Synthetic Data Generation for Privacy
Synthetic data generation stands as a transformative technology, offering a compelling and increasingly indispensable solution to the modern data dilemma. It empowers organizations to leverage the immense potential of data for innovation and advanced analytics while rigorously upholding individual privacy and robust security standards.


Synthetic data generation (SDG) is rapidly emerging as a foundational technology for advancing privacy-preserving Artificial Intelligence (AI) and addressing critical data challenges in the modern digital landscape. This process involves the creation of artificial datasets that statistically mimic real-world data without containing any Personally Identifiable Information (PII). This approach enables organizations to maintain data utility while rigorously safeguarding individual privacy.
The strategic importance of synthetic data is underscored by the escalating complexity of data privacy regulations, such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), coupled with the increasing sensitivity of real-world information. SDG offers a robust alternative to traditional anonymization methods, facilitating secure data sharing, accelerating the development of AI and Machine Learning (ML) models, and mitigating the substantial risks associated with data breaches and compliance violations.
This report delves into the diverse methodologies employed for synthetic data generation, explores its profound benefits in enhancing privacy, critically examines inherent challenges such as fidelity gaps and bias amplification, highlights its transformative applications across various industries, and provides a detailed analysis of its complex regulatory and legal implications. The discussion concludes with a forward-looking perspective on emerging trends and actionable recommendations for effective implementation and governance.
The Imperative of Privacy-Preserving Data
Defining Synthetic Data and its Core Purpose for Privacy
Synthetic data refers to artificially generated information created by computer algorithms or simulations, designed to serve as a substitute for real-world data. Its fundamental characteristic is its ability to replicate the statistical properties, underlying patterns, and behavioral characteristics of original datasets without incorporating any actual Personally Identifiable Information (PII). This distinction is crucial, as it allows for the utility of data without the direct exposure of sensitive individual details.
The primary objective of synthetic data is to address situations where real-world data is either incomplete, prohibitively expensive to collect, inherently sensitive, or simply unavailable due to stringent privacy or security considerations. By providing a high-fidelity, artificial stand-in, synthetic data enables organizations to overcome significant hurdles such as data scarcity, ensure adherence to privacy compliance mandates, and significantly accelerate the training and validation of AI models. It is not merely an artificial copy but a carefully constructed representation that can offer unique advantages beyond naturally collected data, which often arises from routine business processes like customer preferences or market analysis.
The Growing Need for Privacy-Preserving Data Solutions
The pervasive digital transformation across virtually all industries has led to an exponential increase in the volume and variety of data collected. This proliferation of data has, in parallel, amplified concerns regarding data privacy, the potential for security breaches, and the complexities of regulatory compliance. Organizations are increasingly finding that obtaining and effectively utilizing real-world data presents formidable challenges. These include navigating strict and evolving privacy regulations such as GDPR in the European Union, CCPA in California, and HIPAA in the USA, alongside the substantial financial costs and the immense effort required to collect, clean, and prepare large, high-quality datasets.
Traditional methods of data anonymization and masking, while useful, have often proven insufficient in the face of increasingly sophisticated re-identification techniques. This inadequacy has prompted a widespread exploration among researchers and organizations for more robust and inherently privacy-protective alternatives, with synthetic data generation emerging as a leading solution.
The increasing reliance of AI and machine learning models on vast quantities of diverse and accurate datasets , combined with the tightening grip of data privacy regulations , creates a fundamental dilemma for organizations. This situation often leads to a perceived data scarcity for AI development, not because data does not exist, but because accessible, compliant, and usable data is increasingly difficult to obtain. Synthetic data directly addresses this challenge, serving as a critical bridge between the demand for extensive data and the imperative for privacy. This positions synthetic data not merely as a technical tool but as a strategic enabler for the future of AI development, allowing innovation to proceed without compromising ethical and legal obligations. It fundamentally alters the landscape of data access and utilization within the digital economy.
Furthermore, the observation that traditional anonymization methods are often "insufficient" and that synthetic data is "more than just an artificial stand-in" indicates a significant shift in data privacy paradigms. This suggests a move in thinking from simply masking or removing PII to generating entirely new, yet statistically representative, data. The underlying impetus for this evolution stems from the growing sophistication of re-identification attacks and the recognition that even "de-identified" real data can still pose considerable risks. This evolution signals a deeper commitment to "privacy by design," where privacy is not an afterthought or an add-on, but an inherent characteristic of the data itself from the moment of its generation.
Synthetic Data Generation: Methodologies and Approaches
Overview of Generation Principles
Synthetic data is created programmatically, employing a variety of techniques that broadly fall into categories such as machine learning-based models, agent-based models, and hand-engineered methods. The overarching goal of these diverse approaches is to accurately capture and replicate the underlying characteristics, statistical patterns, and distributions present in the original, real-world datasets.
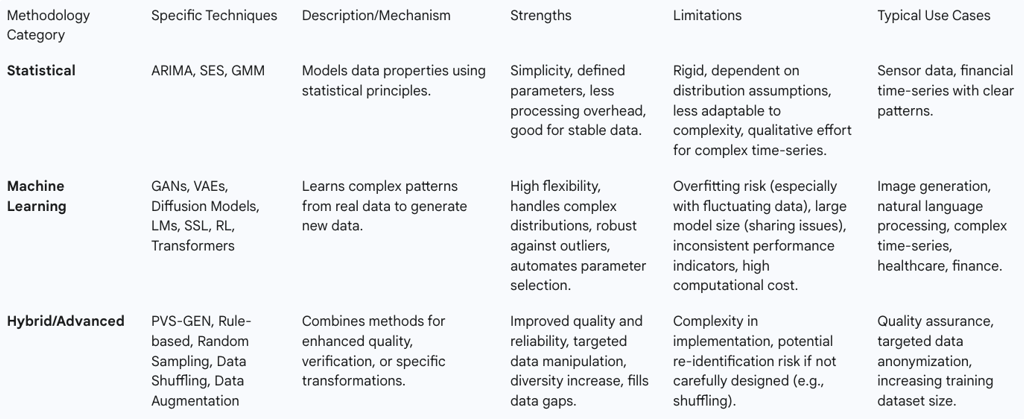
Statistical Methodologies
Traditional statistical methodologies are employed to generate synthetic data by modeling the statistical properties of existing data, such as sensor output results or other structured information. Common examples include Simple Exponential Smoothing (SES), Autoregressive Integrated Moving Average (ARIMA), and Gaussian Mixture Models (GMM).
The strengths of these methods lie in their ability to define suitable parameters for efficient synthetic data generation, often negating the need for separate learning or extensive data processing, which can lead to reduced overhead in data analysis and measurement. Statistically modeled data can be effectively utilized for various tasks, including processing, forecasting, and verification, leveraging pre-established mathematical models. They prove particularly useful in scenarios where data exhibits clear statistical patterns and a high degree of stationarity.
However, statistical methodologies also present limitations. They can be rigid and inflexible due to their inherent dependency on specific assumptions regarding data distribution, making them less adaptable to complex or evolving datasets. Furthermore, estimating models for highly complex data, such as intricate time-series, can demand substantial qualitative effort, thereby hindering effective automation.
