Navigating GDPR Compliance in the AI Era
Explore how GDPR regulations impact AI and machine learning development, implementation, and operations with practical compliance strategies for businesses in 2025.


The rapid advancement and widespread adoption of Artificial Intelligence (AI) systems have introduced unprecedented complexities in the realm of personal data processing. AI's inherent reliance on vast datasets for training and operation creates a critical intersection with the General Data Protection Regulation (GDPR), which is fundamentally designed to protect personal data and individual privacy rights. This report aims to dissect this intricate relationship, providing a robust framework for organizations to navigate GDPR compliance effectively in the evolving AI landscape.
The significance of GDPR compliance extends far beyond merely avoiding substantial financial penalties, which can reach up to €20 million or 4% of a business's annual global turnover, whichever is higher. Adhering to these principles is paramount for cultivating customer trust, safeguarding an organization's reputation, and meeting comparable requirements increasingly imposed by major technology platforms, particularly those related to advertising.
The geopolitical landscape further complicates this dynamic. The global competition to lead in AI development, often referred to as the "AI race," necessitates borderless access to data for optimal system and model performance. Simultaneously, this pursuit contributes to increased regulatory fragmentation worldwide. Privacy and data protection laws, including the GDPR, serve as the foundational legal framework for AI regulation in numerous regions. This interconnectedness underscores that data protection is not merely an adjacent regulatory concern for AI but a core component that underpins and shapes its development and deployment, particularly concerning personal data. The EU AI Act explicitly clarifies that the GDPR always applies when personal data is processed by AI systems. This establishes a paradigm where organizations cannot treat AI compliance as distinct from data protection; rather, data protection is a fundamental element of responsible AI, demanding an integrated compliance strategy from the outset. This proactive approach means that adherence to GDPR principles can inherently address many emerging ethical concerns related to AI.
I. Foundational Principles: GDPR in the AI Context
A. Core GDPR Principles and their Application to AI
The GDPR's seven core principles form the bedrock for lawful and ethical data processing, and their rigorous application to AI systems is indispensable. Each principle presents unique considerations when applied to the data-intensive and often opaque nature of AI.
Lawfulness, Fairness, and Transparency: AI systems must operate on a clear legal basis for processing personal data. This necessitates having valid legal grounds, such as informed consent from the data subject, the performance of a contract with the data subject, or a legitimate interest pursued by the organization. Transparency mandates that organizations openly disclose how data is collected, used, and secured. This requirement applies equally to data utilized for training AI models as it does to data processed in model output or inferences. Individuals retain the fundamental right to understand how decisions affecting them are made, especially when AI is involved.
Purpose Limitation: Personal data must be collected for specific, explicit, and legitimate purposes. AI systems are prohibited from reusing personal data for unrelated tasks without obtaining further consent or establishing a new, valid justification. This principle is critical in preventing "function creep," a scenario where data initially collected for one purpose is gradually utilized for others without proper authorization. Organizations are obligated to define these purposes clearly and inform users at the time of data collection.
Data Minimization: Organizations should process only the data strictly necessary for the intended task. This poses a significant challenge for AI, which often thrives on and benefits from large datasets for effective training and performance. However, over-collection of data not only escalates privacy risks but also complicates compliance efforts. A careful assessment of data importance is therefore crucial to avoid violating data protection regulations.
Accuracy: AI outputs must be predicated on accurate, complete, and up-to-date personal data. Poor data quality can result in harmful or biased outcomes, which directly undermines GDPR compliance and erodes public trust in AI systems. Regular data validation, cleansing, and continuous monitoring are essential practices to uphold data accuracy.
Storage Limitation: Personal data should not be retained for longer than is necessary for its original purpose. This principle directly impacts how long organizations can retain and reuse AI training datasets containing personal data. Organizations must implement defined retention periods and either delete or anonymize personal data once it is no longer required for its original purpose. Indefinite data retention significantly increases privacy and legal risks.
Integrity and Confidentiality: This principle mandates that personal data is protected against unauthorized access, alteration, or loss. Implementing robust security measures, such as encryption, access controls, and regular audits, is crucial. These measures should be proportionate to the sensitivity and volume of data processed. Employee training and penetration tests further strengthen data protection.
Accountability: Organizations must assume responsibility for complying with all data protection principles and be able to demonstrably prove that compliance. This includes clearly assigning responsibility for explainability requirements within AI systems and ensuring a designated human point of contact is available for individuals to query decisions. Maintaining comprehensive audit trails and detailed technical documentation of AI models, including training methodologies and data sources, is essential for demonstrating accountability.
The application of these principles to AI reveals inherent points of tension that serve as clear indicators of potential compliance risks. AI systems, by their nature, often demand extensive data for optimal performance and can operate as "black boxes" where decision-making processes are not easily deciphered. This fundamental characteristic directly conflicts with GDPR's core tenets of data minimization, purpose limitation, and transparency. These areas of conflict are not mere inconveniences but represent the primary domains where organizations are most susceptible to compliance failures and regulatory scrutiny. Therefore, these "tension points" function as predictive indicators of high-risk areas in AI development and deployment. Organizations should proactively allocate significant resources and attention to addressing these specific challenges, as a failure to do so systematically will likely result in substantial penalties and reputational damage.
B. Legal Bases for Processing Personal Data in AI Systems
Selecting the appropriate legal basis is a foundational requirement for the lawful processing of personal data within AI systems. The GDPR provides six legal bases, and data controllers must validly utilize and meticulously document at least one for any processing activity.
Informed Consent: This legal basis requires explicit and unambiguous agreement from the data subject, which can be withdrawn at any time. For AI systems, particularly those that integrate personal data into their training models, relying on consent poses significant challenges. The withdrawal of consent can create serious difficulties, especially if the data cannot be fully removed or "unlearned" from the model post-withdrawal. Continued use of data after consent withdrawal risks direct non-compliance with GDPR.
