The Right to Data Portability: Empowering Businesses and Individuals in the Era of Data Privacy
Get ready to revolutionize your business with the key to success in today's digital world: data. Unleash its game-changing potential and open up a whole new world of opportunities with the Right to Data Portability.


The Right to Data Portability (RtDP) stands as one of the most significant and complex innovations in modern data protection law. Codified primarily in Article 20 of the European Union's General Data Protection Regulation (GDPR), it was conceived with a dual purpose: to empower individuals by granting them unprecedented control over their personal data, and to reshape digital markets by dismantling data silos and fostering competition. This report provides an exhaustive analysis of the RtDP, examining its legal foundations, its practical impact on individuals and businesses, the profound technical and security challenges of its implementation, and its evolving role in an era of rapid technological advancement.
The analysis reveals that the RtDP is built upon a foundational tension between its identity as a fundamental right focused on individual privacy and its function as a tool for economic regulation. This inherent conflict has shaped its legal design, resulting in a right that, while powerful in theory, is constrained by significant limitations in practice. For individuals, the right promises a new era of digital autonomy, enabling them to seamlessly switch service providers in sectors from finance and healthcare to social media and entertainment. For businesses, it presents both a compliance mandate fraught with technical and financial hurdles and a strategic opportunity to build consumer trust, enhance customer experience, and innovate new data-driven services.
However, a critical evaluation of the RtDP's efficacy shows mixed results. The right's pro-competitive ambitions have been largely unfulfilled, stymied by a narrow scope that excludes valuable inferred data, the persistent challenge of network effects, and a systemic "chicken-and-egg" problem where a lack of receiving services discourages user adoption. The practical implementation of portability is further complicated by the technical realities of achieving true interoperability between disparate systems and the critical need to secure vast amounts of sensitive data in transit.
In response to these limitations, a new wave of more prescriptive regulation, such as the EU's Digital Markets Act and Data Act, has emerged. This signals a regulatory evolution, moving from the general principles of the GDPR's RtDP toward more targeted mandates designed to force the data-sharing and interoperability outcomes the original right sought to encourage. Looking forward, the proliferation of the Internet of Things (IoT) and Artificial Intelligence (AI) will both exacerbate the challenges and amplify the potential of data portability, pushing the discourse toward more human-centric, decentralized data ecosystems. This report concludes with strategic recommendations for policymakers and businesses, advocating for a shift from mere compliance to strategic data enablement in order to unlock the full, transformative potential of data portability in the global digital economy.
Part I: The Legal and Conceptual Foundations of Data Portability
This part establishes the legal bedrock of the Right to Data Portability, tracing its origins, defining its mechanics under the GDPR, and situating it within the broader landscape of global data protection law.
Section 1: Defining the Right to Data Portability
1.1 The Genesis of a New Right: Legislative Intent and Core Objectives
The Right to Data Portability (RtDP) was a landmark innovation introduced by the General Data Protection Regulation (GDPR), which came into force in 2018, replacing the outdated 1995 Data Protection Directive. The creation of this new right was a direct response to the realities of the modern digital economy, where vast amounts of personal data are collected and controlled by a concentrated number of online service providers. The legislative intent behind the RtDP was twofold, reflecting a blend of individual rights and economic policy objectives.
The primary objective was the empowerment of the individual. The RtDP was designed to enhance data subjects' control over their personal data, reinforcing the fundamental right to informational self-determination. The goal was to shift the balance of power, putting users "back in charge of their own data" and giving them the autonomy to manage their digital identity across different services. This framing establishes the right as an extension of the pre-existing right of access, but with a new focus on active reuse and control rather than passive verification.
The co-equal objective was economic and pro-competitive. European legislators intended for the RtDP to be a powerful tool to stimulate competition and innovation in digital markets. By making it easier for users to move their data, the right aims to lower switching costs, reduce the "vendor lock-in" effect that traps consumers within a single platform's ecosystem, and thereby dismantle the "walled gardens" or "data silos" that characterize many digital markets. This, in theory, would level the playing field, allowing smaller businesses and new entrants to compete more effectively with established incumbents. In this sense, data portability is conceived as a form of interoperability, intended to create a more fluid, dynamic, and competitive data ecosystem.