Machine Learning Techniques (Deep Generative Models)
Machine learning techniques, particularly those leveraging neural networks and deep generative models, represent a more advanced approach to synthetic data generation. These methods learn intricate patterns and structures directly from empirical data to generate synthetic counterparts that closely resemble the original.
Several key architectures underpin these techniques:
Generative Adversarial Networks (GANs): GANs operate on an adversarial principle, comprising two neural networks: a generator and a discriminator. The generator's role is to create synthetic data, while the discriminator evaluates its authenticity, attempting to distinguish between real and artificially generated data. Through this competitive minimax game, the generator is continuously refined to produce highly realistic synthetic data that is virtually indistinguishable from real data.
Variational Autoencoders (VAEs): VAEs utilize an encoder-decoder neural network architecture with a continuous latent variable to characterize the underlying data distribution. The encoder maps input data into a compressed latent space, and the decoder then reconstructs the data from this latent representation. VAEs are trained to both accurately reconstruct the original data and ensure that the distribution of their latent variables aligns closely with a normal distribution, which enables controlled sampling for generating new, diverse data points.
Diffusion Models (Score-Based Models): Inspired by non-equilibrium thermodynamics, diffusion models involve a two-phase process. A forward diffusion process gradually adds Gaussian noise to the data until it becomes pure noise. A backward diffusion process then reverses this, progressively removing noise to reconstruct data from the noise distribution. A neural network is trained to approximate the conditionals during this reverse process, making them highly effective in generative AI applications like speech synthesis.
Language Models (LMs): Originally developed for natural language processing, LMs learn structured knowledge from massive unlabeled sequence data. They model the conditional probabilities of tokens in a sequence, allowing them to generate various types of sequential data, including natural language text and electronic health records. LMs can also be combined with other deep learning models like VAEs and GANs to enhance their generative capabilities.
Self-Supervised Learning (SSL): SSL is a pretraining strategy that addresses the challenge of limited labeled data by curating supervision signals directly from the data itself. This typically involves masking a subset of raw data features and training a machine learning model to predict the masked information. The pre-trained model then serves as a "warm start" for downstream applications, leveraging insights from vast unlabeled datasets.
Reinforcement Learning (RL): RL can be applied to synthetic data generation by formulating the process as a sequential decision-making problem, where basic components are generated one by one. This is typically framed as a Markov Decision Process (MDP), with the objective of learning an agent that maximizes the total expected reward by making sequential actions.
Transformer-based Models: These models, exemplified by OpenAI's GPT series, excel at capturing intricate patterns and long-range dependencies within data. By training on extensive datasets, they learn the underlying structure and can generate synthetic data that closely resembles the original distribution, particularly effective for complex sequential data like text.
The advantages of these machine learning techniques are significant. They offer greater flexibility and are capable of handling complex data distributions more effectively than traditional statistical methods. They also minimize the need for non-quantitative tasks such as manual parameter selection and tuning, allowing for in-system optimization. Furthermore, they demonstrate robustness against outliers and permit flexible data adjustments due to reduced sensitivity to the input data's specific shape.
However, these techniques are not without limitations. They can be susceptible to learning rate issues, such as overfitting, particularly when dealing with sensor data characterized by significant fluctuations. The sharing and usage of data models can also be restricted due to potential increases in model size, and establishing consistent performance indicators can be challenging as the final output often depends more on the specific learning model or methodology than on a standard mathematical framework.
Hybrid and Advanced Approaches
Beyond individual methodologies, hybrid and advanced approaches are emerging to enhance the quality and reliability of synthetic data. One such systematic approach is PVS-GEN (Parameterization, Verification, and Segmentation), designed as an automated, general-purpose process for both synthetic data generation and its subsequent verification.
PVS-GEN comprises three key processes:
Parameterization: This initial step focuses on constructing the fundamental data frame (SyNode) and extracting autoregressive parameters, such as those from an ARIMA model, directly from empirical data. The aim is to generate synthetic data with minimal user intervention, defining the base data record for subsequent processes.
Verification: This crucial phase assesses the reproducibility of the empirical data by the generated model. It involves transforming both the input empirical data and the synthetic model into frequency components using Discrete Fourier Transform (DFT). A "Possibility of Reproducibility (PoR)" metric is then introduced to quantify the quality and similarity between the two time-series datasets, with a score near 1 indicating high similarity.
Segmentation: To address high volatility and complex temporal changes in time-series data, this process divides the data into multiple segments. This allows for the extraction of suitable parameters for each segment, mitigating issues that might arise from treating highly dynamic data as a single, uniform entity.
Other advanced techniques often serve as components within more sophisticated pipelines. These include rule-based data synthesis, where synthetic data is generated according to predefined rules and logic, offering high control but potentially lacking realism for complex datasets.
Random sampling involves generating data points by randomly selecting values from a predefined distribution.
Data shuffling creates new datasets by rearranging existing real data, for example, by swapping column values, which helps maintain statistical properties but requires careful execution to avoid re-identification risks. Finally, data augmentation, commonly used in image and text generation, applies transformations (e.g., rotation, translation, noise addition) to existing data to create new synthetic samples, increasing the diversity and size of training datasets for machine learning.
The detailed descriptions of machine learning techniques (GANs, VAEs, Diffusion Models, LMs) compared to statistical methods (ARIMA, GMM) reveal a clear trend: while statistical methods offer simplicity and are effective for stable data, machine learning approaches provide greater flexibility and can handle complex data distributions more effectively. This methodological evolution is driven by the increasing complexity and volume of real-world data, as well as the need for synthetic data to support advanced AI models that require nuanced, high-fidelity inputs. This indicates that the future of synthetic data generation is deeply intertwined with advancements in generative AI. Organizations must therefore invest in machine learning expertise and robust infrastructure to leverage the full potential of synthetic data, moving beyond simpler rule-based or statistical approaches to achieve more robust privacy-preserving solutions.
A critical observation from the PVS-GEN methodology is the explicit inclusion of a "Verification" step, complete with a "Possibility of Reproducibility (PoR)" metric. This highlights that merely generating synthetic data is insufficient; its quality and statistical similarity to real data must be rigorously validated. This directly addresses the "fidelity gap" challenge inherent in synthetic data, where "almost real" data can lead to poor real-world performance. This underscores a crucial governance and quality control requirement: for synthetic data to be trustworthy and truly useful, particularly in sensitive domains, organizations cannot simply create it; they must implement robust validation frameworks to ensure its statistical integrity and representativeness. This shifts the focus from mere creation to verifiable utility.
Table 1: Comparison of Synthetic Data Generation Methodologies
Enhancing Data Privacy Through Synthetic Data
Synthetic data offers a multifaceted approach to enhancing data privacy, moving beyond traditional methods to provide more robust and inherent protections.
