Federated Learning and GDPR: Data Privacy in Decentralized AI
Federated Learning (FL) represents a transformative paradigm in artificial intelligence, enabling collaborative model training across distributed datasets without centralizing raw personal data.


Federated Learning (FL) represents a transformative paradigm in artificial intelligence, enabling collaborative model training across distributed datasets without centralizing raw personal data. This inherent architectural design offers significant advantages for data privacy and efficiency, aligning fundamentally with key tenets of the General Data Protection Regulation (GDPR), particularly data minimisation and privacy by design. However, achieving comprehensive GDPR compliance within FL systems presents complex challenges, notably concerning the right to erasure, dynamic consent management, and the need for robust accountability and interpretability.
This report delves into the intricate relationship between FL and GDPR, elucidating FL's operational mechanisms and GDPR's core principles. It provides a detailed analysis of how FL supports and challenges compliance, highlighting the critical role of Privacy-Enhancing Technologies (PETs) such as Differential Privacy, Secure Multi-Party Computation, and Homomorphic Encryption in mitigating residual risks. Through real-world applications in healthcare and finance, the report illustrates practical compliance strategies. It concludes with an overview of regulatory guidance and best practices, emphasizing that while FL offers a powerful foundation for privacy-preserving AI, its full compliance with GDPR necessitates a sophisticated, multi-layered approach involving advanced technical measures and rigorous governance frameworks to ensure data subject rights are upheld and risks are effectively managed.
Introduction to Federated Learning
1.1. Definition, Core Principles, and Operational Mechanisms
Federated Learning (FL), often referred to as collaborative learning, is an innovative machine learning technique designed for environments where multiple entities, known as clients, cooperatively train a shared global model while maintaining their individual data decentralized and local. This approach marks a significant departure from traditional centralized machine learning models, which typically require all data to be aggregated in a single location for training, thereby introducing inherent data privacy risks.
The fundamental operational principles of FL revolve around local computing and model transmission. In essence, clients perform machine learning model training directly on their private datasets. Instead of transmitting raw data, these clients send only trained model parameters—such as the weights and biases of a deep neural network—or model updates to a central server. The central server's role is to aggregate these received parameters to update a global model, which is then redistributed back to the clients for subsequent training rounds. This iterative process, characterized by a series of client-server interactions, constitutes a federated learning round.
The operational mechanisms in a typical centralized FL setting unfold through several key stages:
Initialization: A machine learning model (e.g., linear regression, neural network) is selected and initialized by the central server. Participating clients are then activated and await computational tasks.
Client Selection: In each round, a subset or fraction of the local nodes is chosen to participate in the training. These selected nodes receive the current version of the global statistical model.
Configuration: The central server instructs the selected clients to train the model on their local data, specifying parameters such as the number of mini-batch updates or epochs.
Reporting: Upon completing their local training, each selected client transmits its local model updates to the central server for aggregation.
Aggregation: The central server aggregates the received model updates. A common method is Federated Averaging (FedAvg), where the server averages the gradients or parameters, often weighting them in proportion to the number of training data samples on each client. The server is also responsible for handling failures, such as disconnected nodes or lost updates.
Redistribution and Iteration: The newly aggregated global model is then sent back to the participating clients, initiating the next federated round.
Termination: The entire process concludes once a predefined criterion is met, such as reaching a maximum number of iterations or achieving a desired model accuracy.
Key parameters governing FL operations include the total number of federated learning rounds, the overall number of nodes involved, the fraction of nodes participating in each iteration, and the local batch size used during training. Beyond FedAvg, other algorithms like Federated Stochastic Variance Reduced Gradient (FSVRG) have also been proposed for federated optimization.
1.2. Architectural Types and Data Partitioning in FL
Federated Learning systems can be implemented with various communication architectures, each designed to suit different operational needs and scales :
Centralized Architectures: In this common topology, a single aggregation server acts as a hub, collecting, aggregating, and distributing models among training nodes, and managing the overall training iterations.
Distributed Architectures: Here, aggregation occurs simultaneously at each training node, with clients connected to one or more peers.
Hierarchical Architectures: These combine elements of peer-to-peer federations and aggregation server federations, forming complex federated networks with multiple sub-federations.
Asynchronous Architectures: Clients send updates to the server without waiting for a synchronous response, which helps reduce idle time and effectively handles "stragglers" (clients with latency issues), optimizing performance in environments with variable connectivity.
Decentralized Architectures: In this setup, there is no central server; clients communicate and share updates directly with each other. This increases robustness and fault tolerance by eliminating a single point of failure.
The effectiveness of FL is also heavily influenced by how data is partitioned across clients :
Horizontal Federated Learning (HFL): This applies when clients share identical feature spaces but possess distinct sample spaces. For example, multiple hospitals might have patient data with the same features (e.g., age, diagnosis codes) but for different patient populations. HFL facilitates collaboration among institutions with similar data structures.
Vertical Federated Learning (VFL): This is used when datasets may differ in features but share similar sample IDs. An example would be a bank and an insurance company collaborating on a shared customer base, where each entity holds different, complementary attributes for the same individuals.
Federated Transfer Learning (FTL): This approach integrates transfer learning with FL, leveraging pre-trained models to adapt to new tasks or domains, thereby facilitating knowledge transfer across different data environments.
A significant consideration in FL implementations is system heterogeneity, which encompasses variability in clients' computing capacity, energy availability, network connectivity, and, crucially, diverse data distributions (often referred to as non-IID data). Non-IID data poses a fundamental challenge, as it can lead to slower model convergence and performance disparities among participating nodes. To address this statistical heterogeneity, various strategies are employed, including sampling methodologies, clustering nodes with similar data distributions during training, and specialized optimization algorithms like FedProx.
1.3. Inherent Advantages for Data Privacy and Efficiency
The decentralized nature of Federated Learning offers several compelling advantages, particularly in the realm of data privacy and operational efficiency.
The most defining advantage of FL is its enhanced data privacy. By design, sensitive raw data never leaves the local device or the organizational boundary where it originated. Instead, only model updates or parameters are exchanged with a central server, significantly reducing the risk of data breaches, unauthorized access, and exposure of personal information. This characteristic is profoundly valuable in highly regulated sectors such as finance and healthcare, where data protection and sensitivity are paramount concerns.
This decentralized approach to data processing fundamentally addresses what is often termed the "data island" phenomenon. In many industries, valuable datasets are dispersed and isolated across various entities—such as hospitals, financial institutions, or government agencies—primarily due to stringent privacy policies and regulatory frameworks like GDPR. Traditional machine learning, which necessitates centralizing these disparate datasets, often leads to significant data privacy leakage issues. Federated Learning provides a technical solution to this problem by enabling collaborative training of high-quality models on the union of these distributed datasets without direct data sharing. This capability allows organizations to collectively build more robust and accurate models, even with minimal data available to individual service providers for training. The ability to integrate insights from different data providers into model training, which was previously impractical or legally prohibitive, unlocks new avenues for data utilization and value creation. This means FL is not merely a tool for privacy compliance but also a significant business enabler in a data-constrained world, transforming regulatory constraints into opportunities for collective intelligence and competitive advantage.