This dual identity—a fundamental right for privacy and a regulatory tool for competition—creates an inherent tension that is central to understanding the RtDP's design and its subsequent limitations. While the GDPR is fundamentally a human rights law, the RtDP is tasked with solving a systemic market problem. A right designed purely for privacy might have a narrow, strictly defined scope. In contrast, a right designed to effectively promote competition would need a much broader scope, encompassing not just data the user provides but also data the platform creates about the user, such as behavioral inferences or social connections, which are often the true source of a platform's competitive advantage. The final legal text of Article 20 of the GDPR represents a compromise between these two poles. It is more powerful than a simple right of access but falls short of the comprehensive scope that many argue is necessary for true competitive disruption, most notably by excluding inferred data. This foundational compromise is the source of many of the practical challenges and academic critiques that have emerged since its implementation.
1.2 The Mechanics of Article 20 of the GDPR: Scope, Conditions, and Application
Article 20 of the GDPR provides the definitive legal mechanics for the Right to Data Portability. It grants a data subject two distinct but related entitlements:
The right to receive a copy of their personal data from a data controller in a structured, commonly used, and machine-readable format. This allows the individual to obtain their data for personal storage and reuse.
The right to have that data transmitted directly from the original controller to another controller, wherever this is "technically feasible".
The application of this right is not universal; it is subject to a strict set of preconditions that significantly limit its scope. The right only applies when:
Lawful Basis: The controller's legal basis for processing the personal data is either the data subject's consent (pursuant to Article 6(1)(a) or 9(2)(a)) or the performance of a contract to which the data subject is a party (pursuant to Article 6(1)(b)). This is a critical limitation, as it excludes data processed under other lawful bases, such as the controller's legitimate interests, compliance with a legal obligation, or the performance of a task in the public interest.
Automated Means: The processing must be carried out by automated means. This explicitly excludes manual processing and paper-based files from the scope of the right.
Furthermore, the right must be facilitated "without hindrance" from the controller. This means that organizations cannot place undue legal, technical, or financial obstacles in the way of a data subject exercising their right. This could include, for example, charging excessive fees, using proprietary formats designed to impede reuse, or creating unnecessarily complex user interfaces for requesting the data.
1.3 The Data in Scope: "Provided by," "Observed," and the Exclusion of "Inferred" Data
A central and often contentious aspect of the RtDP is the definition of which data is actually portable. Article 20 specifies that the right applies to "personal data concerning him or her, which he or she has provided to a controller". Regulatory guidance from bodies like the Article 29 Working Party (now the European Data Protection Board) has clarified that this phrase should be interpreted broadly and is not limited to data actively typed in by a user.
The data in scope is generally understood to include two categories:
Actively and Knowingly Provided Data: This is information that the user consciously provides, such as their username, email address, age, or information filled out in an online form.
Observed Data: This encompasses data generated by and collected from the individual's activity while using a service or device. This is a crucial extension that significantly broadens the right's utility. Examples include search history, website usage history, traffic and location data, and "raw" data from connected objects like smart meters, fitness trackers, and other wearable devices. For instance, a user's playlist history on a music streaming service or their purchase history on an e-commerce site would fall under this category.
However, a critical line is drawn at inferred data or derived data. This is new data that the controller creates based on the data provided by the user, often through analysis or algorithmic processing. Examples include a credit score calculated by a bank, a user profile created for advertising purposes, an algorithmic recommendation, or a health risk assessment generated by a wellness app. This type of data is generally considered to be outside the scope of the Right to Data Portability. This exclusion is one of the most significant limitations on the right's ability to foster competition, as this inferred data is often the most valuable asset a platform holds and the primary driver of its competitive advantage and lock-in effects. A user can take their raw fitness data, but not the proprietary health insights the platform generated from it.
Section 2: The Global Regulatory Tapestry
2.1 A Comparative Analysis: GDPR vs. CCPA/CPRA
While the GDPR pioneered the RtDP, the concept has been adopted in various forms by other major data protection laws around the world. The most significant point of comparison is with the California Consumer Privacy Act (CCPA), as amended by the California Privacy Rights Act (CPRA). Although both frameworks aim to empower consumers, their approaches to portability reveal key differences in scope, mechanics, and philosophy.
