at all.
Security Measures: OpenAI details a robust security program designed to protect data. This includes encrypting all data at rest (using AES-256) and in transit (using TLS 1.2 or higher). It employs strict access controls based on zero trust and defense-in-depth principles to limit employee access to customer data. Access by authorized employees is restricted to specific purposes like engineering support, investigating abuse, or legal compliance. The company maintains a 24/7 security team, runs a bug bounty program for responsible vulnerability disclosure, and undergoes regular third-party penetration testing. For its business products and API, OpenAI has achieved SOC 2 Type 2 compliance, an important attestation for enterprise customers.
The Role and Limitations of the Data Processing Addendum (DPA)
For its business customers, OpenAI offers a Data Processing Addendum (DPA), a legally required document under Article 28 of the GDPR for any organization (the "data controller") that engages a third-party service (the "data processor") to process personal data on its behalf.
The DPA contractually obligates OpenAI to follow the customer's instructions when processing their data and to adhere to the requirements of the GDPR. In this arrangement, the customer is legally designated as the Data Controller, and OpenAI (specifically, OpenAI Ireland Ltd. for EU customers) acts as the Data Processor. The availability of a DPA is a critical prerequisite for any company in the EU to lawfully use a service like the OpenAI API to process personal data. However, while the DPA governs the relationship between the customer and OpenAI, its existence does not retroactively cure any underlying compliance issues with the service itself, such as those related to the data used to train the foundational model. Some users have also reported administrative difficulties and delays in executing the DPA with OpenAI, which can pose a roadblock to compliance.
To provide a clear overview of these differing policies, the following table compares the key data handling features across OpenAI's main service tiers. This comparison is a vital tool for any organization's Chief Privacy Officer or Data Protection Officer to assess internal risk and develop appropriate usage policies.
Table 1: OpenAI Service Tiers and Data Handling Policies


This table starkly illustrates the compliance gap between OpenAI's consumer and business offerings. The default use of data for training, coupled with the absence of a DPA for the free and Plus versions, makes their use for processing any corporate or personal data a high-risk activity from a GDPR perspective. This provides a clear rationale for organizations to prohibit the use of consumer-grade tools for business purposes and to channel any approved use cases through the more robustly controlled enterprise and API platforms.
A Principle-by-Principle GDPR Compliance Audit of OpenAI
Evaluating OpenAI's stated policies and technical controls against the rigorous standards of the GDPR's seven principles reveals significant areas of friction and non-compliance. This analysis, informed by the findings of European data protection authorities (DPAs) and the legal challenges brought by privacy advocates, moves beyond a review of documentation to a critical assessment of OpenAI's practices in the real world.
Lawfulness, Fairness, and Transparency
Lawfulness: The GDPR requires that all data processing have a valid legal basis. The Italian Garante's investigation concluded that OpenAI's "massive collection of personal data" for the purpose of training its algorithms lacked such a basis. OpenAI's subsequent reliance on "legitimate interests" for this processing remains contentious. A legitimate interest balancing test requires that the controller's interests are not overridden by the fundamental rights and freedoms of individuals. Given the scale of data scraping, the lack of a relationship with many of the data subjects, and the potential for harm from inaccurate outputs, regulators are likely to find that this balance tips in favor of the individual, making the processing unlawful.
Fairness: The principle of fairness requires that data is not processed in a way that is unduly detrimental, unexpected, or misleading to individuals. The European Data Protection Board (EDPB) task force has noted that because ChatGPT's outputs are often perceived as factually correct, the generation of inaccurate or fabricated personal information can be profoundly unfair and misleading to the person concerned. It is unexpected for an individual to find false and potentially damaging information about themselves generated by a service with which they may have never interacted.
Transparency: Transparency is a cornerstone of the GDPR, requiring controllers to be clear and open about how they use personal data. The Garante found that OpenAI had failed to provide an adequate privacy notice to both users and, crucially, non-users whose data was scraped from the internet to train the models. While OpenAI later took steps to make its privacy information more accessible and to provide an expanded notice following the Garante's order, the initial failure represents a significant breach of its transparency obligations under Articles 13 and 14 of the GDPR.
Purpose Limitation
This principle dictates that data collected for a "specified, explicit and legitimate" purpose should not be further processed for an incompatible purpose. When a consumer uses ChatGPT, their primary purpose is to receive an answer to a query—a processing activity that can be justified by contractual necessity. OpenAI's use of that same conversation data to train future models constitutes a secondary purpose. The question is whether this secondary purpose is "incompatible" with the first. Regulators and privacy advocates argue that it is, particularly when users are not explicitly and clearly informed of this secondary use at the point of collection, and when the data was originally scraped from the internet for entirely different purposes. OpenAI's implementation of an opt-out mechanism for consumers, rather than an opt-in, is a tacit acknowledgment of this secondary processing, but it places the burden on the user to protect their privacy, a practice often frowned upon by European DPAs.