Beyond privacy, FL also offers substantial efficiency gains. By eliminating the need to access or transfer massive datasets to a central location, FL significantly reduces latency and lowers the required bandwidth for training machine learning models. This can translate into considerable savings in infrastructure and network overheads, particularly for large training datasets.
Furthermore, the decentralized design of FL inherently fosters improved compliance with data protection regulations. The architecture, which minimizes data sharing and keeps sensitive information on the local node, directly supports principles such as data minimization and privacy by design. This structural alignment with privacy principles from the outset can simplify regulatory considerations and reduce associated legal costs in the long term.
It is important to recognize that while FL provides a strong foundation for privacy by design by decentralizing data, it is not a complete solution on its own. Its "privacy-by-design" characteristic is a crucial starting point that significantly reduces initial risk, but it must be complemented by additional technical safeguards and robust governance to address residual vulnerabilities and achieve true, formal privacy guarantees. This implies that organizations cannot simply adopt FL and assume full GDPR compliance; active implementation of further measures is essential.
Overview of the General Data Protection Regulation (GDPR)
2.1. The Seven Core Principles of Data Processing (Article 5)
The General Data Protection Regulation (GDPR), a cornerstone of European information privacy law, establishes a comprehensive framework for the processing of personal data within the European Union (EU), the European Economic Area (EEA), and the United Kingdom (UK). At its heart, Article 5 of the GDPR outlines seven fundamental principles that data controllers must adhere to when handling personal data. These principles are designed to ensure that personal data is processed fairly, transparently, and securely, while respecting the rights of data subjects.
Lawfulness, Fairness, and Transparency (Article 5(1)(a)): This foundational principle mandates that personal data must be processed lawfully, fairly, and in a transparent manner in relation to the data subject.
Lawfulness requires that any processing of personal data must be based on a valid legal ground as specified in the GDPR (e.g., consent, contract, legal obligation, vital interests, public interest, legitimate interests).
Fairness implies that processing should be equitable towards the individual, avoiding practices that are unduly detrimental, unexpected, misleading, or deceptive.
Transparency is particularly emphasized, requiring that the processing of personal data is clear and comprehensible to individuals and regulators. Controllers must provide information in a concise, easily accessible, and plain language format, both before data collection and whenever processing purposes change. Specific rules in Articles 12, 13, and 14 detail the types of information to be provided and the manner of provision, ensuring individuals are informed about the existence and purposes of processing operations.
Purpose Limitation (Article 5(1)(b)): Personal data must be collected for specified, explicit, and legitimate purposes that are determined at the time of collection. Furthermore, data should not be further processed in a manner that is incompatible with those initial purposes. Limited exceptions exist for further processing for archiving purposes in the public interest, scientific or historical research purposes, or statistical purposes, provided sufficient safeguards are in place, as these are generally not considered incompatible. This principle ensures that controllers are clear about their proposed processing activities and that these align with individuals' reasonable expectations.
Data Minimisation (Article 5(1)(c)): This principle dictates that personal data collected and processed must be adequate, relevant, and limited to what is strictly necessary for the purposes for which they are processed. It implies collecting the minimum amount of data required and avoiding unnecessary personal data. Implementing data minimisation supports privacy by design and by default, limits the potential impact of data breaches, and aids in ensuring data accuracy.
Accuracy (Article 5(1)(d)): Controllers are obligated to ensure that personal data is accurate and, where necessary, kept up-to-date. Every reasonable step must be taken to ensure that personal data that is inaccurate, having regard to the purposes for which it is processed, is erased or rectified without delay. This requires clear procedures for correcting or erasing inaccurate data.
Storage Limitation (Article 5(1)(e)): Personal data must be kept in a form that permits the identification of data subjects for no longer than is necessary for the purposes for which the personal data are processed. Longer storage periods are permissible solely for archiving in the public interest, scientific or historical research purposes, or statistical purposes, provided appropriate technical and organizational safeguards are in place. Controllers should establish clear time limits for erasure or periodic review of data.
Integrity and Confidentiality (Article 5(1)(f)): Personal data must be processed in a manner that ensures appropriate security and confidentiality, including protection against unauthorized or unlawful processing and against accidental loss, destruction, or damage. This necessitates the implementation of appropriate technical or organizational measures, such as cybersecurity protocols, physical security, and organizational policies, which should be routinely checked for effectiveness.
Accountability (Article 5(2)): This principle is a distinctive addition under the GDPR, explicitly stating that controllers are responsible for, and must be able to demonstrate compliance with, all the other data protection principles. This goes beyond mere compliance, requiring organizations to implement and maintain appropriate processes and records to demonstrate their adherence. Measures supporting accountability include data protection by design and by default, transparent information provision, data retention policies, internal policies, data breach recording and reporting, and, where applicable, appointing a Data Protection Officer (DPO) and conducting Data Protection Impact Assessments (DPIAs).
2.2. Key Data Subject Rights (Articles 12-23)
Chapter 3 of the GDPR (Articles 12-23) grants individuals a comprehensive set of rights over their personal data, empowering them to control how their information is processed and imposing significant obligations on data controllers.
Right to Transparent Information, Communication, and Modalities (Articles 12-14): Data subjects have the right to receive information about the processing of their personal data in a concise, transparent, intelligible, and easily accessible form, using clear and plain language. This includes detailed information about the controller's identity, processing purposes, legal basis, recipients, and retention periods, whether data is collected directly from the individual (Article 13) or obtained from other sources (Article 14).
Right of Access (Article 15): Individuals have the right to obtain confirmation from the controller as to whether or not personal data concerning them is being processed, and, where that is the case, access to the personal data itself and various information regarding its processing.
Right to Rectification (Article 16): Data subjects have the right to obtain from the controller, without undue delay, the rectification of inaccurate personal data concerning them. They also have the right to have incomplete personal data completed, including by providing a supplementary statement.
Right to Erasure ('Right to be Forgotten') (Article 17): This grants data subjects the right to obtain the erasure of personal data concerning them without undue delay, under certain conditions. These conditions include situations where the data is no longer necessary for the purposes for which it was collected or processed, or when the data subject withdraws consent.
Right to Restriction of Processing (Article 18): Data subjects have the right to obtain from the controller a restriction of processing where certain conditions apply, for example, if the accuracy of the personal data is contested by the data subject, for a period enabling the controller to verify the accuracy.
Notification Obligation (Article 19): The controller is obligated to communicate any rectification or erasure of personal data or restriction of processing to each recipient to whom the personal data has been disclosed, unless this proves impossible or involves disproportionate effort.