Scope and Applicability: The GDPR has a very broad scope, applying to any organization (a "data controller" or "processor") anywhere in the world that processes the personal data of data subjects within the European Union, regardless of the organization's size or business model. The CCPA, in contrast, is more targeted. It applies only to for-profit businesses that meet specific thresholds, such as having annual gross revenue over $25 million, dealing with the personal information of 100,000 or more California consumers, or deriving 50% or more of their annual revenue from selling or sharing consumers' personal information. This means many smaller businesses are exempt from the CCPA's requirements.
Definition of Personal Data: The GDPR defines "personal data" very broadly as any information relating to an identified or identifiable natural person. The CCPA's definition of "personal information" is similarly broad but is explicitly linked to a "consumer, household, or device," reflecting its consumer-protection focus rather than a fundamental-rights focus.
The Nature of the Right: This is the most crucial distinction. The GDPR establishes a standalone, explicit Right to Data Portability in Article 20, with two clear components: the right to receive data and the right to transmit it directly to another controller. The CCPA's right is more accurately described as an enhanced right of access. It grants consumers the right to obtain their personal information in a format that is "portable and, to the extent technically feasible, in a readily useable format that allows the consumer to transmit this information to another entity without hindrance". While similar in spirit, it lacks the GDPR's explicit provision for a direct controller-to-controller transmission request and is often seen as a less potent version of the right.
Consent Model: The underlying legal frameworks differ significantly. The GDPR operates on a default "opt-in" basis for processing that relies on consent; consent must be affirmative, informed, and freely given. The CCPA, by contrast, generally uses an "opt-out" model, particularly for the sale or sharing of personal information. Businesses can collect and process data by default but must provide consumers with a clear mechanism to opt out.
The following table provides a structured comparison of these key differences.
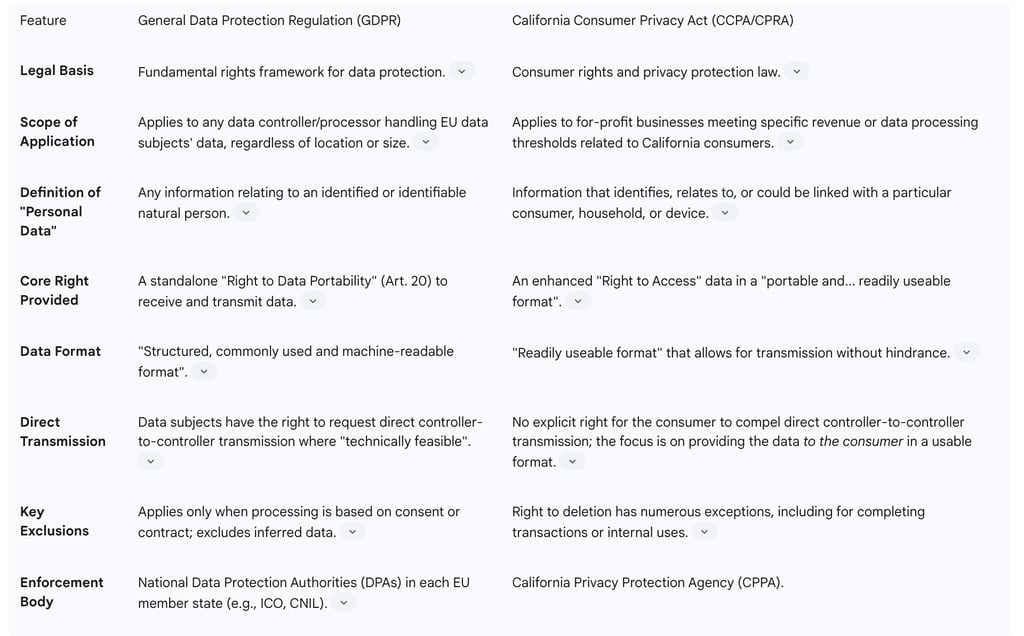

This comparative analysis is crucial for global organizations, which must navigate these differing legal landscapes. A compliance strategy built solely for the CCPA would likely fall short of the GDPR's more stringent requirements, particularly regarding the legal bases for processing and the mechanics of direct data transmission.