Contractual Necessity: This basis is applicable when the processing of personal data is strictly necessary to perform a contract with the data subject or to deliver a service they have explicitly signed up for. For instance, if an AI system provides a specific functionality that requires certain personal data for its operation, contractual necessity may be a valid basis. However, if the data is subsequently reused for purposes such as general model training or analytics beyond the agreed undertakings or service delivery, this legal basis may no longer be relied upon.
Legitimate Interest: This legal basis is frequently considered for purposes such as improving and training AI models, analyzing service and system performance, or enhancing the user interface. However, data subjects retain the right to object to processing based on legitimate interest. In such cases, organizations must demonstrate a compelling justification for further data processing that clearly outweighs the individual's rights and freedoms. This evaluation necessitates a case-by-case assessment, which becomes particularly challenging when sensitive personal data is involved. The European Data Protection Board (EDPB) emphasizes a rigorous three-step test for assessing legitimate interest: (1) identifying the legitimate interest pursued, (2) analyzing the necessity of the processing (ensuring no less intrusive means are available and the amount of data is proportionate), and (3) conducting a balancing test that carefully considers the data subjects' reasonable expectations and potential risks. Simply fulfilling basic transparency obligations under GDPR Articles 13 and 14 may not suffice to ensure that data subjects can reasonably expect their data to be processed in the context of complex AI models.
The inherent fragility of consent and legitimate interest as legal bases for AI development and deployment is a critical consideration for long-term compliance. The dynamic nature of these legal bases, where consent can be revoked and legitimate interests can be challenged, clashes significantly with the often static or deeply embedded nature of AI training data. This creates considerable legal instability and operational risk for organizations. If an AI model is trained on data collected via consent, and that consent is later withdrawn, the technical challenge of removing the influence of that specific data point from the model without rebuilding it from scratch can be immense. Similarly, relying on legitimate interest for continuous model improvement becomes precarious if data subjects frequently object, necessitating a constant re-evaluation of the balancing test.
This situation compels organizations to strategically prioritize legal bases that offer greater long-term stability for AI development. This includes leveraging truly anonymized data, which falls outside the scope of GDPR entirely , or relying on contractual necessity where data use is strictly defined and demonstrably essential for delivering a contracted service. Where consent or legitimate interest are unavoidable, organizations must implement robust mechanisms for exercising data subject rights, such as effective erasure and objection procedures, and deploy privacy-enhancing technologies (PETs) that facilitate data removal or anonymization. These measures become even more critical to mitigate the inherent fragility of these legal bases for AI.
II. Key Compliance Challenges and Tensions in the AI Era
A. The "Black Box" Problem: Transparency and Explainability (Article 22 GDPR)
Many advanced AI models, particularly those employing deep learning techniques, are inherently difficult to interpret, leading to what is commonly known as the "black box" problem. This opacity directly conflicts with the GDPR's fundamental transparency requirements and an individual's right to understand how decisions affecting them are made, a principle emphasized in Recital 71 of the GDPR.
Organizations face the challenge of implementing measures to increase algorithmic transparency without compromising the system's performance. This involves providing explanations that are meaningful, truthful, and presented in an appropriate and timely manner to the affected individuals. The Information Commissioner's Office (ICO) in the UK stresses the importance of openly communicating the use of AI, proactively informing individuals about AI-enabled decisions, and delivering clear explanations. There are ongoing efforts within the AI community to design "white box" algorithms that offer greater interpretability, aiming to demystify the decision-making processes of AI systems.
Furthermore, Article 22 of the GDPR grants individuals the right not to be subjected to decisions based solely on automated processing, including profiling, which produces legal effects concerning them or similarly significantly affects them. This applies to critical applications such as credit scoring, job application filtering, and predictive policing. When such automated decisions are permitted under specific exceptions, suitable safeguards must be implemented. These safeguards include the individual's right to obtain human intervention, to express their point of view, and to contest the decision made about them. Individuals also have the right to receive meaningful information about the logic involved in automated decision-making and its envisaged consequences, as per Article 15(1)(h) of the GDPR.
The requirement for explainability in AI extends beyond a mere legal obligation; it functions as a multi-stakeholder imperative. While legally mandated by GDPR (Recital 71, Article 22) and further reinforced by the EU AI Act's emphasis on transparency and human oversight for high-risk systems , explainability is not solely about avoiding regulatory penalties. It is fundamental for building and maintaining user trust, ensuring fairness in outcomes, and enabling effective human oversight. The process of achieving explainability transforms from a simple compliance checkbox into a cornerstone of ethical AI design and operational integrity. This necessitates close collaboration between legal experts who understand regulatory demands, technical teams capable of extracting and simplifying algorithmic logic, and communication specialists who can translate complex technical details into understandable terms for diverse audiences. Organizations that proactively invest in explainable AI are not just fulfilling their legal duties; they are developing more robust, trustworthy, and socially acceptable AI systems. This strategic approach can lead to significant competitive advantages and mitigate long-term risks, such as public backlash or costly regulatory interventions, effectively shifting the perception of explainability from a compliance cost to a strategic value driver.
B. Data Hunger vs. Data Minimization and Purpose Limitation
A fundamental tension exists between the operational requirements of sophisticated AI systems and the core principles of GDPR. Advanced AI models often necessitate vast volumes of training data to function effectively and achieve optimal performance. This inherent "data hunger" directly conflicts with GDPR's data minimization principle, which dictates that organizations should process only the data strictly necessary for the task.
Organizations are therefore compelled to find a delicate balance between acquiring sufficient training data for their AI models and adhering to the principle of minimal data collection. Over-collection of personal data not only amplifies privacy risks but also significantly complicates compliance efforts, making it harder to manage and secure the data effectively.
Complementing data minimization, the principle of purpose limitation mandates that personal data must be collected for specific, explicit, and legitimate purposes. This means that data should not be reused for unrelated tasks without obtaining additional consent or establishing a new, valid legal basis. This principle is crucial in preventing "function creep," where data initially gathered for one purpose gradually begins to be used for other, unauthorized purposes.