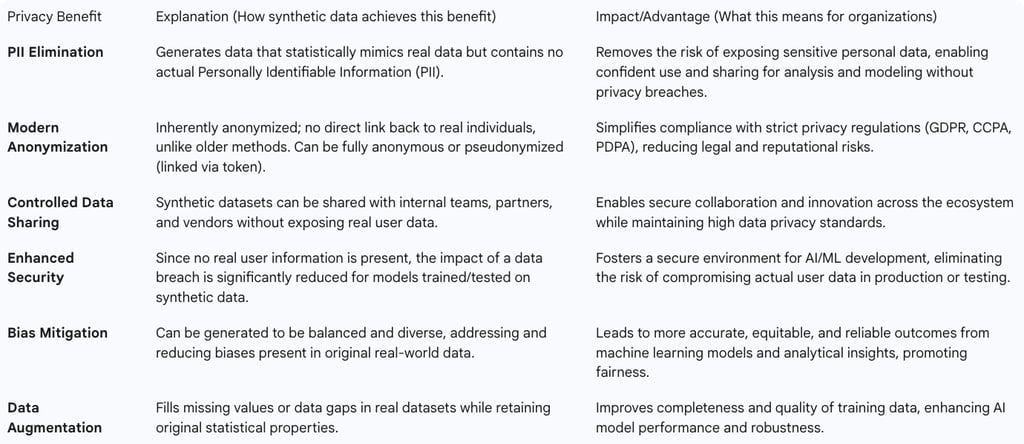
Elimination of Personally Identifiable Information (PII)
The most fundamental privacy benefit of synthetic data lies in its inherent design: it mimics the statistical properties and behavioral patterns of real data without incorporating any actual PII. Advanced algorithms are employed to generate these datasets, ensuring that while the utility for analysis, modeling, and decision-making is retained, the direct risk of exposing sensitive personal information is completely removed. This allows organizations to confidently utilize and share data without the constant concern of privacy breaches or non-compliance with regulations.
Anonymization and Pseudonymization Techniques
Synthetic data generation often employs techniques that align with, or surpass, traditional anonymization and pseudonymization.
Pseudonymization: In this approach, synthetic data generators replace sensitive data elements, such as customer names and addresses, with artificial identifiers or pseudonyms. This method facilitates AI research and data analysis without directly exposing privacy. Importantly, in some pseudonymized synthetic datasets, a linkage back to the original real dataset can be maintained through an additional token or key, allowing for certain types of controlled analysis while preserving a layer of privacy.
Anonymization: This process aims to make the synthetic data completely anonymous by either removing or obscuring sensitive data elements that are most likely to be exploited for re-identification. Unlike older anonymization methods that might still carry residual risks, truly anonymized synthetic data is designed to have no direct link back to the original or any other dataset, providing a higher degree of privacy assurance. The inherent anonymization of synthetic data means there is no direct link to any real individuals, simplifying compliance with stringent privacy regulations like PDPA, GDPR, and CCPA, and thereby reducing legal risks.
Controlled Data Sharing and Enhanced Security Posture
Synthetic data significantly improves an organization's security posture and enables controlled data sharing. Because synthetic datasets do not contain real user information, they can be shared securely with internal teams, external partners, and vendors without exposing sensitive real data. This capability fosters secure collaboration and innovation across an ecosystem while maintaining high data privacy standards.
Furthermore, the absence of actual user data in synthetic datasets means that the impact of a potential data breach is drastically reduced. When used for testing, training, and development purposes, synthetic data eliminates the risk of compromising actual user data, thereby cultivating a more secure environment for technological innovation. Organizations can also enhance privacy and compliance by opting for on-premises deployment of synthetic data solutions, particularly when the synthetic data has inherent dependencies on sensitive information, thus avoiding the potential exposure risks associated with cloud storage systems.
Bias Mitigation and Data Augmentation for Fairer Models
Synthetic data plays a crucial role in addressing data quality issues, including bias. It can be strategically generated to be balanced and diverse, which directly helps in addressing and reducing biases present in real-world data. This capability leads to the development of more accurate, equitable, and reliable outcomes from machine learning models and analytical insights, promoting fairness in AI systems.
Additionally, synthetic data can augment real datasets that suffer from missing or insufficient values, or contain data gaps. By generating artificial data that retains the statistical characteristics and properties of the original dataset, synthetic data improves the completeness and quality of training data, thereby enhancing overall AI model performance.
While legal compliance with regulations such as GDPR, CCPA, and HIPAA is a primary driver for adopting synthetic data , the benefits extend significantly beyond mere adherence. The analysis indicates that consumer trust is profoundly impacted by data privacy practices, with research showing that 75% of consumers are willing to cut ties with a brand after a cybersecurity attack, and 66% distrust brands that have experienced a data breach. Furthermore, the financial implications are substantial, with annual costs of data breaches globally predicted to exceed $5 trillion in 2024. This suggests that synthetic data is not merely a compliance cost but a strategic investment that protects brand reputation and mitigates significant financial liabilities. Organizations adopting synthetic data can therefore gain a competitive advantage by building trust with data-conscious consumers and reducing the severe financial and reputational fallout from data breaches, thereby transforming privacy from a regulatory burden into a business differentiator.
The dual role of synthetic data in both filling data gaps to improve model performance and simultaneously ensuring privacy by replacing sensitive information reveals a powerful synergistic relationship. The technical need for more and better data (utility) aligns perfectly with the legal and ethical need for privacy. This implies that synthetic data can effectively bridge the traditional trade-off between data utility and privacy, allowing for both to be maximized. It enables organizations to leverage data for powerful insights and AI development while rigorously protecting individual privacy.
A critical nuance in the discussion of synthetic data involves the distinction between pseudonymization, where data can still be linked back to the original with an additional token , and true anonymization, where it is completely unlinked. This distinction carries significant legal implications. If synthetic data is merely pseudonymized, it may still fall under the purview of privacy regulations , whereas true anonymization sets a higher bar for exemption. This highlights that not all synthetic data is created equal from a legal standpoint. Organizations must meticulously understand the specific generation techniques employed and the associated re-identification risk to accurately assess compliance and avoid a false sense of security. This directly impacts the regulatory considerations further explored in this report.
Table 2: Key Privacy Benefits of Synthetic Data

Challenges and Limitations of Synthetic Data Generation
Despite its numerous advantages, synthetic data generation presents several significant challenges and limitations that must be carefully addressed to ensure its effective and responsible deployment.