2.2 Emerging Frameworks: Brazil's LGPD and Other Global Trends
The influence of the GDPR's model extends far beyond California. A global trend towards adopting similar data protection principles is evident, with data portability emerging as a key feature of modern privacy legislation.
Brazil's Lei Geral de Proteção de Dados (LGPD), which came into force in 2020, is a prominent example. The LGPD is heavily modeled on the GDPR and includes a near-identical right to data portability, empowering data subjects to obtain their data and transfer it between service providers. This demonstrates a significant convergence of regulatory thought in major economies.
Furthermore, other nations are following suit. Jurisdictions such as India, Canada, and Australia have either enacted or are in the process of developing comprehensive data privacy laws that include provisions for data portability. This global movement underscores the recognition of data portability as a fundamental component of empowering individuals in the digital age and as a potential lever for influencing market dynamics. For multinational corporations, this trend signals a future where facilitating data portability is not just a European or Californian requirement, but a global compliance baseline.
2.3 The Interplay with Other Data Subject Rights: Access, Erasure, and Restriction
The Right to Data Portability does not exist in a vacuum; it is part of a suite of rights granted to individuals under the GDPR. Understanding its relationship with other key rights—specifically the right of access, the right to erasure, and the right to restriction—is essential for both individuals seeking to exercise their rights and organizations obligated to fulfill them.
Right of Access (Article 15): While closely related, the RtDP and the right of access serve different purposes and have different scopes. The right of access is fundamentally a right of verification. It allows individuals to obtain a copy of their data to check its accuracy and understand how it is being processed. The RtDP, by contrast, is a right of reuse. It is designed to enable the individual to take their data and use it for other purposes, including transferring it to a new service. This distinction leads to critical differences in what data is covered and in what format it must be provided. The right of access is broader in scope, covering all personal data a controller holds about an individual, including inferred and derived data like credit scores or user profiles. The RtDP is narrower, applying only to data "provided by" the subject. The format requirement for access is simply a "copy," which could be a PDF summary, whereas portability mandates a "structured, commonly used, and machine-readable format" suitable for automated processing.
Right to Erasure (Article 17): Often called the "right to be forgotten," this is an independent right from portability. Exercising the RtDP does not lead to the automatic deletion of the data from the source controller's systems. The original controller can continue to store and process the data according to its original lawful basis. If an individual wants their data deleted, they must make a separate request under Article 17. This right is also not absolute and is subject to its own conditions, such as when the data is no longer necessary for its original purpose, or when the user withdraws consent. It does not apply if the controller has an overriding legal obligation to retain the data.
Right to Restriction (Article 18): This right allows a data subject to request that a controller temporarily stop processing their personal data (other than for storage) in specific circumstances. It can be seen as an alternative or complementary right. For example, a user might request a restriction on processing while they are contesting the accuracy of their data (in conjunction with the right to rectification) or while a controller is considering their objection to processing.
The table below clarifies these distinctions for operational purposes.


For organizations, this clarity is paramount. When a user submits a request, the organization must first determine which right is being invoked to understand its specific obligations regarding the scope of data, the required format, and the subsequent actions it must take.
Part II: The Dual Impact on Individuals and Businesses
This part moves from legal theory to practical application, examining the real-world consequences of the RtDP for its two main constituencies.
Section 3: Empowering the Digital Citizen
3.1 From Data Subject to Data Controller: The Promise of Personal Data Autonomy
The Right to Data Portability represents a fundamental philosophical shift in data governance. It aims to elevate the individual from a passive "data subject," whose information is collected and used by others, to an active agent with genuine autonomy over their digital identity. By giving individuals the right to obtain and reuse their data, the law effectively empowers them to act as a controller of their own portable data copy, deciding how and where it is used.
This empowerment is central to the right's design. It directly confronts the issue of "data lock-in," a situation where individuals feel trapped with a particular service provider because the cost and effort of leaving their accumulated data—their photos, contacts, playlists, or purchase history—is prohibitively high. Portability dismantles this barrier, giving users the practical freedom to switch to new platforms that may offer better services, more competitive pricing, or data handling practices that better align with their personal values. This increased control and reduced dependency on single platforms is the core promise of personal data autonomy in the digital age.