Data Minimisation
As previously discussed, the core operational model of LLMs—training on vast, undifferentiated datasets—is in direct tension with the principle of data minimisation. The GDPR requires data to be "limited to what is necessary." It is difficult to argue that processing every available piece of personal data scraped from the internet is "necessary" to create a functional chatbot. The EDPB has suggested potential mitigation strategies, such as actively excluding data from sources known to contain information about vulnerable individuals or from websites that explicitly prohibit web scraping via a robots.txt file. However, it remains unclear to what extent OpenAI or other LLM developers implement such targeted data minimisation techniques. The burden of proof lies with the data controller to justify why the processing of each category of personal data is necessary for its specific purpose.
Accuracy
The accuracy principle, and the associated rights of rectification and erasure, represents OpenAI's most significant and unresolved GDPR challenge. The model's inherent tendency to "hallucinate" and generate fabricated personal data is a direct and ongoing violation of Article 5(1)(d).
This is not a theoretical risk. The privacy group noyb has filed formal complaints based on real-world cases where ChatGPT produced false and damaging information about individuals, such as incorrect birth dates or fabricated criminal histories. The core of the legal conflict is not just the generation of inaccurate data, but OpenAI's subsequent inability to fix it.
noyb's complaints allege that when confronted with a request to correct false information, OpenAI has admitted that it is technically impossible to guarantee the correction of specific data points within the trained model.
This admission is legally critical. The GDPR's right to rectification (Article 16) is not optional, and there is no exemption for "technical impossibility" when that impossibility is a result of the controller's own system design. This creates a legal impasse: the technology, in its current form, cannot comply with a fundamental right guaranteed by the law. This systemic failure has been flagged by both the EDPB task force and the Italian Garante as a key area of non-compliance.
Storage Limitation
The principle of storage limitation requires that personal data be deleted once it is no longer necessary for the purpose for which it was collected. While OpenAI has data retention policies in place, a significant external factor has created a direct conflict with this principle: US litigation. A recent preservation order issued by a US court in a copyright infringement lawsuit requires OpenAI to retain vast amounts of data, including user conversations that would otherwise be subject to deletion under its own 30-day policy or in response to a user's request for erasure under GDPR Article 17.
This creates an intractable cross-border legal dilemma. An EU citizen's legally guaranteed "right to be forgotten" is pitted directly against a US judicial order to preserve data. Under the GDPR, relying on a "legitimate interest" to retain data indefinitely due to the mere possibility of foreign litigation is a legally precarious and largely untested position. This conflict exposes OpenAI, and by extension its customers, to significant legal risk, as it may be forced to choose between violating a US court order or violating the GDPR.
Integrity and Confidentiality
While OpenAI promotes its robust security measures, including strong encryption and access controls, the data breach of March 2023 serves as a stark reminder that no system is infallible. This breach, which exposed user chat histories and payment-related information, was the direct catalyst for the Garante's investigation. Beyond the breach itself, the Garante also fined OpenAI for failing to properly notify the Italian DPA in accordance with the 72-hour reporting requirement under Article 33 of the GDPR, demonstrating a failure in its procedural security obligations.
Accountability
The final principle, accountability, requires a data controller not only to comply with the GDPR but also to be able to demonstrate that compliance. OpenAI's track record in this area shows significant weaknesses. Its pattern of behavior has been largely reactive, implementing changes to its privacy controls and transparency notices only after being compelled to do so by regulatory action from the Garante. This reactive posture undermines any claim of "privacy by design." Furthermore, documented reports from users experiencing difficulties in executing a DPA or in having their data subject rights fulfilled point to operational gaps in its accountability framework.
This systematic audit reveals a pattern where the very architecture of ChatGPT creates inherent conflicts with the GDPR. This has led to a strategic evolution in how privacy advocates challenge these systems. No longer content with just debating policy, groups like noyb are now strategically leveraging individual data subject rights as a precise legal tool to expose these deeper, architectural flaws. By filing a complaint on behalf of an individual whose request for rectification of an incorrect birth date was denied due to "technical impossibility," noyb transforms a system limitation into a clear-cut legal violation. The GDPR provides no defense for a system architecture that makes compliance with fundamental rights impossible. This tactic effectively weaponizes the GDPR's individual rights provisions, creating a legal checkmate that forces regulators to confront the core incompatibility between the technology and the law. It is a highly effective, scalable, and persistent strategy that poses a significant ongoing legal threat to any LLM trained on untraceable and un-rectifiable data.
The Regulatory Battleground: Enforcement Actions and Precedents
The theoretical conflicts between ChatGPT's operations and GDPR principles have escalated into tangible enforcement actions, with European data protection authorities (DPAs) taking a leading role in scrutinizing generative AI. The actions taken by Italy's Garante, the coordinated efforts of the European Data Protection Board (EDPB), and the persistent legal challenges from advocacy groups have created a high-stakes regulatory battleground that is actively shaping the future of AI governance in Europe.
Case Study: The Italian Garante's Landmark Ruling
The Italian DPA, the Garante, has been the most assertive regulator in addressing ChatGPT's compliance issues, providing a clear case study of the enforcement lifecycle from initial investigation to a substantial fine.