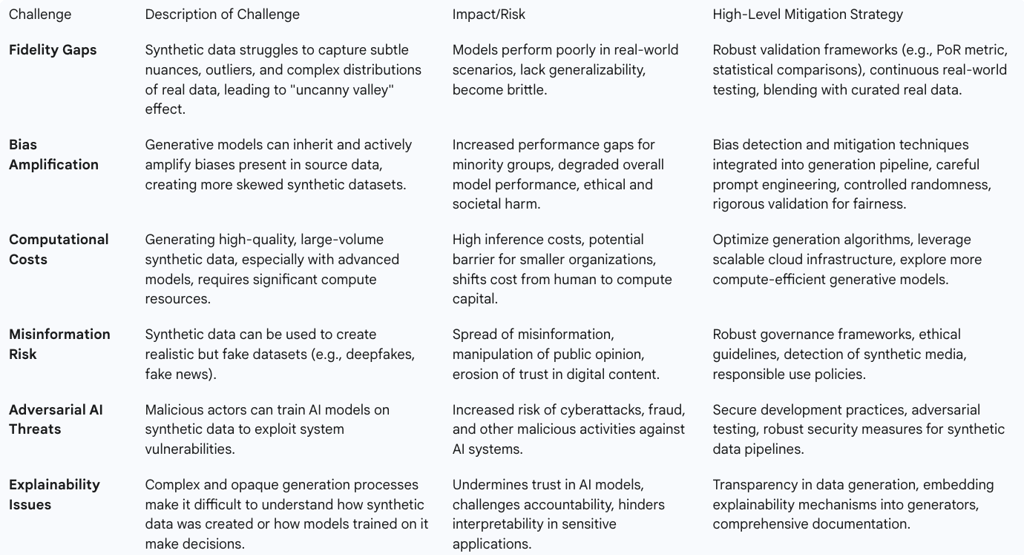
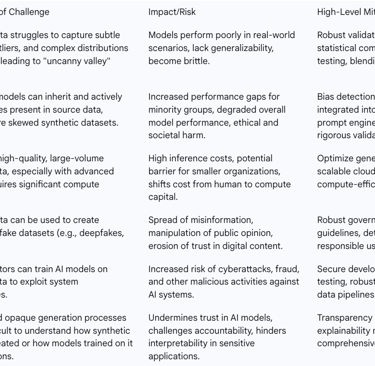
Fidelity Gaps: Ensuring Realism, Utility, and Generalizability
A persistent and fundamental challenge in synthetic data generation is ensuring data fidelity—the extent to which synthetic data accurately mirrors the complex characteristics and statistical distributions of real-world data. While synthetic data can effectively replicate learned patterns, it often struggles to capture the subtle nuances, stylistic realism, inherent messiness, and unpredictable nature of genuine human input. This discrepancy, often termed the "fidelity gap," can lead to models that perform exceptionally well on synthetic validation sets but demonstrate disappointingly poor performance when deployed in practical, real-world situations. Models trained on data that is "almost-real" can become brittle or perform poorly in authentic scenarios that deviate even slightly from the learned synthetic distribution.
Generating highly complex data, such as nuanced natural language text that demands not only syntactic correctness and grammatical adherence but also the conveyance of subtle meaning, tone, and intent, is particularly difficult. Similarly, accurately capturing intricate inter-variable relationships within high-dimensional datasets poses a significant hurdle. Synthetic data may also fail to adequately cover outliers or rare phenomena present in the original real-world dataset, as generation processes often learn from the most prominent patterns, potentially overlooking low-frequency events or edge cases. The quality of synthetic data is inherently dependent on the quality, completeness, and accuracy of the real data used as a source or for training the generator model. If the source data is incomplete, inaccurate, or biased, the synthetic data will inevitably reflect and potentially exacerbate these flaws. The difficulty in achieving true human-like complexity in synthetic data is often likened to the "uncanny valley" phenomenon in robotics and computer graphics. Just as almost-perfectly realistic human figures can evoke a sense of unease or artificiality, synthetic data, while appearing statistically similar, may exhibit subtle inaccuracies, a lack of true variability, or a failure to capture complex, implicit relationships found in genuine human-generated data.
The fidelity gap directly highlights a core tension: the more privacy-preserving synthetic data is, the less likely it is to perfectly mirror the complexity and nuances of real data, potentially reducing its utility for real-world model performance. The "uncanny valley" analogy powerfully illustrates this trade-off, where "almost real" is often insufficient for high-stakes applications. This implies that organizations must carefully balance privacy guarantees with the required level of data utility for their specific use case. It is not a binary choice but a spectrum, and the optimal point depends on the application's sensitivity and performance requirements, necessitating robust evaluation metrics and ongoing validation.
Bias Amplification and Quality Control Concerns
A critical concern with synthetic data is the potential for bias amplification. Large Language Models (LLMs), for instance, trained on vast quantities of internet text and code, inherently reflect societal biases such as gender stereotypes, racial biases, and cultural biases. A significant risk arises when these already biased LLMs are used to generate synthetic data, as this can lead to the propagation and active intensification of existing biases, a phenomenon termed "bias inheritance".
This is not merely passive replication but an active "ethical multiplier effect." A biased generative model might over-represent patterns, viewpoints, or demographic characteristics of majority groups, while under-representing or mischaracterizing those of minority groups. This can result in a synthetic dataset that is even more skewed than the original, and subsequent training on this amplified bias can further entrench these distortions, creating a pernicious feedback loop that exacerbates unfairness and inequity. The impact of bias inheritance is substantial, adversely affecting model fairness, robustness, and trustworthiness. It can increase performance gaps between different demographic groups (e.g., lower accuracy for certain dialects or underrepresented communities) and, through iterative tuning on biased synthetic data, can degrade overall model performance as the model becomes increasingly skewed. It has also been observed that differential privacy, a technique often used for privacy preservation, can amplify fairness issues present in original data.
Therefore, using synthetic data for "bias mitigation" is not an automatic solution; it requires deliberate and sophisticated design of the generation process, including careful prompt construction, controlled randomness for diversity, and rigorous validation to actively correct biases. Rigorous validation and quality control are essential to compare synthetic datasets with real-world data, ensuring statistical fidelity and identifying any discrepancies that could impact model performance.
The concept of "bias inheritance" and the "ethical multiplier effect" reveals a critical long-term risk. If synthetic data generation is not meticulously designed to mitigate bias, it can actively worsen societal inequities embedded in initial datasets. This represents a form of "ethical debt" that accumulates with each iteration of model training. This transforms bias from a mere data quality issue into a significant ethical and societal responsibility for organizations. It demands a proactive and continuous commitment to fairness throughout the entire AI lifecycle, from data generation to deployment, and highlights the need for interdisciplinary collaboration among ethicists, data scientists, and legal experts to prevent unintended harm.
Computational Costs and Resource Demands
While synthetic data can reduce costs compared to manual human annotation, its generation and validation still incur significant computational demands. Generating large volumes of high-quality synthetic data, especially when utilizing powerful "teacher" models in distillation pipelines, involves substantial inference costs. This effectively shifts the computational bottleneck from the training phase to the data generation phase.
For privacy-preserving applications, particularly those aiming for strong guarantees like differential privacy, generating synthetic data incurs high fixed costs and may necessitate a minimum data volume to achieve meaningful privacy without rendering the data useless for private fine-tuning. There exists a clear cost-reward trade-off: stronger, larger generative models tend to produce higher-quality synthetic data but are significantly more computationally expensive. Conversely, cheaper, weaker models may result in lower-quality or less diverse outputs. This dynamic could continue to favor large, well-resourced organizations unless more compute-efficient generation methods are developed.
The generation of synthetic data reallocates costs from human capital (e.g., annotator salaries) to compute capital (e.g., cloud computing or GPU costs). While this can be cost-effective at scale, it introduces new and significant infrastructure and energy demands. This creates a potential barrier for smaller organizations and could exacerbate the "AI divide" by making advanced AI development more accessible to those with substantial computational resources. This also raises questions about the environmental impact of large-scale synthetic data generation and the imperative for developing more energy-efficient generative models.
Risks of Misinformation and Adversarial AI Threats
Synthetic data, like any powerful technology, carries the risk of being exploited for malicious purposes. It can be used to create realistic but entirely fake datasets, which could then be weaponized to spread misinformation or manipulate public opinion. Examples include the generation of synthetic text or images for fake news campaigns or the creation of "deepfakes".