3.2 Practical Applications and Consumer Benefits: Real-World Scenarios
The theoretical benefits of data portability translate into tangible advantages for consumers across a wide range of sectors. The ability to move data seamlessly creates convenience, enables new services, and provides valuable insights. Real-world applications include:
Financial Services and Open Banking: This is perhaps the most mature example of data portability in action. Consumers can authorize the transfer of their transaction history from their bank to third-party fintech applications. These apps can then provide sophisticated budgeting analysis, spending habit insights, or compare financial products to find the user a better deal on loans or savings accounts. The UK's Open Banking initiative, which mandated the use of APIs for data sharing, has been a key driver in this area.
Social Media and Content Platforms: Major platforms like Google and Meta (Facebook) have developed tools (e.g., Google Takeout, Facebook's "Download Your Information") that allow users to export their data. A user can download years of photos, a complete list of contacts, or their entire post history, either for personal backup or to potentially migrate to a new service.
Health and Fitness: Users of wearable devices from companies like Fitbit, Garmin, or Oura can export their detailed activity data, such as step counts, heart rate history, and sleep patterns. This data can be imported into different health analysis platforms, shared with a personal trainer, or provided to a healthcare professional to give a more complete picture of their well-being.
Music and Entertainment Streaming: While not always a native feature, third-party tools have emerged that leverage platform APIs to allow users to migrate their curated playlists and listening history from one service (e.g., Spotify) to a competitor (e.g., Apple Music). This removes a significant friction point for users who have invested years in personalizing their music library.
Telecommunications and Utilities: Data portability enables a consumer to obtain their detailed usage data (e.g., energy consumption from a smart meter) and use it to find a more competitive tariff from a rival provider. Similarly, when switching mobile carriers, a user could port their preferences and usage history to receive more personalized service from the new operator.
E-commerce: A consumer could transfer their purchase history and product preferences from one online marketplace to another, allowing the new platform to offer more relevant and personalized recommendations from day one.
3.3 Exercising the Right: The Process, Challenges, and the Role of Consumer Trust
For an individual, the process of exercising the right to data portability is designed to be straightforward. A request can be made either verbally or in writing, and it does not need to be in a specific format; it simply needs to clearly state what data is being requested for portability.
Once a request is made, the organization has one calendar month to respond. This period can be extended by an additional two months for particularly complex or numerous requests, but the organization must inform the individual of the extension within the first month and explain why it is necessary. Before releasing the data, the organization may need to take reasonable steps to verify the requester's identity to prevent fraud. If the organization refuses the request, it must inform the individual of the reasons and of their right to complain to a supervisory authority (like the UK's Information Commissioner's Office - ICO) or to seek a judicial remedy.
Despite the intended simplicity, consumers face practical challenges. One significant consideration is that once the data is transferred to the individual, they become responsible for its security. The new storage location—be it a personal computer or another service—may have weaker security measures than the original, highly-resourced controller. Organizations are encouraged to make individuals aware of this risk.
Ultimately, the widespread adoption of data portability hinges on consumer trust. The entire process requires trust at multiple points: trust that the original controller will handle the request properly and securely, and trust that the receiving entity will protect the data and use it for the consumer's benefit. Businesses that demonstrate a commitment to privacy by facilitating portability in a transparent and secure manner are more likely to earn and maintain the trust and loyalty of their customers. A breakdown in trust at any point in the chain can act as a powerful deterrent, undermining the right's utility.
Section 4: The Corporate Mandate: Compliance, Risk, and Opportunity
4.1 Navigating the Compliance Labyrinth: Obligations, Timelines, and Verification
For businesses acting as data controllers, the Right to Data Portability imposes a clear set of legal obligations that require robust internal processes and technical capabilities. The primary obligation is to respond to a valid portability request without undue delay, and at the latest within one month of receipt.