Right to Data Portability (Article 20): Data subjects have the right to receive the personal data concerning them, which they have provided to a controller, in a structured, commonly used, and machine-readable format. They also have the right to transmit those data to another controller without hindrance.
Right to Object (Article 21): Data subjects have the right to object, on grounds relating to their particular situation, at any time to processing of personal data concerning them which is based on legitimate interests or the performance of a task carried out in the public interest or in the exercise of official authority. They also have the right to object to processing for direct marketing purposes.
Automated Individual Decision-Making, including Profiling (Article 22): Data subjects have the right not to be subject to a decision based solely on automated processing, including profiling, which produces legal effects concerning them or similarly significantly affects them, unless certain exceptions apply. This includes rights to human intervention, meaningful explanations of the logic involved, and special protections for high-risk AI applications.
Restrictions (Article 23): This article allows for restrictions on the scope of the obligations and rights mentioned in Articles 12 to 22 when such a restriction respects the essence of the fundamental rights and freedoms and is a necessary and proportionate measure to safeguard certain important objectives of general public interest.
2.3. Scope and Applicability to AI Systems
The GDPR's broad scope ensures its applicability to any processing of personal data of individuals located within the European Economic Area (EEA) or the United Kingdom, irrespective of where the organization is established or where the actual processing takes place. This mandate extends directly to Artificial Intelligence (AI) and Machine Learning (ML) systems that process personal data. Since May 25, 2018, any AI system handling personal data of EU residents must comply with GDPR requirements.
"Personal data" under the GDPR is defined expansively, encompassing any information relating to a living, identified, or identifiable person. Examples include names, Social Security Numbers, other identification numbers, location data, IP addresses, online cookies, images, email addresses, and content generated by the data subject. The regulation also imposes more stringent protections for "special categories of personal data," such as racial or ethnic origin, political opinions, religious or philosophical beliefs, trade union membership, genetic data, biometric data, health data, and data concerning a person's sex life or sexual orientation. Additionally, limitations are placed on the processing of personal data relating to criminal convictions and offenses.
For AI and ML applications, GDPR mandates that processing personal data must have an explicit consent or another lawful basis. Transparency about data use is crucial, and data subjects must be enabled to exercise their rights. This includes clearly explaining how personal data will be used in AI model training and deployment, specifying types of automated processing, providing granular consent options, and enabling easy withdrawal of consent with corresponding data removal from AI systems. The GDPR also requires that machine learning systems adhere to principles of data minimisation and purpose limitation, ensuring that only necessary data is collected for specified purposes and avoiding repurposing without additional consent. Furthermore, automated decision-making under GDPR necessitates protections, including the right to human intervention, meaningful explanations of the logic involved, and special safeguards for high-risk AI applications that process sensitive data.
Federated Learning and GDPR Compliance: A Detailed Analysis
Federated Learning (FL) offers a compelling approach to machine learning that inherently aligns with several core GDPR principles, primarily due to its decentralized nature. However, its implementation also introduces unique challenges in fully meeting all GDPR requirements, particularly concerning data subject rights and accountability.
3.1. FL's Alignment with GDPR Principles
FL's architectural design provides a structural advantage in complying with several GDPR principles, making it an attractive option for organizations handling sensitive data.
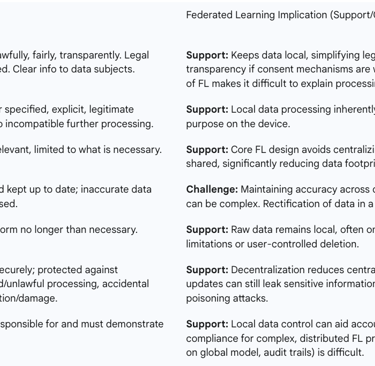
Data Minimisation (Article 5(1)(c)): FL directly supports this principle by ensuring that raw personal data remains on local devices or within organizational boundaries. Instead of transferring entire datasets, only aggregated model parameters or updates are exchanged. This significantly reduces the amount of personal data that needs to be transferred and processed by third parties, thereby minimizing data exposure and potential risks associated with central data storage. The Information Commissioner's Office (ICO) specifically notes that processing data locally aligns with the legal requirement of data minimisation.
Privacy by Design and by Default (Article 25): FL embodies the concept of privacy by design by introducing structural privacy protections from the outset, rather than as an afterthought. By preventing the centralization of raw data, FL inherently reduces privacy risks and helps demonstrate a commitment to data protection principles. This approach aligns with the GDPR's emphasis on building privacy into systems from the ground up. As a Privacy-Enhancing Technology (PET), FL, when applied correctly, can provide a strong foundation for data protection.
Integrity and Confidentiality (Article 5(1)(f)): By keeping sensitive data local, FL minimizes the risk of cyberattacks or data breaches that typically target centralized repositories. This decentralized processing enhances data security, as there is no single point of failure where all personal data used in model training could be compromised.
Lawfulness, Fairness, and Transparency (Article 5(1)(a)): FL can simplify consent management by allowing data to remain on user devices, potentially increasing transparency and control for data subjects over their personal data. However, the complexity of FL systems requires clear and comprehensive information to be provided to data subjects about how their local data contributes to the global model, ensuring fair and transparent processing.
Accountability (Article 5(2)): FL can support controllers in implementing the accountability principle by allowing them to better control access to personal data and potentially avoid unlawful re-purposing of processing. FL frameworks can log user participation to streamline compliance audits.
Table 1: GDPR Core Principles and Federated Learning Implications

3.2. Critical GDPR Compliance Challenges in FL Implementations
Despite its inherent privacy advantages, Federated Learning introduces several complex challenges when striving for full GDPR compliance, particularly concerning data subject rights and the overarching accountability principle.
The Right to Erasure (Article 17)
GDPR's Article 17 grants individuals the "right to be forgotten," allowing them to demand the deletion of their personal data under specific conditions. In the context of FL, this right presents significant technical and mathematical complexities. Once an individual's data has contributed to a local model update, and that update has been aggregated into the global model, retroactively removing their influence from the collective model becomes computationally intractable for large models. This is because the global model's parameters are a complex aggregation of countless individual contributions over many training rounds, making it difficult to isolate and nullify the impact of a single data point without retraining the entire model from scratch, which is often infeasible. While the local dataset can be easily erased from a user's device, ensuring the central model no longer reflects their information in future updates, traces of past contributions may persist in the aggregated model. This technical hurdle directly conflicts with the spirit and enforceability of Article 17.
Consent Orchestration and Management
The distributed nature of FL creates a complex landscape for managing individual privacy preferences and obtaining valid consent. Traditional privacy frameworks were not designed for such decentralized systems.