The tension between AI's demand for extensive data and GDPR's data minimization principle forces a paradigm shift towards a "data efficiency imperative." This implies that AI developers must innovate to achieve high model performance with a reduced volume of personal data, or by utilizing data that is less identifiable. This strategic necessity encourages the exploration and adoption of advanced techniques that extract maximum value from minimal datasets, or leverage privacy-preserving methods to train models without directly exposing sensitive personal information. Organizations that master this data efficiency in their AI development will gain a significant competitive advantage. This approach not only reduces the burden of compliance and lowers the risk of data breaches but can also lead to decreased storage and processing costs. Furthermore, it encourages the adoption of privacy-enhancing technologies (PETs) as a strategic necessity rather than merely a compliance tool, fostering more responsible and sustainable AI practices.
C. Bias, Accuracy, and Fairness in AI Outputs
The quality of AI algorithms is inextricably linked to the data on which they are trained. If the data used is inaccurate, incomplete, or inherently biased, the decisions generated by AI systems can perpetuate and even amplify these errors, leading to harmful or discriminatory outcomes for individuals.
Under the GDPR, personal data must be accurate and kept up-to-date. Individuals also have the fundamental right to request that inaccurate data concerning them be rectified, as stipulated in Article 16 of the GDPR. If an AI system makes decisions based on biased or incorrect data, this directly undermines the accuracy principle and can result in significant non-compliance.
Ensuring that AI systems maintain accurate data while simultaneously preventing discriminatory outcomes requires ongoing monitoring and dedicated mitigation efforts. Implementing robust testing protocols is essential to identify and address potential biases in AI outputs proactively, before they have an impact on individuals. The concept of fairness is not only a core principle embedded within the GDPR but is also explicitly enshrined as a fundamental AI ethics principle in the EU AI Act.
The presence of algorithmic bias in AI systems is not merely an ethical concern; it represents a systemic compliance failure under the GDPR. Such bias directly violates the accuracy principle and broader fairness requirements, leading to discriminatory outcomes that can have profound legal effects on individuals. The progression from flawed input data to biased AI outputs and then to discriminatory decisions highlights a breakdown in sound data governance and AI development practices. Addressing algorithmic bias therefore requires a holistic approach that spans the entire AI lifecycle. This begins with meticulous data collection and curation, ensuring datasets are representative and of high quality, and extends through careful model design, rigorous testing, and continuous monitoring of AI system performance in real-world applications. This comprehensive approach necessitates the involvement of interdisciplinary teams, including data scientists, ethicists, and legal experts, to proactively identify and mitigate bias, moving beyond a reactive stance to discriminatory outputs.
D. Navigating Data Subject Rights in AI Systems
The GDPR grants individuals several fundamental rights concerning their personal data, including the right to access (Article 15), the right to rectification (Article 16), the right to erasure (Article 17), and the right to data portability (Article 20), as well as the right to object to processing.
A significant challenge arises when personal data is deeply embedded within AI training data or model outputs. In such scenarios, ensuring the effective exercise of these data subject rights can be technically complex. For instance, fulfilling an erasure request (the "right to be forgotten") when the data has been used to train a complex AI model is far more intricate than simply deleting a record from a database.
To address these complexities, organizations need to establish robust data management practices. This includes maintaining a comprehensive inventory of all data used for AI training and creating clear, documented processes for individuals to exercise their rights. Data lineage tools can be particularly helpful, as they can trace how data flows through an AI system, making it easier to locate and, where necessary, erase specific data points. Furthermore, incorporating mechanisms that allow users to easily exercise their rights, such as self-service data portals, can significantly streamline compliance efforts. The European Data Protection Board (EDPB) has indicated that in AI contexts, the right to erasure might be "expanded" even to situations that do not strictly meet the criteria of Article 17(1), and has also mentioned a "premature right to object" that could be exercised before data processing even takes place.
This regulatory stance highlights an "unlearning imperative" and its position at the technical and legal frontier. The observation that data subject rights, particularly the right to erasure, become technically complex when data is deeply embedded in AI models is compounded by the EDPB's suggestion of expanded rights in AI contexts. This means that the regulatory expectation for data removal or influence mitigation is pushing the boundaries of what is currently technically feasible in AI. The ability to remove the influence of specific data points from a trained AI model without requiring a complete retraining from scratch, often referred to as "machine unlearning," is an emerging and significant technical hurdle. Organizations must therefore consider investing in research and development of unlearning techniques or adopting AI architectures that inherently facilitate the removal of data influence. This also underscores the need for greater legal clarity on what constitutes "effective erasure" in the context of complex, interconnected AI models, as simply deleting raw training data may not fully eliminate its impact on the model's behavior or outputs. This area represents a critical nexus for future regulatory guidance and technological innovation.
E. Automated Decision-Making and Profiling (Article 22 GDPR)
Article 22 of the GDPR provides individuals with a crucial right: not to be subject to a decision based solely on automated processing, including profiling, if that decision produces legal effects concerning them or similarly significantly affects them. This provision is highly relevant to various AI applications, such as automated credit scoring, filtering of job applications, and predictive policing systems, where AI-driven decisions can have profound impacts on individuals' lives.
This general prohibition on solely automated decisions has limited, specific exceptions: (1) where the decision is necessary for entering into, or the performance of, a contract between the data subject and a data controller; (2) where it is authorized by Union or Member State law that also lays down suitable measures to safeguard the data subject's rights and freedoms and legitimate interests; or (3) where it is based on the data subject's explicit consent.
Even when one of these exceptions applies, suitable safeguards must be implemented to protect the data subject's rights and freedoms. These safeguards include the right to obtain human intervention on the part of the controller, the right to express one's point of view, and the right to contest the automated decision. Furthermore, individuals have the right to receive meaningful information about the logic involved in the automated decision-making process and its envisaged consequences, as outlined in Article 15(1)(h) of the GDPR.