A critical first step in handling a request is identity verification. Both the GDPR and CCPA require businesses to verify the identity of the individual making the request before releasing any personal information. This is a crucial security measure to prevent data breaches and fraudulent requests where an attacker impersonates a legitimate user. Accepted methods include knowledge-based authentication (e.g., security questions), possession-based factors (e.g., a one-time code sent to a mobile phone), and inherence factors (e.g., fingerprint or facial scans).
While the right is strong, it is not absolute. A business can refuse to comply with a request if it is deemed "manifestly unfounded or excessive". This is a high threshold to meet, and the burden of proof lies with the organization. A request may be considered manifestly unfounded if it is malicious in intent—for instance, if the individual explicitly states they are making requests simply to cause disruption or harass the organization. A request may be deemed excessive if it is repetitive, although an individual has legitimate reasons to repeat a request if, for example, the first one was not handled properly.
To meet these obligations efficiently, a practical prerequisite for any modern business is effective data governance. This includes implementing data mapping, classification, and discovery tools. These systems allow an organization to automate the process of identifying where a specific individual's personal data resides across its various networks and databases, enabling it to be found, retrieved, and packaged for portability in a timely manner. Without such systems, responding to requests within the one-month deadline can be a significant, if not impossible, manual effort.
4.2 Data Portability as a Business Strategy: Building Trust and Enhancing Customer Experience
While often viewed through the lens of a compliance burden, data portability can be reframed as a powerful tool for business strategy. Proactively embracing the right can become a key differentiator in a competitive market, primarily by building consumer trust and enhancing the overall customer experience.
By offering a transparent, secure, and seamless portability process, a company signals its commitment to customer privacy and empowerment. This can foster significant goodwill and brand loyalty. In an age of increasing consumer awareness about data privacy, businesses that respect digital rights are more likely to attract and retain customers. There is even a "paradoxical effect" on customer retention: when consumers know they are not locked in and can leave at any time, they may feel more secure and be more inclined to stay with a provider they trust.
Furthermore, data portability can directly improve the customer experience, especially for new customers. An organization that can easily import a new customer's data from a competitor dramatically reduces onboarding friction. For example, a new bank that can instantly import a customer's transaction history and payee list from their old bank provides immediate value and a much smoother transition. This can lead to a significant competitive advantage and lower customer acquisition costs, as the complex and expensive back-office processes traditionally associated with switching services are simplified.
4.3 The Economic Calculus: Costs of Implementation vs. Long-Term Competitive Advantage
The implementation of data portability is not without significant cost. Businesses must make substantial upfront and ongoing investments in several areas:
Data Infrastructure: Upgrading legacy systems and data architectures to support standardized, machine-readable formats and secure transfer mechanisms is often necessary.
API Development: Building and maintaining secure Application Programming Interfaces (APIs) to facilitate seamless data transfer is a technically demanding and resource-intensive task.
Security Measures: Implementing robust encryption, authentication, and monitoring systems to protect data during transfer is a critical and costly requirement.
Operational Costs: Training staff, developing clear internal policies, and managing the request-fulfillment process all carry ongoing operational costs.
These costs can represent a disproportionate burden for small and medium-sized enterprises (SMEs) and startups, which may lack the financial and technical resources of larger incumbents. This has led to concerns that portability mandates could, ironically, act as a barrier to market entry for the very challengers they are meant to help.
However, these costs must be weighed against the potential for long-term strategic and competitive advantage. In a market with effective data portability, competition shifts away from leveraging data lock-in and towards improving service quality, innovation, and pricing. This dynamic environment can also unlock entirely new business models and revenue streams. The most prominent example is the ecosystem of third-party applications that has grown around Open Banking, offering services like financial planning, automated accounting, and credit analysis—services that would not exist without access to portable banking data. By positioning themselves not just as data holders but also as data recipients, businesses can leverage imported data to create innovative, value-added services that attract new customers and deepen relationships with existing ones.