Data Sovereignty Paradox: Data sovereignty in FL is distributed among multiple stakeholders: institutional controllers (e.g., hospitals, companies) who own the infrastructure and bear legal data protection obligations; individual data subjects (e.g., patients, users) who hold privacy rights over their personal information; and model recipients (e.g., researchers, service providers) who utilize the trained models. This multi-layered ownership can lead to a "principle-agent asymmetry," where current implementations might prioritize institutional consent through broad data use agreements, inadvertently marginalizing individual preferences and treating data subjects as passive sources rather than active participants with ongoing privacy rights.
Cross-border Complexity: When FL systems span multiple jurisdictions, conflicting privacy laws (e.g., GDPR's explicit consent requirements for European participants versus CCPA's opt-out standards for California residents) can create nearly impossible compliance situations. These regulatory gaps often compel FL operators to resort to broad institutional agreements, potentially bypassing granular individual preferences. Automated legal compliance engines that map data flows to applicable jurisdictions and adjust consent requirements are being explored as solutions.
Accountability and Interpretability (Article 5(2), Article 22)
The principles of accountability and the right to explanation for automated decisions pose distinct challenges for FL.
Accountability (Article 5(2)): Controllers must be able to demonstrate compliance with all GDPR principles. In FL, the distributed nature of training makes it difficult to maintain comprehensive records of processing activities across all participating clients and to precisely track the impact of individual data points on the global model. While FL can log user participation for audits , proving the precise lineage and influence of specific data points on the final model, especially after multiple aggregation rounds, is complex.
Interpretability (Article 22): GDPR Article 22 grants individuals the right not to be subject to decisions based solely on automated processing that produces legal or similarly significant effects, and implies a "right to explanation" for such decisions. FL's distributed model training can obscure interpretability, making it challenging for developers to fully understand how data shapes the model's decisions, as they do not have access to the full training dataset. This opacity can complicate regulatory audits and the provision of meaningful explanations to affected individuals.
Risks of Data Leakage from Model Updates
Despite not sharing raw data, FL systems are not entirely immune to privacy risks. The exchange of model parameters or gradients between clients and the central server can still leak sensitive information.
Inference Attacks: Adversaries can potentially infer sensitive information about the training data from analyzing the gradients or weights shared between devices and the central server. This includes model inversion attacks (reconstructing data from model outputs) and membership inference attacks (determining if a specific data point was part of the training set).
Model Poisoning Attacks: Malicious clients can upload designed model parameters to degrade the global model's accuracy or introduce biases, posing a security threat.
These vulnerabilities highlight that while FL significantly mitigates data centralization risks, it requires additional privacy-enhancing technologies to achieve robust protection against sophisticated attacks.
3.3. Legal Bases for Processing Personal Data in FL (Article 6)
For any processing of personal data to be lawful under GDPR, it must have a legal basis as outlined in Article 6. In the context of Federated Learning, determining the appropriate legal basis is crucial, especially given the distributed nature of data processing.
The primary legal bases that may be relevant for FL implementations include:
Consent (Article 6(1)(a)): Explicit consent is often considered the most stringent lawful basis, requiring a freely given, specific, informed, and unambiguous agreement from the data subject for the processing of their personal data for one or more specific purposes. For FL applications, blanket consent through general terms of service is usually insufficient. Organizations must clearly explain how local data will be used for AI model training, specify the types of automated processing, provide granular consent options, and enable easy withdrawal of consent with corresponding data removal from AI systems. While FL can simplify consent management by keeping data local , the dynamic and iterative nature of FL training necessitates dynamic consent mechanisms that can adapt over time.
Legitimate Interests (Article 6(1)(f)): Processing may be lawful if it is necessary for the purposes of the legitimate interests pursued by the controller or a third party, except where such interests are overridden by the interests or fundamental rights and freedoms of the data subject. This basis requires a careful balancing test, which can be challenged by data protection authorities. For FL, organizations might argue a legitimate interest in collaborative model improvement (e.g., for fraud detection or disease diagnosis) without centralizing sensitive data. However, this must be balanced against individual privacy rights, particularly if the processing involves sensitive data or leads to automated decisions with significant effects.
Performance of a Contract (Article 6(1)(b)): If the FL process is necessary for the performance of a contract to which the data subject is a party, or to take steps at the data subject's request prior to entering a contract, this basis may apply. This is more common in cross-device FL where user interaction directly drives model improvement (e.g., predictive text on a smartphone).
Compliance with a Legal Obligation (Article 6(1)(c)) or Public Interest (Article 6(1)(e)): These bases apply when processing is necessary for compliance with a legal obligation or for the performance of a task carried out in the public interest or in the exercise of official authority. This is particularly relevant in sectors like healthcare, where FL might be used for public health research or improving medical diagnostics under specific legal mandates. Each participating agency in a federated research endeavor must independently obtain an adequate legal basis, and the overarching project must collectively comply with these legal requirements.
The choice of legal basis heavily influences the transparency obligations and data subject rights that must be upheld. Regardless of the chosen basis, controllers must clearly document their rationale to demonstrate accountability.
Privacy-Enhancing Technologies (PETs) in Federated Learning
While Federated Learning inherently offers significant privacy advantages by keeping raw data local, it is not a complete privacy solution on its own. Model updates can still be vulnerable to inference attacks or data leakage. To address these residual privacy risks and strengthen GDPR compliance, FL systems are often augmented with various Privacy-Enhancing Technologies (PETs).
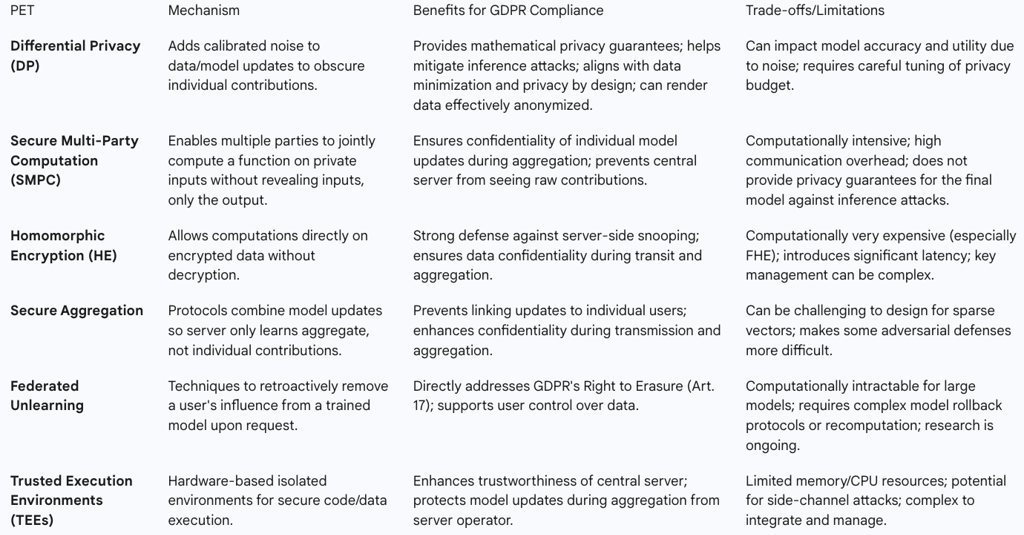
Differential Privacy (DP)
Differential Privacy (DP) is a technique that provides mathematical guarantees about the privacy of individual data points by strategically adding noise to the data or model updates. The core idea is to ensure that a single record does not significantly influence the output of a function, making it difficult to infer sensitive information about any individual participant from the aggregated model.