A recent decision by the Court of Justice of the European Union (CJEU) in the SCHUFA case provided important clarification on the scope of Article 22. The ruling indicated that even a service provider, such as a credit reference agency, that provides critical automated decision-making support to a third party (e.g., a bank) may be caught by Article 22. This applies if the AI-generated output from the service provider, such as a credit score, leads "in almost all cases" to a significant decision by the third party, like the refusal of a loan. This interpretation significantly expands the scope of accountability beyond the direct entity making the final pronouncement. Human oversight is also a specific requirement of the EU AI Act for high-risk systems, complementing the GDPR's Article 22 provisions.
The SCHUFA case establishes a "de-facto decision-maker" principle, extending accountability for automated decisions beyond the immediate entity that issues the final pronouncement. The original understanding of Article 22 focused on decisions "based solely on automated processing" that "significantly affect" individuals. However, the CJEU's clarification means that an organization providing AI-powered insights or scores to another entity can be deemed the "decision-maker" if its output consistently and overwhelmingly dictates a significant decision made by that other entity. This broadens the scope of Article 22, requiring AI developers and providers to assess the real-world, downstream impact of their models, not just their direct application. It mandates a deeper understanding of how their AI outputs are utilized by clients and necessitates the implementation of contractual agreements that ensure clients integrate the necessary human oversight and data subject rights safeguards. This also implies increased due diligence for organizations integrating third-party AI solutions, as they too may inherit accountability for the automated decisions facilitated by those solutions.
III. Strategic Compliance Frameworks and Best Practices for AI
A. Privacy by Design and by Default (Article 25 GDPR)
Article 25 of the GDPR mandates that data protection measures are embedded into the entire lifecycle of an organization's products, services, applications, and business processes from the very outset. This principle ensures that privacy is a proactive consideration, rather than a reactive afterthought.
Privacy by Design requires that appropriate technical and organizational measures are implemented to ensure personal data security and privacy are built into the system from its inception. This includes technical measures such as pseudonymization and data minimization, which help to reduce the identifiability and volume of personal data processed.
Privacy by Default ensures that, by default, only the personal data strictly necessary for each specific purpose of the processing is collected, stored, or processed. Furthermore, it dictates that personal data should not be made accessible to an indefinite number of natural persons without the individual's explicit intervention. This obligation applies comprehensively to the amount of personal data collected, the extent of its processing, the period of its storage, and its accessibility.
The benefits of integrating Privacy by Design and by Default are substantial. They include the early identification of potential threats and problems, which can lead to significant cost savings by avoiding costly retrofits later in the development cycle. More importantly, these principles foster increased privacy and data protection across the organization, thereby bolstering overall GDPR compliance.
Privacy by Design, when applied to AI development, serves as a powerful "AI innovation enabler." While often perceived as an additional compliance burden, integrating privacy considerations from the earliest stages of AI development actually becomes a strategic advantage. By proactively building in privacy and security measures, organizations are compelled to develop more resilient, ethical, and legally sound AI systems. This reduces the likelihood of expensive post-deployment remediation, significant regulatory fines, or severe reputational damage. It shifts the development mindset from a "fix it later" approach to a "build it right from the start" philosophy, which is particularly crucial for the complex and interconnected nature of AI systems. Organizations that fully embrace Privacy by Design for AI are likely to accelerate their development cycles by mitigating risks proactively, fostering greater trust with users, and potentially gaining a competitive edge in markets where privacy is a key differentiator. This approach elevates privacy beyond mere compliance, positioning it as a hallmark of responsible and sustainable AI innovation.
B. Data Protection Impact Assessments (DPIAs) for AI Systems (Article 35 GDPR)
Data Protection Impact Assessments (DPIAs) are a mandatory requirement under GDPR Article 35 "where a type of processing in particular using new technologies... is likely to result in a high risk to the rights and freedoms of natural persons". Given the nature of AI systems, which often involve extensive data processing and novel technologies, they frequently fall into this "high-risk" category.
A DPIA is designed to assist an organization in assessing the risks associated with data processing activities that may pose a threat or high risk to individuals' rights and freedoms. It is a proactive tool that helps identify privacy risks during the development lifecycle of a program and outlines how personal information will be handled and secured to maintain privacy.
When a DPIA is typically needed for AI systems:
Systematic and extensive evaluation of personal aspects based on automated processing, including profiling, which produces legal effects concerning the individual or similarly significantly affects them. Examples include credit scoring systems determining loan approvals or e-recruiting tools without human review.
Processing on a large scale of special categories of data (e.g., health data, biometric data) or personal data relating to criminal convictions and offenses.
Systematic monitoring of a publicly accessible area on a large scale, such as through CCTV or body-worn devices.
Processing that relies on new technology, which inherently carries novel or uncertain privacy risks.
Key elements of a DPIA for AI systems include:
A systematic description of the processing operations and their purposes, detailing the types of data, scope, context, and goals of processing. This also involves identifying data retention periods and external vendors or third parties involved.
An assessment of the necessity and proportionality of the processing operations in relation to the purposes, ensuring data minimization.
An assessment of the risks to the rights and freedoms of data subjects. For AI systems, these risks specifically include algorithmic bias, data leakage, and inadequate transparency.
The measures envisaged to address the identified risks, including safeguards, security measures, and mechanisms to ensure the protection of personal data and to demonstrate compliance. Mitigation strategies often involve encryption, anonymization or pseudonymization, regularly updating data governance policies, and comprehensive data breach response plans.
DPIAs should not be treated as a one-time exercise but rather as continuous, evolving processes that adapt to business and technological changes. They should be integrated with privacy by design principles and involve multidisciplinary teams comprising legal, compliance, IT, and business professionals to ensure holistic evaluations. The advice of the Data Protection Officer (DPO), where designated, should always be sought when carrying out a DPIA.