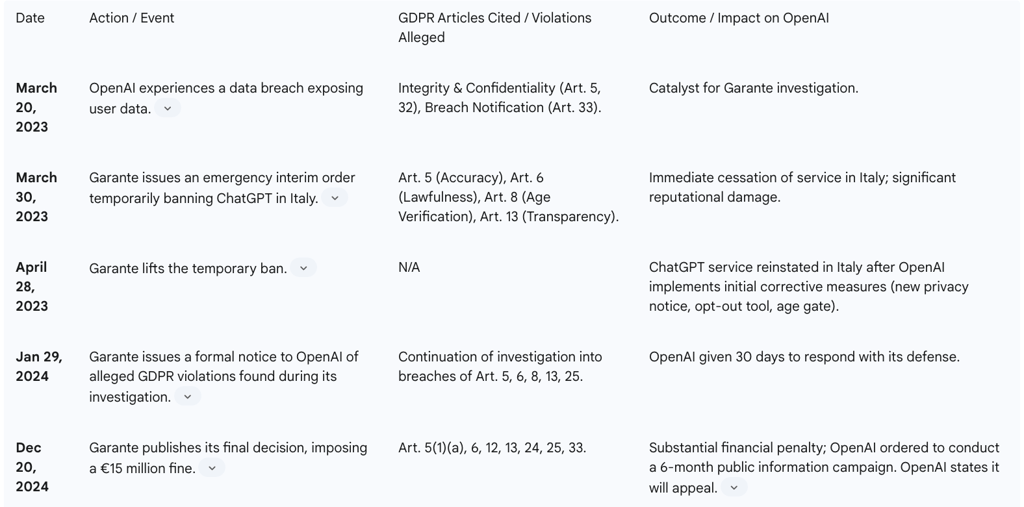
The Initial Ban (March 2023): Acting with urgency, the Garante issued an emergency interim order on March 30, 2023, temporarily banning OpenAI from processing the personal data of individuals in Italy. This drastic measure was prompted by a data breach OpenAI had recently suffered, which exposed user conversation titles and payment information. The Garante's order was the first of its kind by a Western country and signaled a new, more aggressive phase of AI regulation.
Alleged Violations: The Garante's initial order was based on several alleged GDPR violations, including: a lack of transparency due to an inadequate privacy notice (breach of Article 13); the absence of a valid legal basis for the mass collection and processing of personal data for training purposes (breach of Article 6); the processing of inaccurate data, as ChatGPT's outputs did not always correspond to real-world facts (breach of Article 5); and the lack of an effective age verification system to prevent minors under 13 from accessing the service and to ensure parental consent for those under 18 (breach of Article 8).
Corrective Measures and Reinstatement: The ban was not permanent. It was lifted on April 28, 2023, after OpenAI implemented a series of corrective measures to address the Garante's immediate concerns. These measures included making its privacy policy more visible, adding a tool for European users to object to their personal data being used for model training, and implementing an age-gating mechanism at registration.
The Final Fine (December 2024): Despite OpenAI's remedial actions, the Garante's underlying investigation continued. In a decision published on December 20, 2024, the authority imposed a €15 million fine on OpenAI. The fine was not for ongoing violations but for the historical breaches identified during the investigation. The Garante broke down the penalty, demonstrating a detailed accountability assessment:
€9,000,000 for the fundamental violation of unlawfully processing personal data for training purposes without a valid legal basis.
€320,000 for the procedural failure to properly notify the Garante of the March 2023 data breach as required by Article 33.
€5,680,000 for failing to fully comply with the corrective measures previously ordered by the authority.
This breakdown shows that even partial or delayed compliance does not absolve a company of liability for its initial failures.
Additional Measures: Beyond the financial penalty, the Garante ordered OpenAI to conduct a six-month "institutional communication campaign" across major Italian media outlets (TV, radio, newspapers) to inform the public about the processing of their data and their rights under the GDPR. This novel remedy underscores the regulatory focus on achieving broad public transparency and accountability.
The following table provides a chronological summary of this enforcement cycle, illustrating the escalating nature of regulatory action and the tangible consequences of GDPR non-compliance.
Table 2: Timeline of Italian Garante Enforcement Action Against OpenAI
The European Data Protection Board (EDPB) Task Force
The Garante's bold action did not occur in a vacuum. It spurred a coordinated European response. In April 2023, the EDPB, which comprises representatives from all EU national DPAs, established a dedicated task force to streamline cooperation and share information on investigations into ChatGPT.
In May 2024, the task force released a report on its preliminary findings. While not a final judgment, the report signaled a unified European position on several key issues. It concluded that ChatGPT's transparency measures were "not sufficient to comply with the data accuracy principle" and that the model's training approach could lead to biased or fabricated outputs that users would likely perceive as factually correct. The establishment of this task force and its initial findings indicate that OpenAI faces consistent and coordinated regulatory pressure across the entire EU, not just isolated challenges in individual member states.