Mechanism: In FL, DP can be applied in two main ways:
Local DP: Clients add noise to their local model updates before sending them to the server. This provides strong privacy guarantees for individual contributions but can result in noisier updates and potentially impact model accuracy.
Central DP: The central server adds noise after aggregating updates. This generally offers better model utility but requires trust in the server not to infer individual contributions before noise is added.
Benefits for GDPR Compliance: DP helps mitigate inference attacks by making it harder to reconstruct raw data from model parameters. When used appropriately, differentially private data can even be considered anonymized, which significantly limits data protection risks. This aligns with GDPR's requirements for data protection by design and reducing the risk of re-identification.
Trade-offs/Limitations: Incorporating DP can impact the performance of the final model due to the introduced noise, creating a trade-off between privacy guarantees and model accuracy. Optimizing techniques like adaptive Gaussian clipping are researched to balance this trade-off.
Secure Multi-Party Computation (SMPC)
Secure Multi-Party Computation (SMPC) allows multiple parties to jointly compute a function on their private inputs without revealing the inputs themselves, only the output.
Mechanism: In FL, SMPC can be used to securely aggregate model updates. Clients encrypt their local updates, and the aggregation server performs computations directly on these encrypted values, ensuring that individual updates are never exposed to the central server or other clients. Only the final aggregated result is decrypted.
Benefits for GDPR Compliance: SMPC provides strong confidentiality guarantees for individual contributions during the aggregation process, preventing the central server from linking updates to specific users. This directly supports the integrity and confidentiality principle of GDPR.
Trade-offs/Limitations: SMPC is computationally intensive and can incur substantial overhead, potentially becoming a bottleneck for FL systems due to the additional encryption and decryption operations. Porting MPC protocols to cross-device settings is challenging due to communication requirements.
Homomorphic Encryption (HE)
Homomorphic Encryption (HE) is a cryptographic system that enables computations to be performed directly on encrypted data without the need for decryption.
Mechanism: In FL, clients can use HE to encrypt their local model updates (e.g., gradients) before uploading them. The central server then performs aggregation (e.g., weighted averaging) directly on these ciphertexts. The final aggregated result is the only part that needs to be decrypted.
Benefits for GDPR Compliance: HE provides a robust defense against server-side snooping, ensuring that even an inquisitive aggregator cannot access individual client updates during the aggregation process. This significantly enhances data confidentiality during transit and aggregation, aligning with GDPR's integrity and confidentiality requirements.
Trade-offs/Limitations: Fully Homomorphic Encryption (FHE) incurs substantial computational overhead, with operations being significantly slower (by an order of 1000) than computations on unencrypted data, making latency a crucial practical consideration. Hybrid strategies, combining HE with DP, are often used to balance privacy and efficiency. Questions also arise regarding who holds the secret key in HE schemes and how to achieve distributed HE.
Secure Aggregation and Federated Unlearning
Secure Aggregation Protocols (SAPs): These are specifically designed to combine model updates such that the central server learns only the aggregate function (typically the sum) of client values, without revealing individual contributions. This is a crucial technical safeguard that encrypts model updates during transmission, preventing servers from linking updates to individual users.
Federated Unlearning: This technique directly addresses the "right to erasure" challenge (Article 17) in FL. It aims to retroactively remove a user's influence from the aggregated model when consent is revoked or data is requested to be deleted. While computationally complex, especially for large models, solutions like model rollback protocols using Merkle trees to identify affected model versions and selectively retrain compromised branches are being explored to limit computational overhead while honoring erasure rights. Contribution tracking through cryptographic proofs and saving intermediate training states can also minimize retraining costs when consent revocations occur.
Role of Trusted Execution Environments (TEEs)
Trusted Execution Environments (TEEs) provide a secure, isolated environment within a processor where code and data can be loaded and executed with confidentiality, integrity, and attestation guarantees, even if the rest of the system is compromised.
Mechanism: In FL, TEEs can be used within a central server to increase its credibility by protecting the code and data loaded inside the enclave. This means that even the server operator cannot inspect the sensitive model updates or the aggregation process within the TEE.
Benefits for GDPR Compliance: TEEs can enhance the security and trustworthiness of the aggregation process, providing an additional layer of protection for model updates against malicious server operators. This contributes to the integrity and confidentiality of processing.
Trade-offs/Limitations: TEEs have limitations in terms of memory and CPU resources, which can restrict the complexity of the operations they can perform. Fully excluding side-channel attacks against TEEs remains a challenge, and partitioning FL functions across secure enclaves, cloud resources, and client devices is an open research question.
Table 2: Privacy-Enhancing Technologies in Federated Learning for GDPR Compliance
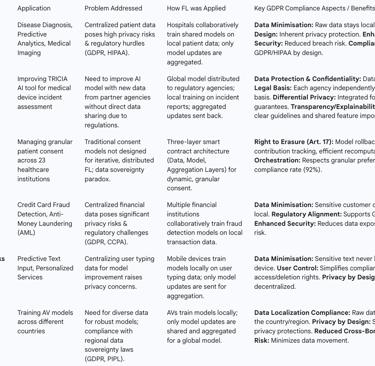
Real-World Applications and Case Studies
Federated Learning's ability to facilitate collaborative AI model training while preserving data privacy has made it particularly promising for industries dealing with highly sensitive or siloed data. Real-world applications in sectors like healthcare and finance demonstrate its potential to overcome regulatory hurdles and unlock new analytical capabilities.