The following table provides a concise overview of key AI-related risks and corresponding mitigation strategies within the DPIA framework, serving as a practical guide for organizations:

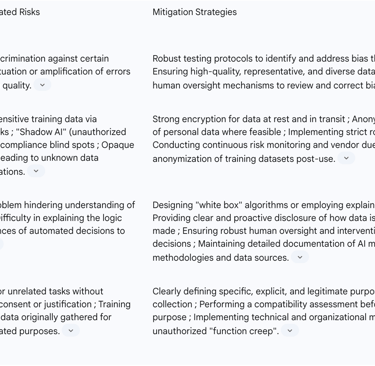
This table is particularly valuable for data protection officers and compliance teams as it provides a concise, actionable overview. By categorizing AI-related risks and directly linking them to concrete mitigation strategies, the table transforms abstract compliance requirements into a practical checklist. This enhances the utility of the DPIA for AI systems by offering a quick reference guide for identifying high-priority areas and implementing appropriate controls specific to AI, thereby addressing the practical "how-to" aspect of navigating compliance.
C. Implementing Robust Data Governance and Human Oversight
Implementing robust data governance frameworks is essential for effectively managing data-related risks inherent in AI systems. Such frameworks should explicitly define ethical AI principles, with a strong focus on fairness, transparency, and accountability.
Organizations must assign clear AI governance roles and responsibilities across the enterprise. This necessitates the involvement of multidisciplinary teams—including legal, technical, and operational experts—to ensure comprehensive compliance and accountability throughout the entire AI system's lifecycle. This collaborative approach helps to bridge the gap between legal requirements and technical implementation.
Human oversight is a critical component of responsible AI, even in scenarios where automated decision-making is extensively utilized. Mechanisms for human review, appeal, and correction of AI-generated decisions must be firmly in place. The GDPR explicitly grants individuals the right to human intervention for solely automated decisions that significantly affect them. This ensures that individuals are not subject to irreversible or unfair outcomes without recourse.
Ongoing monitoring, auditing, and overseeing of AI systems are crucial, as these systems are dynamic and often evolve over time. Periodic reviews and audits—encompassing technical, legal, and ethical dimensions—are necessary to identify any areas of non-compliance or emergent risks. Structured governance frameworks should meticulously maintain version histories, document changes in model architectures, and track data usage to ensure projects remain prepared for regulatory oversight and can demonstrate accountability.
Furthermore, training employees in data protection practices and consistently raising awareness about security protocols are vital steps to mitigate human error, which remains a leading cause of data breaches. A well-informed workforce is a critical line of defense in maintaining data integrity and confidentiality.
The emphasis on human oversight for automated decisions, coupled with the need for multidisciplinary teams and robust data governance, points towards a "hybrid intelligence" model for AI governance. This view suggests that effective AI governance is not about replacing human judgment with AI, but rather about creating a synergistic system where human expertise and oversight are strategically integrated at critical junctures of the AI lifecycle. This ensures ethical alignment, legal compliance, and the crucial ability to intervene, correct, or challenge AI outputs, particularly in high-stakes scenarios. This model acknowledges AI's strengths, such as rapid processing and pattern recognition, while compensating for its weaknesses, like the lack of common sense or potential for inherent bias, with informed human judgment. Organizations should therefore design their AI systems and governance structures to facilitate this human-in-the-loop or human-on-the-loop approach. This includes establishing clear escalation paths for problematic AI outputs, defining precise roles and responsibilities for human review, and implementing comprehensive training programs that equip staff to understand, interpret, and manage AI outputs effectively. This model fosters greater trust and accountability, moving beyond purely technical solutions to embrace socio-technical systems that combine the best of human and artificial intelligence.
D. Leveraging Privacy-Enhancing Technologies (PETs)
Privacy-Enhancing Technologies (PETs) are crucial tools for organizations seeking to balance innovation with GDPR compliance. These technologies are specifically designed to protect personal data throughout its entire lifecycle, from collection to deletion. By minimizing the exposure of sensitive information while still enabling necessary data processing, PETs offer a practical pathway to achieve data protection goals.
The following table details various types of PETs and their specific applications in achieving GDPR compliance within AI contexts:

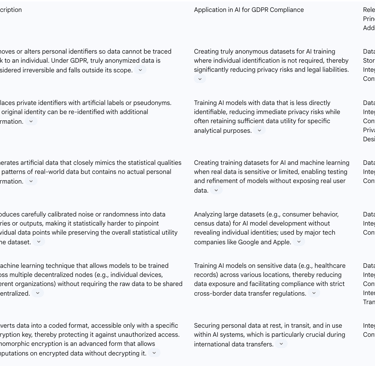
This table is highly valuable as it systematically categorizes and explains various PETs, directly linking them to their utility in achieving GDPR compliance within AI contexts. It moves beyond a general mention of PETs to provide concrete examples and their specific benefits, making it easier for both technical and legal teams to identify and implement appropriate solutions. By detailing specific PET types, their descriptions, applications in AI, and the GDPR principles they address, the table serves as a practical toolkit for organizations to proactively embed privacy into their AI systems, thereby addressing the "how" of compliance with innovative technical solutions.
IV. Regulatory Landscape and Enforcement in the AI Era
A. Guidance from Key Authorities: ICO and EDPB
Data protection authorities play a crucial role in interpreting and enforcing GDPR in the context of AI, providing essential guidance for organizations.
Information Commissioner's Office (ICO) - UK: The ICO, often considered the de facto regulator for AI in the UK, adopts a pragmatic and risk-focused approach to AI regulation. Their guidance aims to strike a balance between promoting innovation in AI and effectively protecting individuals' rights and freedoms. Key areas of their detailed guidance include how to apply UK GDPR principles to AI systems, practical advice on explaining AI decisions, and specific considerations for handling biometric data. The "Explaining Decisions Made with AI" guidance, developed in collaboration with The Alan Turing Institute, offers practical steps to make AI-assisted decisions understandable to affected individuals. This guidance is structured to address various organizational levels, covering fundamental concepts and legal frameworks for DPOs and compliance teams, practical implementation tasks for technical teams, and organizational roles and policies for senior management. The ICO also provides an "AI and data protection risk toolkit" to assist organizations in assessing and mitigating risks to individual rights and freedoms posed by their AI systems. It is important to note that much of the ICO's guidance is currently under review due to the recent enactment of the UK Data (Use and Access) Act 2025, which may introduce changes to existing data protection requirements.