The noyb Complaints: A Strategy of Attrition
Parallel to the actions of official regulators, the privacy advocacy group noyb, led by activist Max Schrems, has pursued a strategy of filing targeted complaints against OpenAI. These complaints are not broad policy challenges but are based on the specific experiences of individuals whose GDPR rights have allegedly been violated.
The primary focus of noyb's campaign has been on data accuracy and the right to rectification. They have filed complaints in Austria and supported others across Europe, highlighting cases where ChatGPT generated false personal information and OpenAI was unable or unwilling to correct it. The core legal argument is powerful in its simplicity: if a system cannot produce accurate results about individuals and cannot facilitate the right to correction, then it cannot be lawfully used to process personal data under the GDPR. This strategy of attrition, based on individual rights, keeps public and regulatory pressure on OpenAI, forces the company to expend resources responding to legal challenges, and aims to establish legal precedents that could fundamentally restrict how LLMs operate in Europe.
An Assessment of OpenAI's Compliance and Mitigation Efforts
In response to sustained regulatory pressure, legal challenges, and enterprise customer demand, OpenAI has implemented a series of measures aimed at mitigating its GDPR compliance risks. These efforts include offering European data residency, enhancing user controls, and updating its legal terms. However, a critical assessment reveals that while some of these measures address specific concerns, they may not resolve the more fundamental, architectural conflicts with European data protection law.
European Data Residency: A Solution to the Wrong Problem?
One of OpenAI's most significant recent initiatives is the introduction of data residency options in Europe for its business and developer products (ChatGPT Enterprise, Edu, and the API Platform). This allows eligible customers to have their data stored and processed "at rest" on servers located within the European Union. For API customers, it also offers the option to have requests processed in-region, with a zero data retention policy ensuring that prompts and responses are not stored on OpenAI's servers.
From a legal standpoint, this is a valuable and necessary step. It directly addresses the complex requirements of GDPR Chapter V, which governs the transfer of personal data outside the European Economic Area. By keeping data within the EU, organizations can more easily demonstrate compliance with these data transfer rules and alleviate concerns about foreign government surveillance. For an enterprise customer using the API with the European endpoint and Zero Data Retention, this represents a substantial mitigation of data sovereignty risk.
However, the limitations of this solution are as important as its benefits. Data residency does not solve the core GDPR violations identified by regulators. The foundational models themselves, regardless of where they are hosted or executed, were trained on globally scraped data, much of it without a valid legal basis. The inherent problem of data inaccuracy—the "hallucinations"—is a function of the model's architecture, not its physical location. Similarly, the technical inability to rectify or erase specific pieces of personal data from within the trained model persists no matter where that model is stored. Therefore, while data residency is a commercially astute move to reassure enterprise customers and solve the data transfer problem, it effectively sidesteps the more profound compliance challenges related to lawfulness, accuracy, and data subject rights that lie at the heart of the regulatory conflict.
User Controls and Opt-Out Mechanisms
OpenAI has introduced important user controls that provide a degree of agency over data use. For consumer users of ChatGPT Free and Plus, the ability to opt out of having their conversations used for model training is a key feature. For all business products, data is not used for training by default, which is a critical distinction. Furthermore, administrators of ChatGPT Enterprise accounts are given granular controls to manage user access, permissions, and the use of specific features within their workspace.
These controls are effective and essential for segregating new user-provided data from OpenAI's model training pipeline. They allow organizations to create a firewalled environment for their own data. However, like data residency, these controls do not address the "original sin" of the personal data that is already embedded within the foundational models from the initial, large-scale web scraping. They are a forward-looking solution that does not retroactively cure the compliance issues of the underlying training data.
The Evolving Terms of Service and DPA
OpenAI's legal documentation, including its Terms of Service and Data Processing Addendum (DPA), has evolved to provide greater clarity and to address regulatory feedback. The terms are now more explicit about the division of responsibilities, restrictions on use, and the customer's obligations. The formalization of the DPA execution process for business customers is a crucial step in enabling those customers to meet their own accountability obligations under Article 28 of the GDPR.
However, this evolution has also seen a clear trend of shifting the compliance burden onto the customer. The terms explicitly state that the customer must comply with all applicable laws and is responsible for the content they provide. For example, a business using the API is responsible for ensuring it has a lawful basis to input any personal data into the service. While this is a standard approach for B2B service providers, it creates a complex risk scenario. The customer is responsible for the lawfulness of the data they input, but they remain exposed to the legal and reputational risks arising from the potentially unlawful or inaccurate data that the model outputs. This shared responsibility model requires careful contractual scrutiny and a clear understanding of where the service provider's obligations end and the customer's begin.
Strategic Recommendations for Organizational Governance and Risk Mitigation
Given the complex and evolving landscape of legal risks associated with the use of OpenAI's services, organizations operating under the GDPR must adopt a proactive and rigorous governance framework. Simply accepting the service's terms is insufficient; a strategic approach is required to identify, assess, and mitigate the significant data protection risks involved. The following recommendations provide an actionable framework for any organization using or considering the use of ChatGPT or the OpenAI API.