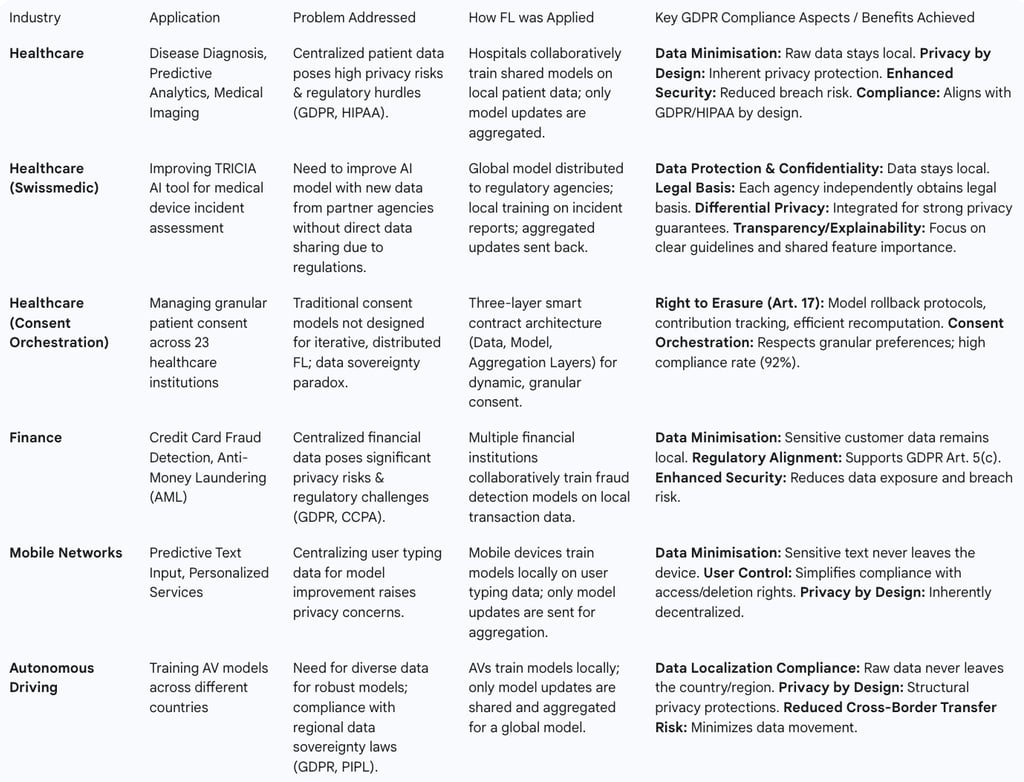
5.1. Healthcare Sector Implementations and Compliance Strategies
The healthcare sector, characterized by stringent data protection regulations like GDPR and HIPAA, stands to gain significantly from FL. Patient data, while crucial for advancements in personalized healthcare, is strictly regulated, posing major challenges for collecting and using large datasets in traditional centralized ML approaches. FL addresses these concerns by enabling secure collaboration among institutions without sharing sensitive patient data directly.
Disease Diagnosis and Predictive Analytics: A consortium of hospitals can train a shared model on their own patient data to enhance the diagnosis or prediction of certain diseases. This improves model generalization by incorporating diverse patient data from multiple institutions, enhancing the robustness of medical AI models, especially when local data is limited or fragmented.
Medical Imaging and Clinical Decision Support: FL is particularly beneficial in applications like medical imaging and clinical decision support, where patient confidentiality is paramount. It allows for the development of new drugs based on patient data or improved risk assessment without data centralization.
Case Study: Swissmedic's TRICIA Tool: Swissmedic, the Swiss Agency for Therapeutic Products, is leveraging FL to enhance TRICIA, an AI tool for assessing serious incident reports related to medical devices. The objective is to continuously improve TRICIA models using new data from partner regulatory authorities (e.g., FDA, Danish Medicines Agency) without direct data access.
Process: The global model is distributed to participating agencies, who train it locally on their new incident data. Local model versions are then aggregated by a central server to update the global model, which is redistributed for testing and use. This iterative process aims to continuously improve the model's ability to classify reports by severity.
GDPR Compliance Strategies: This implementation inherently supports GDPR by keeping sensitive health data local and only transmitting aggregated model updates. Beyond data security, it emphasizes the need for each participating agency to independently establish a valid legal basis for processing (e.g., explicit consent, legal necessity) and for the overarching federated endeavor to collectively comply with GDPR requirements. Differential privacy is integrated to protect data during training, providing strong privacy guarantees by adding noise to local model updates. Model security against adversarial attacks is addressed through techniques like differential data protection and TLS via Multi-Party Computation. Transparency and explainability are also crucial, requiring clear guidelines for FL use and interpretation of outcomes, potentially through securely shared feature importance scores.
Consent Orchestration in Healthcare (23 Institutions): A HIPAA-compliant federated learning system demonstrated effective consent orchestration and GDPR compliance across 23 healthcare institutions. This system used a three-layer smart contract architecture:
Data Layer Contracts: Governed access to local data based on current consent states, immediately blocking access if consent was revoked.
Model Layer Contracts: Adjusted privacy-preserving mechanisms (e.g., differential privacy) based on granular consent preferences, allowing more detailed contributions for broader consent.
Aggregation Layer Contracts: Determined which model updates could be included in the global model, excluding those from participants whose consent was revoked or who disagreed with research purposes.
Results: After 18 months, the system achieved a 92% consent compliance rate, 18% faster model convergence due to incentives, and a negligible 0.34% accuracy loss from privacy-preserving techniques, demonstrating the feasibility of comprehensive consent orchestration at scale.
5.2. Financial Sector Applications for Fraud Detection and Risk Assessment
The financial sector, with its high volume of sensitive transaction data and strict regulations, also benefits significantly from FL. FL enables financial institutions to collaborate on developing robust models without compromising client privacy or violating financial regulations.
Fraud Detection: FL is a promising solution for credit card fraud detection and anti-money laundering (AML). Multiple financial institutions can collaboratively train fraud detection mechanisms on their local transaction data, enhancing real-time threat resilience. This avoids the privacy risks and regulatory challenges associated with centralizing sensitive financial information.
Risk Assessment: FL can be used for privacy-preserving risk assessment, allowing multiple financial institutions to collaboratively train models without sharing raw data.
Case Study: Privacy-Preserving Fraud Detection in Digital Banking: Research demonstrates that FL can effectively detect fraudulent transactions while ensuring data privacy by keeping raw data localized across financial institutions.
Performance: FL achieves near-parity performance with centralized models in terms of accuracy, precision, and recall, while significantly enhancing data privacy and proving resilient to data heterogeneity and communication constraints.
GDPR Alignment: This application aligns with GDPR Article 5(c) (data minimisation) by training models without centralizing raw data, offering a structural compliance advantage and reducing legal liability associated with data transfers and breaches.
Remaining Challenges: Full compliance is not automatic. GDPR's Article 22 (explainability) remains a challenge, as FL's distributed training can obscure interpretability, complicating regulatory audits. Similarly, opt-out mechanisms (e.g., CCPA) could impact training data completeness and model performance. To fully meet legal expectations, FL implementations require supplementary compliance auditing tools, consent management systems, and explainable AI modules.
5.3. Broader Industry Use Cases and Privacy Considerations
Beyond healthcare and finance, FL holds promise across various other sectors:
Retail and Manufacturing: Retailers can use FL to track sales and inventory across multiple locations without revealing customer data, optimizing stock levels. Manufacturers can aggregate data from different parts of the supply chain to optimize logistics.