European Data Protection Board (EDPB) - EU: The EDPB, comprised of representatives from national data protection authorities across the EU, plays a pivotal role in ensuring the consistent application of GDPR throughout the Union by issuing opinions, guidelines, and recommendations. Recent EDPB opinions have addressed critical aspects of AI and data protection, offering clarity on the anonymity of AI models, the appropriate use of legitimate interest as a legal basis, and the exercise of data subject rights in AI contexts. The EDPB emphasizes a high threshold for considering an AI model truly anonymous, requiring that the probability of extracting personal data from the model, either directly or through queries, be negligible for each data subject. For organizations relying on legitimate interest, the EDPB mandates a rigorous three-step test: identifying the legitimate interest, analyzing the necessity of the processing (ensuring proportionality and no less intrusive means), and conducting a balancing test that carefully considers the data subjects' reasonable expectations and potential risks. Furthermore, the EDPB has suggested an "expanded" right to erasure and a "premature right to object" in AI contexts. They also urge transparency beyond standard privacy notices, recommending organizations provide additional details about data collection criteria and datasets used, and explore alternative communication methods like transparency labels or model cards to enhance user understanding.
The differing approaches and evolving legislative landscapes highlight a "regulatory divergence" that creates a "compliance patchwork" challenge. While both the ICO and EDPB aim to safeguard data protection, the UK's post-Brexit legislative changes, particularly the Data (Use and Access) Act 2025, signal a potential divergence from EU GDPR interpretations and enforcement. For instance, the UK Act relaxes restrictions on solely automated decision-making for non-sensitive data, a notable difference from the EU's stricter stance. The EU's extension of the UK's adequacy decision is specifically to assess the impact of this new Act. This evolving landscape means that organizations operating across both jurisdictions cannot rely on a single, unified compliance strategy. They must adopt a flexible and adaptive approach, potentially requiring separate legal assessments and technical implementations to meet potentially diverging requirements. This increases the complexity and cost of compliance for multinational entities.
B. Interplay with the EU AI Act: High-Risk Systems and Dual Compliance
The EU AI Act, which was officially enacted on June 13, 2024, establishes a comprehensive framework for Artificial Intelligence systems within the European Union. While the GDPR governs the broader aspects of personal data protection, the EU AI Act specifically addresses AI-related risks, and both regulations collectively aim to safeguard fundamental rights and mitigate harm through robust risk management. The AI Act clarifies that the GDPR always applies when personal data is processed by AI systems, underscoring their complementary nature.
The EU AI Act classifies AI systems into four tiers of risk, with corresponding obligations:
Unacceptable Risk: AI systems considered a clear threat to the safety, livelihoods, and rights of people are banned. This includes practices like harmful AI-based manipulation, social scoring, and real-time remote biometric identification in public spaces.
High Risk: AI use cases that can pose serious risks to health, safety, or fundamental rights are classified as high-risk. These include AI systems used in critical infrastructures (e.g., transport), education, employment (e.g., CV-sorting software), essential private and public services (e.g., credit scoring), law enforcement, migration, and the administration of justice. High-risk AI systems are subject to strict obligations before they can be placed on the market, including adequate risk assessment and mitigation systems, high-quality datasets to minimize discriminatory outcomes, logging of activity for traceability, detailed documentation, clear information for deployers, appropriate human oversight, and high levels of robustness, cybersecurity, and accuracy.
Limited Risk: This category refers to risks associated with a need for transparency around AI use. The Act introduces specific disclosure obligations, such as informing humans when they are interacting with a chatbot, and requiring generative AI providers to ensure AI-generated content is identifiable.
Minimal Risk: AI systems that pose very light or no risk have minimal obligations.
The interplay between the EU AI Act and GDPR creates a "dual compliance imperative." While the AI Act directly regulates AI systems, especially in sensitive sectors, the GDPR applies indirectly whenever AI processes personal data. Key principles like accountability, fairness, transparency, accuracy, storage limitation, integrity, and confidentiality, which are fundamental under GDPR Article 5, are also enshrined in the AI Act. This convergence means that organizations must satisfy both regulatory frameworks.
For instance, both acts require risk assessments: the AI Act for AI harms like bias or safety failures, and the GDPR for Data Protection Impact Assessments (DPIAs) for high-risk data processing. These risk assessments can often be combined to address ethical, legal, and technical concerns efficiently. Similarly, both promote transparency, accountability, human oversight, and data security, stressing protection against unauthorized access and data misuse. Organizations are encouraged to adopt integrated compliance frameworks to avoid duplicative efforts and leverage existing GDPR infrastructure, such as data mapping tools and DPIA templates, adapting them for AI Act requirements. This integrated approach is crucial for harnessing AI's potential while respecting individuals' rights and meeting the stringent demands of both the EU AI Act and the GDPR.
C. International Data Transfers and Global AI Deployment
The global deployment of AI models faces significant challenges related to international data transfers, primarily due to geopolitical fragmentation and the inherent need for borderless data access for optimal AI performance. This landscape is characterized by increased regulatory fragmentation, where privacy and data protection laws form the basis for AI regulation in many regions.
Key challenges include:
Jurisdictional Incompatibility: Different regions have varying data protection standards. For example, GDPR in Europe mandates strict safeguards, while data processed in other jurisdictions might be subject to different legal frameworks, such as government surveillance under the CLOUD Act in the U.S..