Mandate a Data Protection Impact Assessment (DPIA) for All Use Cases
Under Article 35 of the GDPR, a Data Protection Impact Assessment (DPIA) is mandatory for any processing that is "likely to result in a high risk to the rights and freedoms of natural persons." The use of generative AI, an innovative technology capable of processing personal data on a large scale, clearly meets this threshold.
The DPIA must be a thorough and honest assessment of the risks, not a perfunctory compliance exercise. It must go beyond OpenAI's marketing materials and directly confront the difficult issues identified by regulators and in this report. This includes a specific analysis of the lawfulness of processing, the potential for inaccurate outputs containing personal data, the challenges in fulfilling data subject rights, and the risk of employees inadvertently inputting sensitive company or personal data into the platform ("prompt injection"). A well-executed DPIA is the foundational document for demonstrating accountability to regulators.
To guide this process, the DPIA should address the following key questions:
Lawfulness, Fairness, and Transparency: What is the specific and explicit purpose for using the AI service? What is the legal basis under GDPR Article 6 for inputting any personal data? How will data subjects (employees, customers) be informed about this processing in a clear and transparent manner, as required by GDPR Articles 13 and 14?
Data Minimisation: What is the absolute minimum amount of personal data required to achieve the stated purpose? Have measures been implemented to prevent the input of unnecessary or excessive personal data?
Accuracy: What is the process for identifying and correcting inaccurate personal data generated by the model about an employee, customer, or other individual? Given that OpenAI has stated this is technically challenging, what is the mitigation plan for the risk of reputational damage or defamation arising from AI "hallucinations"?
Data Subject Rights: What is the documented procedure for responding to a data subject request (e.g., for access, rectification, or erasure) when the relevant data has been processed by OpenAI? How will the organization handle a request it cannot fully technically fulfill due to the limitations of the AI model?
Security and Data Transfers: For which service tier is use being contemplated? Is a Data Processing Addendum in place? Will the European data residency option be utilized to prevent unlawful data transfers to the US? What technical and organizational measures are in place to prevent employees from inputting sensitive intellectual property or trade secrets?
Establish a Tiered Internal Usage Policy
A one-size-fits-all policy for ChatGPT is inappropriate given the significant differences between the service tiers. Organizations should implement a clear, tiered internal policy that is communicated to all employees.
Tier 1 (Prohibited): The use of the free consumer version of ChatGPT (Free/Plus) for any business-related purpose must be strictly prohibited. The default use of conversation data for model training and the lack of a DPA present an unacceptable level of risk for any organization subject to the GDPR.
Tier 2 (Restricted): The input of any personal data, sensitive commercial information, or valuable intellectual property into any version of the service, including enterprise-level tiers, should be restricted by default. Access to process such data should only be granted for specific, approved use cases that have undergone a full DPIA where the risks have been formally accepted by management.
Tier 3 (Approved Use): For any approved use case, the policy must mandate the use of either ChatGPT Enterprise or the API platform, with the European data residency option enabled and the Zero Data Retention (ZDR) feature activated where applicable and available. This ensures maximum control over data and minimizes data transfer risks.
Output Governance: The policy must require clear and conspicuous labeling of all AI-generated content to prevent it from being mistaken for human-generated work. Furthermore, it must prohibit the use of any AI-generated output for making decisions that have a legal or otherwise significant effect on an individual (e.g., in hiring, credit scoring, or performance reviews), in line with both OpenAI's own terms and the principles of GDPR Article 22.
Protocols for Managing Data Subject Rights (DSRs)
Organizations must anticipate and plan for the challenge of handling DSRs. A clear internal process is needed for when a request for access, rectification, or erasure involves data that has been processed by OpenAI. This process must acknowledge the technical limitations of the underlying model. The protocol should focus on fulfilling the request to the greatest extent possible—for example, by deleting the data from internal systems and conversation logs—while also documenting the technical inability to guarantee complete erasure or rectification from the trained model itself. This documentation is crucial for demonstrating a good-faith effort to comply and for managing legal risk in the event of a complaint.
Contractual Scrutiny
Legal and procurement teams must conduct a thorough review of OpenAI's terms and legal agreements.
Data Processing Addendum (DPA): It is imperative to ensure that a DPA is fully and properly executed with OpenAI Ireland Ltd. for all business use cases. The absence of a DPA is a direct violation of GDPR Article 28.
Indemnification: The indemnification clauses must be carefully scrutinized. While OpenAI offers some indemnity against third-party intellectual property infringement claims for ChatGPT Enterprise and API customers, this protection is subject to significant exceptions. For instance, the indemnity may not apply if the customer "knew or should have known the Output was infringing". This leaves a considerable amount of residual risk with the customer.
Usage Restrictions: Be aware of and ensure compliance with OpenAI's own usage restrictions, such as the prohibition on using outputs to develop models that compete with OpenAI.