Urban Management: FL can contribute to smart city initiatives by processing data from distributed sensors and devices while maintaining citizen privacy.
Autonomous Driving: FL enables collaborative model training across different countries for autonomous vehicles, preserving data privacy and complying with regional regulations like GDPR and PIPL.
Mobile Networks: FL improves personalization on user devices (e.g., predictive text input) while building trust through data privacy, as sensitive information remains on the device.
Table 3: Federated Learning Case Studies: Industry, Application, and GDPR Alignment
Regulatory Guidance and Best Practices for FL under GDPR
The evolving landscape of Federated Learning necessitates clear regulatory guidance and the adoption of best practices to ensure robust GDPR compliance. Data protection authorities are actively engaging with this technology, recognizing its potential while also identifying areas requiring careful attention.
6.1. Perspectives from the European Data Protection Board (EDPB)
The European Data Protection Board (EDPB), as the body responsible for ensuring consistent application of the GDPR across the EU, has begun to address AI and data protection, including FL. The EDPB and the European Data Protection Supervisor (EDPS) acknowledge FL as a potential solution for developing machine learning models that require large or very dispersed datasets while enhancing data protection.
The EDPB has highlighted the positive impacts of FL on data protection, including:
Decentralization: By leveraging distributed datasets, FL avoids data centralization, allowing parties to maintain better control over the processing of their personal data.
Data Minimisation: FL reduces the amount of personal data transferred and processed by third parties for machine learning model training.
International Cooperation: When shared parameters are anonymous, FL can facilitate the training of models with data from different jurisdictions, potentially simplifying cross-border data transfer complexities.
However, the EDPB also points out negative foreseen impacts and open issues, such as:
Interpretability: FL can reduce the interpretability of models, as developers do not have access to the full training dataset.
Fairness: Some FL settings may introduce bias towards parties with more common model types.
Security Issues: The distributed nature of FL can facilitate certain types of attacks, like model poisoning, and classic defense mechanisms may not be sufficient. There is a need for efficient implementation of PETs to avoid information leakages from shared model parameters.
The EDPB is actively working to address the critical shortage of skills in AI and data protection, launching projects to provide training material for legal and technical professionals. This indicates a recognition of the complex interplay between AI technologies like FL and the need for a skilled workforce to ensure compliance.
6.2. Guidance from the Information Commissioner's Office (ICO)
The UK's Information Commissioner's Office (ICO) has also recognized Federated Learning as a Privacy-Enhancing Technology (PET) that can help organizations achieve compliance with data protection law, particularly the UK GDPR.
Key aspects of the ICO's perspective include:
Data Minimisation and Privacy by Design: The ICO emphasizes that processing data locally, as in FL, aligns with the legal requirement of data minimisation and data protection by design and by default. This helps organizations comply with the UK GDPR, reduces the risk of data breaches, and can simplify contractual requirements.
Anonymisation: The ICO notes that when used appropriately, differentially private data can be considered anonymized, which limits data protection risks from inappropriate disclosure of personal data.
Reduced Data Transfer Risks: FL removes the need to transfer large amounts of training data to a central database, significantly mitigating risks associated with transferring and centrally storing data. This can simplify regulatory considerations and reduce legal costs in the long term.
Reputational Benefits: The ICO suggests that regulators may look favorably on organizations that prioritize privacy, and the use of FL can offer substantial improvements in data security and privacy, potentially leading to reputational benefits.
Collaboration with Government: The ICO and the Department for Science, Innovation and Technology (DSIT) are collaborating to support organizations in assessing the costs and benefits of adopting FL and other PETs, indicating an ongoing effort to provide practical resources.
Overall, the ICO views FL as an architectural approach that requires upfront investment but, once operational, leads to efficiencies and greater security by reducing the need for central data storage or sharing.
6.3. Importance of Data Protection Impact Assessments (DPIAs) for FL
Data Protection Impact Assessments (DPIAs) are a mandatory requirement under GDPR for processing activities that are likely to result in a high risk to individuals' rights and freedoms. Given the complexities and potential risks associated with AI systems, especially those processing personal data, DPIAs are crucial for FL implementations.
Risk Assessment: A DPIA for FL should thoroughly assess potential data leakage through model updates, even without direct access to raw data. It should evaluate vulnerabilities to inference and poisoning attacks and the effectiveness of integrated PETs.
Privacy by Design and Default: The DPIA process encourages the implementation of system architectures that prioritize data protection by design and by default. It ensures that data access among federated parties is carried out while balancing the level of risk of the processing, accuracy, and usefulness of the resulting model.
Proportionality and Sensitive Data: For FL systems processing special categories of personal data (Article 9 GDPR), a DPIA is essential to assess proportionality and ensure robust safeguards. The local processing and lack of direct data sharing in FL can help reduce risks for individuals' rights and freedoms, potentially leading to a more positive assessment of proportionality in the DPIA.
Accountability Documentation: Conducting a DPIA contributes to the accountability principle by documenting the measures taken to comply with GDPR, including the rationale for design choices and risk mitigation strategies.
6.4. Recommendations for Robust FL System Design and Governance
To ensure robust GDPR compliance in Federated Learning systems, organizations should adopt a multi-faceted approach encompassing technical design, legal strategy, and ongoing governance.
Prioritize Privacy by Design: Integrate privacy protections from the earliest stages of FL system design. This includes choosing decentralized architectures where appropriate and implementing PETs as core components, not as add-ons.
Implement Comprehensive PETs: Combine FL with robust PETs such as Differential Privacy (for statistical privacy guarantees), Secure Multi-Party Computation or Homomorphic Encryption (for secure aggregation), and Secure Aggregation protocols. These technologies are necessary to address vulnerabilities like inference attacks and data leakage from model updates.
Address the Right to Erasure Proactively: Implement "federated unlearning" techniques or model rollback protocols to enable the removal of a data subject's influence from the global model upon request. This requires sophisticated contribution tracking and efficient recomputation mechanisms.
Develop Granular Consent Orchestration: Move beyond broad institutional agreements to implement dynamic, multi-layered consent mechanisms that respect individual preferences. This may involve smart contracts or blockchain-anchored consent management systems that can adapt to iterative training and cross-border complexities.
Ensure Transparency and Explainability: Provide clear, concise, and accessible information to data subjects about how their local data contributes to the global model and how automated decisions are made. While full algorithmic transparency can be challenging, focus on explaining the logic involved and potential consequences. Tools for compliance auditing and explainable AI modules are essential.
Conduct Thorough DPIAs: Mandatorily perform Data Protection Impact Assessments for FL processing activities, especially those involving sensitive data or high-risk applications. These assessments should be comprehensive, evaluating risks and mitigation strategies throughout the FL lifecycle.