Furthermore, bad actors could leverage synthetic data to train adversarial AI models specifically designed to exploit vulnerabilities in existing systems. For instance, synthetic data might be used to simulate cyberattacks or to develop methods to bypass sophisticated fraud detection systems.
Explainability and Transparency Issues
The process of creating synthetic data is often complex and can be opaque, making it difficult to fully understand precisely how the data was generated and what underlying patterns it learned. This inherent lack of transparency can undermine trust in AI models that are trained on such synthetic data.
Moreover, synthetic data can significantly affect the interpretability of AI models. If the generated data does not accurately represent real-world scenarios or if its generation process is not fully transparent, it may become challenging to explain a model's specific decisions or predictions. This is particularly problematic in high-stakes applications such as healthcare diagnostics or criminal justice, where model interpretability and accountability are paramount.
Table 3: Challenges and Mitigation Strategies in Synthetic Data Generation
Real-World Applications and Use Cases for Privacy
Synthetic data is proving to be a transformative solution across a wide array of industries, enabling data-driven innovation while rigorously upholding privacy standards.
Healthcare Research and Analysis
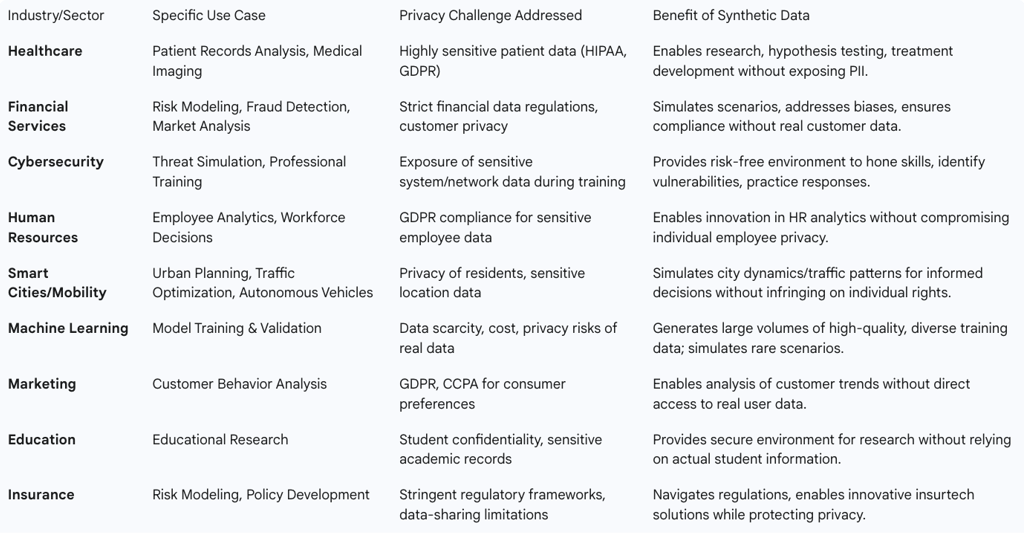
The healthcare industry operates with highly sensitive patient data, including detailed medical histories and illness information, which necessitates extreme care in handling. Synthetic data provides a crucial solution by generating fictitious yet statistically realistic patient records and medical imaging that are entirely non-identifiable. This capability empowers medical researchers to analyze trends, test hypotheses, and develop new treatments without exposing sensitive health information, thereby ensuring compliance with stringent regulations like HIPAA. The use of synthetic data in this sector allows for the acceleration of medical advancements that would otherwise be hampered by privacy constraints.
Financial Services and Banking
In the financial sector, synthetic data plays an indispensable role in addressing critical issues such as risk modeling, sophisticated fraud detection, and comprehensive market analysis. It significantly aids in identifying and addressing biases within datasets, and crucially, ensures compliance with complex data protection regulations by enabling the simulation of various financial scenarios without the direct use of real customer data. This not only enhances customer insights and facilitates the development of personalized financial services but also contributes to more robust business dynamics and opens up new market opportunities within the digital transformation of the financial industry.
Cybersecurity Training and Threat Intelligence
Synthetic data finds powerful application in training cybersecurity professionals by simulating a wide range of cyber threats within a controlled, risk-free environment. This provides an invaluable learning ground for cybersecurity teams, allowing them to hone their skills, identify vulnerabilities in systems, and practice effective response strategies without exposing actual sensitive information or risking real-world systems. This is particularly vital for industries subject to strict data protection regulations, as synthetic data mitigates the compliance risks associated with exposing real and sensitive information during training exercises.
Human Resources and Employee Analytics
Within the realm of People Analytics, synthetic data offers a valuable solution for organizational leaders seeking to inform workforce decisions. By leveraging data to gain insights into employee behavior and trends, People Analytics typically involves collecting diverse employee data and subjecting it to thorough analysis. However, navigating the requirements of regulations such as GDPR can be challenging due to the sensitive nature of employee information. Synthetic data emerges as an optimal solution by avoiding direct correlations with original records, offering a viable avenue for HR departments to innovate with new data and AI-driven technologies without compromising individual employee privacy.
Smart Cities Planning and Mobility
Synthetic data is a strategic solution for smart city planning, effectively eliminating the risk of compromising the privacy of city residents. By being generated in a way that does not trace back to real individuals, synthetic data empowers urban planners to simulate and analyze diverse datasets crucial for informed decision-making, fostering the creation of sustainable and efficient urban environments. In the broader domain of mobility, synthetic data can simulate realistic traffic patterns, allowing urban planners to optimize road networks and infrastructure. Ride-sharing companies can also leverage it to optimize algorithms for matching drivers and passengers, estimating demand, and improving service efficiency while rigorously protecting user privacy.
Training Machine Learning Models Across Industries
Synthetic data is a critical component in the development and refinement of machine learning models, particularly when real data is scarce, expensive to acquire, or poses significant privacy risks. Businesses can utilize synthetic data generation to produce large volumes of high-quality training data that is both diverse and representative of real-world scenarios. This capability enables data scientists to fine-tune their models more effectively, ultimately leading to better predictions and outcomes. Furthermore, synthetic data is uniquely capable of simulating rare scenarios, such as self-driving car accidents or medical emergencies, which are difficult or dangerous to capture in sufficient quantities from real-world data, thereby enhancing the robustness and safety of AI models.
Other Noteworthy Applications
The utility of privacy-preserving synthetic data extends to numerous other sectors:
Marketing Analytics: Marketers can study customer behavior, preferences, and trends without directly accessing real user data. This safeguards individual privacy and ensures strict adherence to privacy regulations like GDPR, enabling targeted strategies without compromise.
Educational Research: Privacy-preserving synthetic data provides a secure environment for educational researchers to explore educational dynamics without relying on actual student information. This helps enhance educational programs and identify areas for improvement in curricula and teaching practices while maintaining student confidentiality.
Insurance: The insurance industry, currently undergoing significant transformation with insurtech startups, relies heavily on data. Synthetic data generators help navigate stringent regulatory frameworks and data-sharing limitations, evolving into robust privacy-enhancing technologies that align with the industry's shift towards innovative, technology-driven solutions.