Opaque Vendor Chains: When AI, particularly generative AI, is embedded in cloud-based services (SaaS tools), data may transit multiple subprocessors and locations, many of which fall outside direct corporate or regulatory oversight. This lack of visibility makes it difficult to track data flows and ensure compliance across the entire chain.
Unintended Data Transfers: Employees using generative AI tools may inadvertently transfer data to unknown storage or processing locations, creating compliance blind spots. Even when AI tools source public data, regulators are scrutinizing their use for training datasets and jurisdictional authority.
The GDPR's rules on international data transfers, outlined in Chapter V, face challenges that may diminish their global influence, and these problems directly affect AI-related transfers due to the EU AI Act's explicit link to GDPR. The invalidation of Privacy Shield and the subsequent introduction of the EU-U.S. Data Privacy Framework have further complicated cross-border data transfers, necessitating additional safeguards when transferring personal data to third countries.
To manage these risks, organizations must adopt strategic measures:
Conduct Transfer Impact Assessments (TIAs): These assessments are crucial for evaluating the legal environment of the destination country, especially if data is routed through generative AI APIs or services. They should assess government surveillance risks, available redress mechanisms, and vendor transparency.
Classify and Control Sensitive Data: Implement robust data classification systems to identify sensitive information and apply appropriate controls. This includes role-based access, redacting sensitive fields before AI ingestion, and labeling data that must not cross borders.
Update Vendor Due Diligence for AI: Go beyond standard security checklists. Organizations should specifically ask vendors about data storage and processing locations, monitoring of AI outputs for leakage, the training data used, and the ability to disable memory or retention features.
Operationalize AI Acceptable Use Policies: Develop and enforce clear policies for AI use within the organization. This involves training staff on prohibited prompts, providing sanctioned tools, and monitoring for policy violations.
Integrate AI into Privacy Governance: Establish AI governance committees and embed privacy by design into all AI initiatives. Treat every data transfer as a risk vector and centralize visibility into generative AI use across the enterprise.
The "geopolitical fragmentation of data flows" is a significant consequence of the global "AI race" and the pursuit of digital sovereignty. This dynamic leads to increasingly fragmented data transfer rules along regional and sectoral lines, which will likely intensify with the development of AI and other technologies requiring completely borderless data flows. This necessitates that organizations adopt highly adaptive strategies for international data transfers. It means that a one-size-fits-all approach to global AI deployment is no longer feasible. Instead, organizations must conduct meticulous Transfer Impact Assessments (TIAs) for each data flow, understand the nuances of local regulations, and be prepared to implement diverse technical and organizational measures to ensure compliance across various jurisdictions. This complex environment demands continuous monitoring of regulatory updates and proactive engagement with evolving international standards to mitigate legal and reputational risks.
D. Enforcement Trends and Penalties
The GDPR imposes significant financial penalties for non-compliance, serving as a powerful deterrent. Businesses can be fined up to €20 million or 4% of their global annual turnover, whichever is higher. These fines can have a severe impact on an organization's finances and reputation.
Recent enforcement actions demonstrate the serious consequences of GDPR breaches, particularly in the context of large-scale data processing that often characterizes AI systems:
Meta Platforms Ireland Ltd.: Received a record-breaking €1.2 billion fine in 2023 for violating GDPR international transfer guidelines, specifically for mishandling personal data when transferring it between Europe and the United States using standard contractual clauses. This fine, the largest GDPR penalty to date, underscored the systematic, repetitive, and continuous nature of the infringement involving massive volumes of personal data.
Amazon Europe: Fined €746 million in 2021 by Luxembourg's National Commission for Data Protection (CNPD) for non-compliance with general data processing principles, particularly concerning the use of customer data for targeted advertising.
TikTok: Received a €530 million fine in 2025 from Ireland's Data Protection Commission (DPC) for transferring European users' personal data to servers in China without ensuring equivalent protections under EU law. The investigation revealed that engineers in China routinely accessed sensitive information from European users, and TikTok failed to conduct adequate risk assessments regarding Chinese laws on anti-terrorism and state surveillance.
Meta Platforms, Inc. (Instagram): Fined €405 million in 2022 by the DPC for infringements related to the processing of child users' personal data, including violations of principles like lawfulness, fairness, transparency, and data protection by design and default.
Beyond these substantial fines, the ICO in the UK has also issued significant penalties, including £20 million to British Airways and £18.4 million to Marriott Hotels for data breaches, and £7.5 million to Clearview AI for its use of facial recognition technology. These cases highlight that while regulatory bodies like the ICO adopt a pro-innovation stance towards AI, enforcement action will follow where compliance with GDPR is lacking and presents real risks to individuals.
The financial implications of non-compliance are substantial, but organizations also face severe reputational damage, a loss of customer trust, and potential business disruption from regulatory interventions. The EU AI Act, with its additional enforcement mechanisms, further raises the stakes for organizations developing and deploying AI systems.
Conclusion
Navigating GDPR compliance in the AI era presents a complex yet critical imperative for organizations. The analysis presented in this report underscores that the GDPR is not merely an auxiliary regulation but a foundational legal framework that profoundly shapes the responsible development and deployment of AI systems, particularly those processing personal data. The inherent characteristics of AI, such as its data hunger and the "black box" problem, create significant tension points with core GDPR principles like data minimization, purpose limitation, transparency, and data subject rights. These tensions represent the primary areas of compliance risk and demand focused attention.
The evolving regulatory landscape, marked by the EU AI Act's risk-based approach and the potential for divergence in UK data protection law, necessitates a "dual compliance imperative" for organizations operating across jurisdictions. This complex environment requires a sophisticated, adaptive, and integrated approach to governance.
To effectively navigate these challenges and ensure sustained compliance, organizations should adopt the following actionable recommendations:
Embed Privacy by Design and by Default: Proactively integrate data protection measures into every stage of AI system development. This means building privacy and security controls from inception, rather than attempting to retrofit them, thereby reducing long-term costs and fostering more resilient and ethical AI solutions.