Establish Clear Legal Bases: Carefully determine and document the appropriate legal basis for processing personal data under Article 6 GDPR for all aspects of the FL system.
Implement Robust Security Measures: Beyond PETs, ensure comprehensive cybersecurity, physical, and organizational security measures to protect against unauthorized or unlawful processing and accidental data loss. This includes robust adversarial defenses against model poisoning and inference attacks.
Foster Interdisciplinary Collaboration: Recognize that FL compliance requires expertise from both legal and technical domains. Promote collaboration between DPOs, legal counsel, machine learning engineers, and cybersecurity professionals.
Future Outlook and Open Problems
Federated Learning is a rapidly evolving field, and while it offers significant advancements in privacy-preserving AI, several open problems and future directions remain to fully realize its potential and ensure comprehensive regulatory compliance.
7.1. Addressing Data and System Heterogeneity
The real-world characteristic of data heterogeneity (non-IID data) and system heterogeneity (varying client capabilities) remains a fundamental challenge for FL.
Non-IID Data: Real-world FL datasets often exhibit a mixture of feature distribution skew, label distribution skew, concept drift, concept shift, and quantity skew. These imbalances can lead to slower model convergence and performance disparities. Future research needs to better characterize these cross-client differences and develop more effective mitigation strategies tailored to various non-IID regimes. Personalized FL models, advanced aggregation techniques like FedProx or clustered FL, and adaptive local training are promising avenues.
System Heterogeneity: Devices participating in FL often have diverse computing capacities, energy availability, and network connectivity. This variability can lead to "system induced bias" if device availability is correlated with data distribution. Developing robust training methods that account for these varying capabilities and ensure fair contributions from all clients is crucial.
7.2. Enhancing Robustness Against Adversarial Attacks
Despite the privacy benefits, FL systems are vulnerable to various adversarial attacks, including model poisoning (injecting malicious data or updates) and inference attacks (reconstructing sensitive information from model parameters).
Adaptive Defenses: Quantifying the susceptibility of FL models to specific attacks and designing new adaptive defenses is an ongoing area of research. While Byzantine-resilient aggregation methods exist, their effectiveness under all learning problem assumptions needs further empirical analysis.
Privacy-Preserving Defenses: A significant challenge lies in developing defenses that do not compromise the privacy guarantees provided by PETs. For instance, secure aggregation can make certain defenses more difficult. Future work will focus on developing computation- and communication-efficient range proofs compatible with secure aggregation.
Detecting Collusion: Defending against colluding adversaries or detecting them without direct inspection of node data remains a complex problem.
7.3. Evolving Consent Models and Participatory Governance
Traditional consent models are often inadequate for the iterative and dynamic nature of FL, where training happens continuously over extended periods.
Dynamic Consent: The development of dynamic consent mechanisms is essential to address this temporal challenge, allowing individuals to manage their privacy preferences on an ongoing basis.
Blockchain-Anchored Consent Management: Integrating blockchain with FL can enhance security and transparency for consent records, ensuring they remain tamper-proof and auditable.
Participatory Governance: Moving towards community-driven consent standards and participant voting on acceptable research uses and privacy trade-offs represents a future direction for truly consensual AI. This shift would empower data subjects as active participants rather than passive data sources.
Cross-Border Legal Compliance: Automated legal compliance engines that can map data flows to applicable jurisdictions and adjust consent requirements accordingly will be critical for FL systems operating across multiple countries with conflicting privacy laws.
7.4. Emerging Technologies and Regulatory Adaptation
The rapid pace of technological advancement, particularly in areas like quantum computing, will continue to shape the future of FL and its regulatory landscape.
Quantum-Resistant Cryptography: As quantum computing threatens current cryptographic methods, consent systems and PETs must evolve to incorporate quantum-resistant solutions like lattice-based cryptography and quantum-resistant blockchain protocols. Fully homomorphic encryption, while computationally intensive, is also a key area for enabling complete privacy throughout the training process.
AI Act and Sector-Specific Regulations: While FL itself is not explicitly regulated by new frameworks like the EU AI Act, its use in AI systems will be subject to the Act's provisions, potentially classifying it as a high-risk product requiring strict adherence to protocols. This necessitates ongoing adaptation and interpretation of existing and new regulations to specific FL contexts.
User Perception and Trust: Making the benefits and limitations of FL intuitive to average users and understanding their privacy needs for particular analysis tasks remains an important open question. Building trust through transparent and ethically designed FL systems will be crucial for broader adoption and societal benefit.
Conclusion
Federated Learning stands as a pivotal advancement in machine learning, offering a compelling solution to the pervasive challenge of data silos and privacy concerns in the age of data-intensive AI. Its core principle of keeping raw data decentralized and exchanging only model updates inherently aligns with fundamental GDPR principles, particularly data minimisation and privacy by design. This architectural advantage significantly reduces the risks associated with centralized data storage and transfer, making FL a powerful enabler for collaborative AI development in highly regulated sectors like healthcare and finance.
However, the analysis reveals that while FL provides a robust foundation for privacy, it is not a panacea for all GDPR compliance requirements. Significant challenges persist, most notably concerning the intricate "right to erasure" (Article 17), the complexities of dynamic consent orchestration across diverse stakeholders and jurisdictions, and the demands for robust accountability and model interpretability (Article 5(2), Article 22). The potential for data leakage through sophisticated inference attacks on model updates also necessitates additional safeguards.
To bridge these gaps and achieve comprehensive GDPR compliance, the strategic integration of Privacy-Enhancing Technologies (PETs) is indispensable. Differential Privacy offers mathematical guarantees against individual data inference, while Secure Multi-Party Computation and Homomorphic Encryption provide robust confidentiality during model aggregation. Furthermore, the development of federated unlearning techniques and advanced consent management systems, potentially leveraging smart contracts and blockchain, is crucial for upholding data subject rights in a dynamic FL environment.
Regulatory bodies such as the EDPB and ICO acknowledge FL's privacy-preserving potential and emphasize the necessity of thorough Data Protection Impact Assessments (DPIAs) and adherence to best practices. Their guidance underscores that FL, when properly implemented with appropriate technical and organizational measures, can indeed be a more robust and future-proof approach to AI development, fostering trust and enabling valuable cross-organizational collaboration.
In conclusion, Federated Learning represents a critical step towards ethical AI development. Its successful deployment under GDPR requires a nuanced understanding of its inherent strengths and limitations. Organizations must commit to a multi-layered compliance strategy that combines FL's decentralized architecture with advanced PETs, robust governance frameworks, and a continuous focus on transparency and data subject empowerment. The ongoing research into addressing data heterogeneity, enhancing adversarial robustness, and evolving consent models will further solidify FL's role as a cornerstone of privacy-preserving AI, ensuring that technological innovation proceeds in harmony with fundamental data protection rights.