The prevalence of synthetic data use cases in highly regulated sectors like healthcare, finance, and human resources is a significant observation. These industries face the most stringent privacy constraints (e.g., HIPAA, GDPR, financial regulations). Synthetic data enables them to bypass these constraints while still leveraging data for innovation, such as developing new treatments, detecting fraud, or optimizing workforce decisions. This indicates that synthetic data is a powerful tool for de-risking innovation in privacy-sensitive domains. It allows regulated industries to accelerate their digital transformation and AI adoption without incurring prohibitive legal or reputational risks associated with handling real data.
Beyond privacy compliance, synthetic data is crucial for addressing "data scarcity" and simulating "rare events" or "edge cases". This is particularly valuable in fields like autonomous vehicles (simulating improbable accidents) or fraud detection (identifying rare fraud patterns) where real data is either insufficient or too dangerous/expensive to collect for comprehensive training. This expands the utility of synthetic data beyond just privacy compliance to a fundamental enabler for robust and resilient AI systems. It allows for more thorough testing and validation, leading to safer and more reliable AI deployments in critical applications.
Table 4: Real-World Use Cases of Privacy-Preserving Synthetic Data

Regulatory and Legal Implications: Navigating the Compliance Landscape
The advent of synthetic data generation introduces complex questions regarding its regulatory and legal standing, particularly concerning comprehensive privacy frameworks like the GDPR and CCPA.
The Fundamental Question: Is Synthetic Data "Personal Data"?
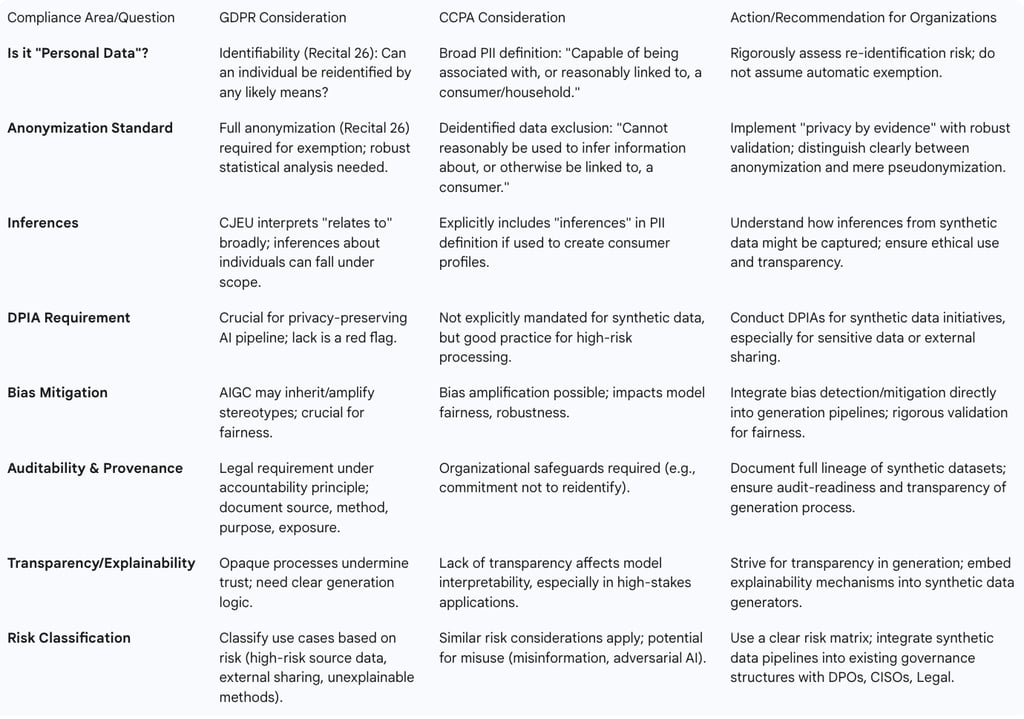
The core legal debate centers on whether artificially generated synthetic data falls under the definition of "personal data" (as per GDPR) or "personal information" (as per CCPA), and consequently, whether it is subject to the stringent requirements of these privacy laws. While truly anonymous data is generally exempt from privacy frameworks worldwide, the categorical assertion that synthetic data is always exempt is largely rejected by legal experts. Instead, a nuanced, context-specific assessment against existing legal standards is consistently required. The applicability of privacy laws to synthetic data hinges on two main factors: first, whether the synthetic data initially falls within the material scope of a privacy law, and second, whether it can be brought outside that scope by being deidentified in a manner that fully satisfies the law's specific requirements.
GDPR Considerations
Under the GDPR, the paramount factor determining whether synthetic data is regulated is the ability to identify an individual from it. Even artificially created data must be subjected to a rigorous legal analysis.
Recital 26 and Anonymization: Recital 26 of the GDPR serves as a critical benchmark, stating that the regulation does not apply to data that has been fully anonymized. This means that if no person can be reidentified by any likely method, even when combined with other available data, then the GDPR does not apply. Achieving this standard requires robust statistical analysis to confirm that no personal information can be reconstructed or inferred with confidence, thereby defending against linkage attacks, inference risks, and residual signals that could potentially triangulate identity. If the model used to generate synthetic data memorizes or mimics real sequences too closely, the synthetic output may still qualify as personal data, triggering full GDPR obligations.
Pseudonymization vs. Anonymization: A common misconception is to equate synthetic data with fully anonymized datasets. However, pseudonymization, while masking names or swapping identifiers, does not eliminate re-identification risk, particularly if the data structure or unique outliers still point to individuals. Poorly generated synthetic data can encounter similar problems if the underlying model overfits and leaks fragments of the original data, or if it fails to remove demographic outliers or high-cardinality patterns that could serve as anchors for inference. The European Data Protection Board (EDPB) has explicitly clarified in its 2024 opinion on AI models and personal data that even synthetic-looking outputs may fall under GDPR if they carry traits from real people or originate from unprotected training data.
Compliance Red Flags: Organizations must be vigilant for several red flags indicating potential non-compliance under GDPR. These include instances where the generative model memorizes or overfits the original data, resulting in synthetic output that contains fragments directly reflecting real individuals. A lack of a Data Protection Impact Assessment (DPIA), undocumented generation logic, or an absent risk assessment should also be considered a serious warning. Furthermore, the use of vague language such as "de-identified" or "GDPR-safe" without explicit mention of Recital 26 and validation against its criteria is a significant concern, as these are not regulated terms and may mask non-compliant methods. Finally, a failure to frame the use case in terms of its privacy risks versus benefits, especially for safety-critical systems or high-stakes model performance, indicates a governance gap. Finance teams, for example, are specifically mandated to document the full lineage of synthetic datasets, including source, method, purpose, and exposure, to ensure audit-readiness.
CCPA Framework
The California Consumer Privacy Act (CCPA) also has significant implications for synthetic data, characterized by its broad definitions.
Broad Definition of Personal Information (PII): The CCPA defines personal information broadly as information "capable of being associated with, or could reasonably be linked, directly or indirectly, with a particular consumer or household". This expansive definition increases the likelihood that synthetic data could fall within its scope, depending on its generation and potential for re-identification.
Deidentified Data Exclusion: While the CCPA excludes deidentified data from its application, the definition was updated in 2023 to mean "information that cannot reasonably be used to infer information about, or otherwise be linked, to a particular consumer". The crucial aspect lies in the "reasonableness" of connecting synthetic data to a specific individual or household. If synthetic data is generated using collected data as an input or comparator, a risk of re-identification persists through inference or by linking it with other datasets. The determination of what constitutes a "reasonable" risk threshold is a legal and policy question that courts and legislators will need to address, considering factors like who might engage in re-identification, for what purpose, and their capabilities.