By implementing this strategic framework, organizations can move from a position of uncertainty and high risk to one of managed and documented compliance, enabling them to navigate the complexities of using generative AI in a manner that respects both innovation and the fundamental data protection rights of individuals.
FAQ
What are the fundamental tensions between the GDPR and the design of Large Language Models (LLMs) like OpenAI's ChatGPT?
The General Data Protection Regulation (GDPR) imposes stringent requirements on data processing, which frequently conflict with the inherent architecture of Large Language Models (LLMs). Key tensions arise from several core GDPR principles:
Data Minimisation: GDPR mandates that personal data collected must be "adequate, relevant and limited to what is necessary." LLMs, however, are predicated on being trained on "vast quantities of information," including indiscriminate scraping of internet datasets, which inevitably contain personal data. This "more is better" ethos of LLM training appears to directly oppose the principle of minimisation.
Accuracy: GDPR requires personal data to be "accurate" and mandates "every reasonable step" to rectify or erase inaccurate data. LLMs are prone to "hallucinations," generating false or misleading information, including about individuals. OpenAI has reportedly admitted a technical inability to correct specific pieces of false data within the trained model, making compliance with the "right to rectification" (Article 16) practically impossible.
Lawful Basis: All processing of personal data under GDPR must be justified by one of six lawful bases. While providing the ChatGPT service to a user might be justified by "contractual necessity," the mass processing of personal data for training the underlying model is a separate activity. Regulators, such as the Italian Garante, have found OpenAI's reliance on "legitimate interest" for this extensive training data collection to be insufficient, particularly when it involves vast quantities of personal data from non-users who have no direct relationship with OpenAI.
Purpose Limitation: Data must be collected for "specified, explicit, and legitimate purposes" and not processed incompatibly. When data from public forums is repurposed to train a commercial AI, or consumer chat data is used for model improvement without explicit consent, it challenges this principle, as the secondary purpose may be deemed incompatible with the original collection purpose.
These conflicts suggest that genuine GDPR compliance for LLMs may require a fundamental shift away from indiscriminate data collection towards curated, consented, and verifiable data sources.
How do OpenAI's data handling policies differ between its consumer and business services, and why is this distinction crucial for GDPR compliance?
OpenAI employs a bifurcated approach to data handling, significantly differentiating between its consumer-facing services (ChatGPT Free and Plus) and its business offerings (API, ChatGPT Team, Enterprise, and Edu). This distinction is crucial for GDPR compliance due to varying default settings, user controls, and legal frameworks.
Consumer Services (ChatGPT Free and Plus): For these tiers, User Content (prompts, questions) is, by default, used to improve OpenAI's services, including model training. Users must proactively opt out of this data use via settings or by using "Temporary Chats." There is no Data Processing Addendum (DPA) available for these services, meaning OpenAI acts as a data controller for this data, increasing the risk for individuals and organisations that inadvertently use these services for business purposes.
Business Services (API, ChatGPT Team, Enterprise, and Edu): In stark contrast, a central commitment for these offerings is that OpenAI does not use customer data submitted via these platforms to train or improve its models by default. For these services, customers generally retain ownership of their inputs and outputs. A Data Processing Addendum (DPA) is offered, formally establishing OpenAI as a "data processor" acting on the customer's instructions, and obligating OpenAI to adhere to GDPR requirements. Additionally, options like European data residency and Zero Data Retention (ZDR) for the API platform further enhance control and mitigate data transfer risks.
This distinction is crucial because the default use of data for training and the absence of a DPA for consumer versions make their use for processing any corporate or personal data a high-risk activity from a GDPR perspective. Organisations subject to GDPR are strongly advised to prohibit the use of consumer-grade tools for business purposes and channel approved use cases through the more robustly controlled enterprise and API platforms.
What was the significance of the Italian Garante's enforcement action against OpenAI?
The Italian Garante's enforcement action against OpenAI was landmark, marking the first time a Western country issued an emergency ban on a generative AI service due to data protection concerns and subsequently imposed a substantial fine.
Initial Ban (March 2023): Prompted by a data breach, the Garante issued an interim order temporarily banning ChatGPT in Italy. This was a drastic and unprecedented measure, signalling a new, more aggressive phase of AI regulation.
Alleged Violations: The ban was based on alleged GDPR violations, including a lack of transparency (inadequate privacy notice for users and non-users whose data was scraped), absence of a valid legal basis for mass data collection for training, processing of inaccurate data (AI hallucinations), and insufficient age verification.
Corrective Measures and Reinstatement: OpenAI implemented initial corrective measures (e.g., more visible privacy policy, an opt-out tool for EU users, age-gating), leading to the ban's lift.
Final Fine (€15 million, December 2024): Despite remedial actions, the Garante's investigation continued, culminating in a €15 million fine for historical breaches. The fine was broken down: €9 million for unlawful data processing for training, €320,000 for failure to notify the data breach, and €5.68 million for failing to fully comply with previous orders.
Additional Measures: OpenAI was also ordered to conduct a six-month public communication campaign in Italy to inform citizens about their data processing and rights.