Conduct Rigorous Data Protection Impact Assessments (DPIAs): Treat DPIAs as continuous, evolving processes, not one-time exercises. For AI systems, these assessments must specifically address risks such as algorithmic bias, data leakage, and transparency deficits, implementing tailored mitigation strategies like robust testing, encryption, and pseudonymization.
Implement Robust Data Governance and Human Oversight: Establish clear AI governance frameworks with assigned roles and responsibilities across multidisciplinary teams. Embrace a "hybrid intelligence" model where human expertise and oversight are integrated at critical junctures of the AI lifecycle, ensuring ethical alignment, legal compliance, and the ability to intervene in automated decisions.
Leverage Privacy-Enhancing Technologies (PETs): Strategically adopt PETs such as anonymization, pseudonymization, synthetic data, differential privacy, and federated learning. These technologies are crucial for balancing AI innovation with data minimization and confidentiality requirements, enabling organizations to process data effectively while safeguarding individual privacy.
Prioritize Transparency and Explainability: Move beyond basic disclosure requirements by proactively explaining AI-assisted decisions in a meaningful, truthful, and timely manner. Invest in developing more interpretable AI models and explore innovative communication methods to enhance user understanding and build trust.
Develop Adaptive International Data Transfer Strategies: Recognize the geopolitical fragmentation of data flows and conduct thorough Transfer Impact Assessments (TIAs) for cross-border AI data transfers. Implement robust safeguards, update vendor due diligence, and operationalize AI acceptable use policies to manage risks associated with diverse jurisdictional requirements.
Foster a Culture of Data Protection and Ethical AI: Regular training for all staff, from technical developers to senior management, is essential to build awareness and embed data protection principles into daily operations. This proactive approach helps mitigate human error and cultivates a responsible AI ecosystem.
FAQ
How does GDPR define "automated decision-making" in the context of AI?
GDPR Article 22 refers to decisions based solely on automated processing, including profiling, that produce legal or similarly significant effects on individuals. This includes AI systems that make decisions without meaningful human review, such as automated loan approvals or hiring algorithms. Organizations must either avoid such fully automated significant decisions or implement specific safeguards including human oversight, mechanisms to contest decisions, and transparent explanations.
What constitutes a sufficient explanation of AI decision-making under GDPR?
While GDPR doesn't precisely define what constitutes a sufficient explanation, organizations should provide meaningful information about the logic involved, the significance, and envisaged consequences of automated decisions. The level of detail should be appropriate to the audience, with general explanations for most data subjects and more detailed information upon request. For complex AI systems, this typically involves explaining key factors that influenced decisions rather than comprehensive algorithm details.
Are neural networks incompatible with GDPR due to their "black box" nature?
Neural networks are not inherently incompatible with GDPR, but their complexity creates transparency challenges. Organizations using neural networks must implement additional measures such as post-hoc explanation methods, parallel interpretable models, or enhanced documentation to satisfy GDPR transparency requirements. For high-risk applications, organizations should consider whether more interpretable algorithms might be appropriate despite potentially lower performance.
How does the "right to erasure" impact AI training data?
The right to erasure requires organizations to remove an individual's data upon request, which can affect AI models trained on that data. Organizations must design their data architecture to track training data provenance and implement technical solutions that can remove or nullify the influence of specific data points without retraining entire models. Techniques such as influence functions, incremental learning, and careful documentation of training data sources can help manage erasure requests efficiently.
What's the relationship between GDPR and the new EU AI Act?
GDPR and the EU AI Act are complementary frameworks. While GDPR focuses on personal data protection regardless of technology, the AI Act specifically addresses AI systems based on risk levels, regardless of whether they process personal data. AI systems processing personal data must comply with both regulations. Organizations should implement integrated compliance approaches that address the overlapping requirements efficiently, as many measures satisfy obligations under both frameworks.
Can synthetic data resolve GDPR compliance issues in AI training?
Synthetic data can help address certain GDPR challenges by reducing reliance on real personal data, but it's not a complete solution. If the synthetic data is derived from personal data, the original collection must still have a lawful basis, and organizations must ensure the synthetic generation process doesn't allow for re-identification. Well-implemented synthetic data approaches can significantly reduce privacy risks while still enabling effective model development, particularly for initial testing and validation.
When is a Data Protection Impact Assessment (DPIA) required for AI systems?
A DPIA is required when AI processing is likely to result in high risk to individuals' rights and freedoms. This typically includes systematic evaluation of personal aspects through profiling with significant effects, large-scale processing of special categories of data, or systematic monitoring of publicly accessible areas. Most sophisticated AI systems processing personal data will meet this threshold and benefit from the structured risk assessment a DPIA provides.
How can organizations satisfy data minimization when AI models often require large datasets?
Organizations can satisfy data minimization by carefully selecting relevant features rather than collecting all available data, implementing dimension reduction techniques, using privacy-preserving aggregations, employing synthetic data, and implementing regular data review processes to remove unnecessary information. The principle doesn't prohibit using substantial data when necessary for legitimate purposes but requires thoughtful assessment of what data is truly needed for the specific application.
What are the GDPR implications of using pre-trained AI models from third parties?
When using pre-trained models from third parties, organizations remain responsible for ensuring GDPR compliance. This includes conducting due diligence on how the model was trained, assessing whether it processes personal data, documenting the model's capabilities and limitations, and implementing appropriate safeguards for any high-risk applications. Organizations should obtain contractual guarantees from providers regarding data protection compliance and conduct their own validation testing before deployment.
How do international data transfers rules affect global AI development teams?
International data transfers rules restrict moving personal data outside the EEA without appropriate safeguards. Global AI teams must implement measures like Standard Contractual Clauses with supplementary technical measures, data localization strategies, or privacy-enhancing technologies like federated learning that allow model development without transferring raw personal data. Organizations should assess whether their AI development processes involve restricted transfers and implement appropriate compliance mechanisms based on the specific data flows and countries involved.