Organizational Safeguards: In addition to the reasonableness requirement, the CCPA now mandates specific organizational safeguards, such as a public commitment not to reverse the deidentification process unless necessary for verification.
Inferences: The CCPA's definition of "personal information" explicitly includes "inferences, drawn from any of the information identified in this subdivision," used to create consumer profiles. The California Attorney General has opined that this right applies to internally generated inferences, regardless of their source, as long as they are of the kind listed in the Act and used to create a consumer profile. This suggests that even inferences derived from entirely artificial data, not directly based on collected personal data, could potentially be captured under the law, given the broad definition of "inference".
Common Challenges and Implications for Both Frameworks
The use of synthetic data presents common challenges to both GDPR and CCPA frameworks. The boundary between deidentified and identified data remains unreliable, and the risk of re-identification is expected to grow with the increasing availability of more collected data and synthetic datasets derived from such data.
Synthetic data also increases "spillover data privacy harms," where an individual's data enables the accumulation of data about others, and "collective data harms," where data analysis affects a group of individuals whose data may or may not be part of the dataset. This challenges the existing assumptions about the source of data and the sufficiency of individual control over privacy. Furthermore, combining synthetic data with techniques like differential privacy can lead to poor interpretability, making it difficult to understand which patterns of the original dataset are retained or lost. Even when collected data is used to generate synthetic data, there is an inherent risk that the model or dataset might indirectly leak some original personal data, especially in outlier situations. The rise of synthetic data necessitates a fundamental re-evaluation of current data privacy laws, their underlying rationale, and the assumptions upon which they are grounded. This includes considering a shift in focus from data collection to its uses and effects, from user consent to welfare, and from private data to inference data and collective harms.
Just as synthetic data can fall into an "uncanny valley" of fidelity , it also exists in a "legal uncanny valley." It is "almost" not personal data, but subtle traits or re-identification risks can pull it back into regulatory scope. The EDPB's opinion and the CCPA's broad definition of "inferences" serve as clear examples of this. The underlying issue is that current laws were primarily designed for "collected data" and struggle to fully encompass artificially generated data that mimics reality. This creates significant legal uncertainty and necessitates extreme caution. Organizations cannot assume synthetic data is automatically exempt from regulation. They must adopt a "privacy by evidence" approach , rigorously validating their synthetic data against legal standards and meticulously documenting its provenance to withstand regulatory scrutiny.
The discussion of "spillover effects" and "collective data harms" indicates that synthetic data can enable the accumulation of data about others or affect groups, even if individual data is not directly used. This moves beyond the traditional focus of privacy laws on individual control over personal data. This suggests a potential evolution in privacy law philosophy, from protecting individual data points to safeguarding societal well-being from information-induced harms. It raises fundamental questions about whether privacy laws should primarily protect individual data or society from the broader impacts of data analysis, irrespective of the data's origin.
Governance Frameworks, Auditability, and Accountability Principles
For synthetic data to be considered safe and compliant, it must be governed rigorously throughout its entire lifecycle, from creation to audit, sharing, and subsequent model development.
Risk Classification: Organizations should implement a clear risk matrix to classify synthetic data use cases, which helps in prioritizing oversight and informing the depth of documentation and board-level risk acceptance. Risk levels increase significantly when the personal information in the source dataset is high-risk or falls into special categories, when the training data used for generation was poorly anonymized or undocumented, when the synthetic method is not explainable or auditable, or when the output will be shared externally or used to drive critical decision-making.
Governance Structure: Synthetic data pipelines should be seamlessly integrated into existing organizational governance models, involving key roles such as the Data Protection Officer (DPO), Chief Information Security Officer (CISO) or Security Architect, Data Science Lead, and Compliance or Risk Officer. A centralized intake form or a dedicated review board should be established to assess each proposed use of synthetic data, escalating projects that involve unvalidated tools, high-risk categories, or external data sharing to privacy or legal functions.
Internal Audit Checklist: To support continuous compliance, organizations should develop an internal maturity model to benchmark how well synthetic data is governed. Key audit questions should include whether there is a clear record of the source data, if the generation method was validated against Recital 26 criteria, if privacy risks have been systematically scored, if the outputs are of high quality without being high risk, and if there is comprehensive documentation of the data's purpose, access controls, and sharing permissions. The financial sector, for example, must meticulously document the full lineage of synthetic datasets—their source, method, purpose, and exposure—to ensure audit-readiness, especially if regulatory models or board-level policies rely on this data.
The strong emphasis on Data Protection Impact Assessments (DPIAs), model cards, transparency, risk classification, and audit checklists highlights that legal compliance for synthetic data extends far beyond the technical generation process itself. It encompasses the entire lifecycle, robust governance, and demonstrable accountability. The GDPR's accountability principle is explicitly a driving force behind these requirements. This implies that legal and compliance teams must be integrated early and continuously into synthetic data initiatives. It is not merely a data science problem; it is an organizational governance challenge that demands cross-functional collaboration and the establishment of a robust, auditable framework.
Table 5: Regulatory Compliance Checklist for Synthetic Data (GDPR/CCPA Focus)
Emerging Trends and Future Directions
The field of synthetic data generation for privacy is dynamic and rapidly evolving, driven by ongoing research and the increasing demand for robust data solutions. Several key trends and future directions are shaping its trajectory.
Hybrid Models for Optimal Utility-Privacy Trade-offs
Future research is strongly advocating for the development of hybrid frameworks that integrate multiple privacy-preserving strategies. These approaches combine techniques such as differential privacy (DP), federated learning, and secure multiparty computation to achieve a more refined balance between data utility and robust privacy protections. Differential privacy, for instance, adds statistical noise to the data-generating process to minimize the risk of re-identifying individuals from the source dataset. However, it is important to note that while effective for privacy, differential privacy can sometimes amplify fairness issues present in original data and may reduce the utility of the synthetic data, particularly for downstream tasks. The emphasis on these hybrid models indicates a recognition that robust privacy in complex AI systems requires a layered, multi-faceted approach, driven by the increasing sophistication of privacy attacks and evolving regulatory demands. This implies that the future of privacy-preserving AI will be characterized by integrated, sophisticated architectures rather than isolated solutions, requiring organizations to develop expertise in multiple privacy-enhancing technologies and the ability to combine them effectively.
Advanced Techniques for Bias Detection and Mitigation
A critical future direction involves incorporating bias detection and mitigation techniques directly within the data generation pipelines. This proactive approach is essential because synthetic datasets, despite being artificially created, can inadvertently amplify biases if they are generated from skewed real-world distributions. Ensuring fairness in synthetic data is paramount to prevent undermining broader AI fairness goals. Mitigation strategies include rigorous filtering and weighting of synthetic outputs to de-emphasize biased content, careful blending of synthetic data with meticulously curated real data, and leveraging feedback mechanisms to iteratively improve fairness. The strong focus on embedding bias detection and mitigation, along with interpretability and explainability, directly into the generation pipelines represents a significant shift from reactive problem-solving to proactive ethical design. This acknowledges that ethical considerations are not externalities but fundamental aspects of synthetic data quality and trustworthiness. Companies that prioritize ethical design from the outset will likely gain a competitive advantage in terms of trust and regulatory compliance, particularly in sensitive domains.