The Garante's action demonstrated that European regulators are willing to take strong, immediate measures against major AI players and that partial compliance does not absolve companies of liability for initial failures. It also spurred coordinated efforts across the European Data Protection Board (EDPB) to address similar concerns.
How does the phenomenon of AI "hallucinations" create a direct conflict with the GDPR's accuracy principle and the right to rectification?
AI "hallucinations," where a model generates "false or misleading information presented as fact," create a profound and often intractable conflict with the GDPR's accuracy principle (Article 5(1)(d)) and the associated right to rectification (Article 16).
Violation of Accuracy: When an LLM fabricates incorrect personal data about an individual (e.g., false birth dates, professional histories, or criminal accusations), it directly violates the GDPR's requirement that personal data must be "accurate" and "kept up to date." This is not a mere technical glitch but a legal breach with potentially severe implications for the data subject, including reputational damage.
Technical Inability to Rectify: The core of the legal conflict arises from OpenAI's reported admission that it is technically unable to correct specific pieces of false data within the trained model. Once data is amalgamated into a model's weights, pinpointing and altering individual data points to ensure accuracy or facilitate rectification becomes technically infeasible.
Legal Impasse: The GDPR's right to rectification (Article 16) is a fundamental and non-optional right. There is no legal exemption for "technical impossibility," especially when that impossibility results from the data controller's own system design. This creates a legal impasse: the current technology cannot comply with a fundamental right guaranteed by the law.
Advocacy Group Strategy: Privacy groups like noyb have strategically leveraged this issue by filing formal complaints on behalf of individuals whose rectification requests for false information were denied. This "weaponises" the individual rights provisions, transforming a technical limitation into a clear-cut legal violation and forcing regulators to confront the core incompatibility between LLM architecture and data protection law.
This systemic failure has been identified by the EDPB task force and the Italian Garante as a key area of non-compliance, demonstrating a fundamental challenge to the current paradigm of LLM development.
Why is a Data Protection Impact Assessment (DPIA) mandatory for organisations using generative AI services like OpenAI, and what key questions should it address?
A Data Protection Impact Assessment (DPIA) is mandatory for organisations using generative AI services like OpenAI because such processing is "likely to result in a high risk to the rights and freedoms of natural persons" under Article 35 of the GDPR. Generative AI involves large-scale processing of personal data and is an innovative technology with inherent risks, clearly meeting this threshold.
A thorough DPIA for AI use cases should be a comprehensive and honest assessment of risks, going beyond simple compliance. It must directly confront the difficult issues identified by regulators and should address the following key questions:
Lawfulness, Fairness, and Transparency:What is the specific purpose for using the AI service?
What is the legal basis under GDPR Article 6 for inputting any personal data?
How will data subjects (employees, customers) be clearly informed about this processing (Articles 13 and 14 GDPR)?
Data Minimisation:What is the absolute minimum amount of personal data required?
Have measures been implemented to prevent unnecessary or excessive personal data input?
Accuracy:What is the process for identifying and correcting inaccurate personal data generated by the model?
Given OpenAI's technical limitations, what is the mitigation plan for reputational damage or defamation from "hallucinations"?
Data Subject Rights:What is the documented procedure for responding to data subject requests (access, rectification, erasure) when data has been processed by OpenAI?
How will the organisation handle requests that cannot be fully technically fulfilled due to AI model limitations?
Security and Data Transfers:Which service tier is being used? Is a Data Processing Addendum (DPA) in place?
Will the European data residency option be utilised to prevent unlawful data transfers to the US?
What technical and organisational measures prevent employees from inputting sensitive intellectual property or trade secrets?
A well-executed DPIA is the foundational document for demonstrating accountability to regulators and for proactively managing the significant data protection risks associated with generative AI.
What are the main challenges for organisations in fulfilling Data Subject Rights (DSRs) when using OpenAI's services, especially the right to rectification and erasure?
Organisations using OpenAI's services face significant challenges in fulfilling Data Subject Rights (DSRs), particularly the right to rectification and erasure, due to the inherent technical limitations of LLMs.
Technical Infeasibility of Rectification and Erasure within Trained Models: The most critical challenge is OpenAI's stated technical inability to guarantee the correction or erasure of specific data points embedded within its foundational, pre-trained models. Once personal data has been amalgamated into the vast parameters and weights of an LLM during its initial training, it becomes practically impossible to isolate, modify, or remove that specific data point without retraining the entire model, which is not feasible for individual requests.
Impact of AI Hallucinations on Accuracy: When an AI hallucinates and generates false personal information, the data controller (the organisation using the service) is responsible for ensuring accuracy and rectifying inaccuracies. However, if the underlying OpenAI model cannot be corrected, the organisation is left with a legal obligation it cannot technically fulfil.
Storage Limitation Conflicts: US litigation requiring OpenAI to preserve vast amounts of data can directly conflict with GDPR's storage limitation principle and an EU citizen's right to erasure (the "right to be forgotten"). This cross-border legal dilemma pits a US judicial order against a legally guaranteed EU right, forcing organisations to navigate a precarious position.