Focus on Interpretability and Explainability in Generation
As synthetic data becomes more widely adopted in sensitive sectors like healthcare and finance, transparency regarding how and why certain synthetic samples are generated will become critically important. Embedding explainability mechanisms directly into synthetic data generators will be crucial for fostering greater trust among regulators, organizations, and end-users. This is particularly relevant given that the process of creating synthetic data can often be complex and opaque, making it difficult to understand its underlying generation logic. Enhancing interpretability will address concerns about the lack of transparency, which can otherwise undermine confidence in AI models trained on synthetic data.
Standardization of Evaluation Metrics and Benchmarks
The field of synthetic data urgently requires universally accepted evaluation benchmarks that comprehensively cover both data utility and privacy aspects. Currently, a lack of standardized metrics for modeling different data types and comparing generated results presents a significant challenge. Initiatives aimed at developing synthetic data "leaderboards," similar to established benchmarks like ImageNet in computer vision, could standardize comparisons, drive quality improvements, and accelerate research and development in the field.
The Importance of Cross-Disciplinary Collaborations
Synthetic data generation should not be viewed solely as a machine learning problem. The multifaceted challenges and implications necessitate robust collaborations between computer scientists, legal experts, ethicists, and domain specialists. Such cross-disciplinary efforts are essential to ensure that synthetic data initiatives align with broader societal values, legal frameworks, and ethical responsibilities. The consistent call for these collaborations underscores that the challenges of synthetic data for privacy are no longer purely technical; they are socio-technical problems with significant legal, ethical, and practical dimensions. This highlights that successful and sustainable adoption of synthetic data requires breaking down traditional silos within organizations, necessitating a holistic approach where legal, ethical, and business considerations inform technical development, ensuring that innovation aligns with broader societal values and regulatory realities.
Advancements in Time-Series Synthetic Data and Foundation Models
Emerging research is increasingly focusing on the generation of synthetic data for Time Series Foundation Models (TSFMs) and Time Series Large Language Models (TSLLMs). This indicates a growing emphasis on developing sophisticated methods for complex sequential data, which holds significant potential for applications in finance, healthcare, and IoT, where time-dependent data is prevalent and often sensitive.
Conclusion
Synthetic data generation stands as a transformative technology, offering a compelling and increasingly indispensable solution to the modern data dilemma. It empowers organizations to leverage the immense potential of data for innovation and advanced analytics while rigorously upholding individual privacy and robust security standards. The technology directly addresses critical challenges such as data scarcity, significantly accelerates the development and deployment of AI models, and mitigates substantial compliance and reputational risks associated with handling sensitive real-world information.
While offering immense potential, the successful implementation of synthetic data requires careful navigation of inherent complexities. These include ensuring high data fidelity to guarantee realism and utility, proactively addressing the potential for bias amplification, managing significant computational costs, and mitigating risks related to misinformation and adversarial AI. Furthermore, the evolving regulatory landscape, particularly concerning the nuanced classification of synthetic data under frameworks like GDPR and CCPA, demands meticulous attention and a proactive approach to compliance.
The field is rapidly evolving, with a clear trajectory towards more sophisticated hybrid models that optimize the utility-privacy trade-off. There is a growing emphasis on proactive ethical design, embedding bias detection and mitigation directly into generation pipelines, and fostering greater interpretability and explainability. The urgent need for standardized evaluation metrics and benchmarks will drive quality improvements and facilitate broader adoption. Ultimately, the future success and responsible deployment of synthetic data hinge on essential cross-disciplinary collaboration, ensuring that technological advancements align with legal requirements, ethical principles, and societal values. Synthetic data is not merely a technical fix but a strategic imperative that reshapes how organizations access, manage, and derive value from data in a privacy-conscious world.
Recommendations for Implementation and Governance
To effectively leverage synthetic data generation while navigating its complexities, organizations should consider the following recommendations for implementation and governance:
Strategic Adoption
Assess Use Cases: Prioritize the adoption of synthetic data for scenarios where real data is inherently sensitive, scarce, or prohibitively costly to acquire and manage. Focus on high-value areas such as healthcare research, financial risk modeling, human resources analytics, and research and development that require extensive, yet private, datasets.
Pilot Programs: Initiate controlled pilot programs to rigorously validate the utility and privacy guarantees of synthetic data solutions within specific contexts before embarking on widespread deployment. This iterative approach allows for learning and refinement.
Technical Implementation
Advanced Methodologies: Invest in and strategically utilize advanced machine learning techniques, including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Diffusion Models, to achieve higher fidelity and capture the complexity of real-world data. The choice of methodology should be tailored to the specific data type and use case.
Robust Validation Frameworks: Implement rigorous validation frameworks, such as the Possibility of Reproducibility (PoR) metric and comprehensive statistical comparisons, to objectively ensure that synthetic data accurately reflects the statistical distributions of real-world data and maintains the necessary utility for its intended purpose.
Bias Mitigation by Design: Integrate bias detection and mitigation techniques directly into the synthetic data generation pipeline. This proactive approach, rather than reactive fixes, is crucial for preventing the amplification of existing biases and ensuring the fairness and equity of AI models trained on synthetic data.
Legal & Compliance Governance
Thorough Legal Assessment: Conduct comprehensive legal assessments, including Data Protection Impact Assessments (DPIAs), to determine whether generated synthetic data falls under the purview of relevant privacy regulations (e.g., GDPR, CCPA) based on its re-identification risk. Organizations must avoid assuming automatic exemption from these laws.
"Privacy by Evidence" Approach: Adopt a "privacy by evidence" methodology, meticulously documenting the entire lineage of synthetic datasets, including the source of the original data, the generation method and parameters used, its intended purpose, and how it will be exposed or shared. This ensures audit-readiness and demonstrable compliance.
Transparency & Explainability: Strive for transparency in synthetic data generation processes. Where feasible, embed explainability mechanisms into the generative models, particularly for applications in sensitive domains, to build trust among regulators, organizations, and end-users.
Continuous Monitoring: Implement continuous monitoring of privacy-related metrics, such as leakage scores (measuring identical rows between synthetic and original datasets) and proximity scores (measuring the statistical distance between datasets), to identify and address any potential privacy risks as the data is used and evolves.
Organizational & Ethical Considerations
Cross-Functional Teams: Foster strong collaboration between diverse teams, including data scientists, legal counsel, ethicists, and domain experts. This interdisciplinary approach ensures a holistic understanding and management of the technical, legal, and ethical dimensions of synthetic data.
Ethical Guidelines: Develop and enforce internal ethical guidelines for the responsible use of synthetic data. These guidelines should explicitly address potential misuses, such as the creation of misinformation or the training of adversarial AI, and ensure that synthetic data initiatives align with broader societal values.
Resource Allocation: Accurately account for and allocate appropriate resources for the significant computational costs associated with high-quality synthetic data generation and the necessary validation infrastructure. This includes investments in scalable cloud-based solutions or high-performance computing environments.