Operational Gaps and Documentation: Even with internal processes for DSRs, organisations must anticipate and plan for scenarios where OpenAI's platform cannot facilitate the request. This requires clear internal protocols for documenting the technical limitations, demonstrating good-faith efforts to comply, and managing legal risk in the event of a complaint to a DPA.
Reactive Compliance from OpenAI: OpenAI's history of implementing changes to its privacy controls and transparency notices only after regulatory action indicates a reactive, rather than proactive, approach to compliance. This can leave organisations with operational gaps when trying to fulfil DSRs that rely on the underlying service provider's capabilities.
Ultimately, organisations must acknowledge these technical and legal limitations and develop robust internal protocols for DSRs that account for them, while also understanding that they may still face legal challenges if fundamental rights cannot be satisfied by the AI service.
What strategic recommendations are advised for organisations to mitigate GDPR risks when using OpenAI, particularly regarding internal usage policies?
To mitigate GDPR risks when using OpenAI, organisations must adopt a proactive and rigorous governance framework, extending beyond simply accepting service terms. Key strategic recommendations include:
Mandate a Data Protection Impact Assessment (DPIA) for All Use Cases:
A DPIA is mandatory for generative AI due to the high risk involved.
It must thoroughly assess risks related to lawfulness, data minimisation, accuracy, data subject rights, and data transfers.
It should specifically address how personal data will be managed, the legal basis for processing, and mitigation plans for AI hallucinations.
Establish a Tiered Internal Usage Policy:
Tier 1 (Prohibited): Strictly prohibit the use of the free consumer version of ChatGPT (Free/Plus) for any business-related purpose. The default data use for model training and absence of a DPA present unacceptable risk.
Tier 2 (Restricted): Restrict the input of any personal data, sensitive commercial information, or valuable intellectual property into any version of the service by default. Access should only be granted for specific, approved use cases following a full DPIA.
Tier 3 (Approved Use): For approved cases, mandate the use of ChatGPT Enterprise or the API platform with the European data residency option enabled and Zero Data Retention (ZDR) activated where available.
Output Governance: Require clear labelling of all AI-generated content and prohibit its use for decisions with a legal or significant effect on individuals (e.g., hiring, credit scoring).
Protocols for Managing Data Subject Rights (DSRs):
Develop a clear internal process for responding to DSRs (access, rectification, erasure) involving OpenAI-processed data.
Acknowledge the technical limitations of the AI model and document efforts to fulfil requests (e.g., deleting data from internal logs) while noting the inability to guarantee complete erasure from the trained model itself.
Contractual Scrutiny:
Ensure a Data Processing Addendum (DPA) is fully and properly executed with OpenAI Ireland Ltd. for all business use cases.
Carefully scrutinise indemnification clauses, as OpenAI's protection against IP infringement claims may have significant exceptions, leaving residual risk with the customer.
Be aware of and ensure compliance with OpenAI's own usage restrictions (e.g., prohibition on developing competing models).
By implementing this framework, organisations can move from high uncertainty to managed and documented compliance, balancing innovation with fundamental data protection rights.
How do data residency options and user controls offered by OpenAI address GDPR concerns, and what are their limitations?
OpenAI has introduced data residency options and enhanced user controls to address GDPR concerns, but these measures have specific benefits and significant limitations.
Data Residency Options (for Business and Developer products):
Benefit: Allows eligible customers to store and process their data "at rest" on servers within the European Union (EU). For API customers, it can also ensure in-region request processing with zero data retention (ZDR). This directly addresses GDPR Chapter V requirements concerning international data transfers outside the EEA, alleviating concerns about foreign government surveillance.
Limitation: While valuable for data sovereignty and transfer risks, data residency does not solve the core GDPR violations identified by regulators. The foundational models themselves were trained on globally scraped data, much of it without a valid legal basis. The inherent problem of AI "hallucinations" (inaccuracy) and the technical inability to rectify or erase specific personal data from within the trained model persist regardless of the data's physical location. It addresses where current data is processed but not the "original sin" of the underlying training data.
User Controls and Opt-Out Mechanisms:
Benefit: For consumer users of ChatGPT Free and Plus, the ability to opt out of having conversations used for model training provides a degree of agency. For all business products, data is not used for training by default, which is a crucial distinction that allows organisations to create a firewalled environment for their own data. Enterprise accounts also offer granular administrative controls.
Limitation: These controls are effective for segregating new, user-provided data from OpenAI's model training pipeline. However, they do not address the personal data already embedded within the foundational models from the initial, large-scale web scraping. They are a forward-looking solution that does not retroactively cure the compliance issues of the underlying training data, which regulators primarily scrutinise for lawfulness and accuracy.
In summary, while these measures are commercially astute and address specific aspects of GDPR compliance (like data transfers and control over new inputs), they effectively sidestep the more profound and systemic challenges related to the lawfulness, accuracy, and fundamental data subject rights concerning the vast datasets used to train the core LLM models.