The effectiveness of data portability, however, depends on a functional ecosystem. This can be understood as a value chain with three essential actors: the data holder (the exporting controller), the data subject (the individual initiating the transfer), and the data recipient (the importing controller). The entire process is constrained by the weakest link in this chain. The data holder may have a natural disincentive to make portability too easy, as it facilitates customer churn. The data recipient may lack the technical infrastructure or a viable business model to accept and use the ported data, especially if it comes in varied formats from multiple sources. Finally, the individual at the center of the process may lack the time, technical expertise, or, crucially, the trust in the system to initiate the transfer in the first place. This dynamic often creates a "chicken-and-egg problem": without compelling destinations, users have little incentive to port their data, and without a steady stream of portable data, new and innovative services struggle to emerge and challenge incumbents. This reveals that the legal right alone is insufficient; the entire ecosystem, including the technical infrastructure and the economic incentives for all three parties, must be fostered for portability to achieve its transformative potential.
Part III: Technical Realities and Security Imperatives
This part delves into the technical "how" of data portability, exploring the standards, tools, and challenges of making data flow securely and meaningfully between systems.
Section 5: The Architecture of Portability
5.1 From Theory to Practice: Implementing "Structured, Commonly Used, and Machine-Readable" Formats
Article 20 of the GDPR mandates that portable data be provided in a format that is "structured, commonly used and machine-readable." These are not merely suggestions but technical requirements that dictate the architecture of portability systems.
Structured: This means the data must be organized in a deterministic way that allows software to easily extract specific data elements. A simple text file with paragraphs of information would not be structured, whereas a spreadsheet with clearly defined rows and columns is. The structure ensures that the data's context and relationships are preserved.
Commonly Used: The format should be open and widely supported, not a proprietary format that would require specialized or expensive software to process. The goal is to prevent organizations from complying with the letter of the law while violating its spirit by providing data in an obscure format that effectively hinders reuse.
Machine-Readable: This is the foundational requirement that the data must be in a format that can be automatically read and processed by a computer. This enables the seamless transfer and integration of data into another system without manual intervention.
In practice, several data formats have emerged as de facto standards for fulfilling these requirements. The choice of format often depends on the complexity of the data being transferred:
CSV (Comma-Separated Values): A simple, text-based format for storing tabular data. It is ideal for exporting straightforward datasets like contact lists or transaction histories.
JSON (JavaScript Object Notation): A lightweight, text-based format that uses human-readable key-value pairs. It is extremely versatile and well-suited for web-based data transfers and complex, nested data structures, such as a user's profile information and their associated posts and comments.
XML (Extensible Markup Language): A flexible, tag-based format that is also widely used for exchanging structured data between different systems. Like JSON, it can handle complex data hierarchies.
For more specialized, large-scale data scenarios, particularly in the context of big data and analytics, other formats like Apache Parquet (a columnar storage format) and Apache Avro (a row-based binary format) may be used, though these are less common for typical consumer-facing portability requests.
The following table summarizes the primary formats and their use cases.
Format
Key Characteristics
Primary Use Case for Portability
CSV (.csv)
Text-based, tabular, values separated by delimiters.
Simple tabular data: contact lists, bank statements, basic spreadsheets.
JSON (.json)
Lightweight, text-based, uses key-value pairs, supports complex nested objects.
Web data, API responses, user profiles, social media data, configuration files.
XML (.xml)
Text-based, uses tags to define elements, hierarchical, highly extensible.
Document exchange, data transfer between enterprise systems, legacy system integration.
Parquet
Binary, columnar storage, highly compressed and efficient for analytics.
Large-scale analytical datasets, data warehouse exports, AI/ML model training data.
This variety of "standard" formats itself hints at the underlying challenge of interoperability. A system designed to ingest JSON data cannot seamlessly process a CSV file without a data transformation layer, adding another layer of complexity to the portability process.
5.2 The Role of APIs and the Data Transfer Project (DTP)
While a user can request a file to download, the most efficient and secure method for achieving direct controller-to-controller transmission is through the use of Application Programming Interfaces (APIs). An API acts as a secure doorway that allows one authorized system to request and receive data from another in a standardized, automated way.
Recognizing the need for a common framework to facilitate these API-based transfers, a consortium of major technology companies—including Google, Apple, Meta, Microsoft, and Twitter—launched the Data Transfer Project (DTP) in 2018. The DTP is an open-source initiative aimed at building a common framework with open-source code for secure, direct, service-to-service data portability.
The key innovation of the DTP is that it enables a transfer to be initiated by a user without them first having to download the data to their personal device and then upload it to the new service. This direct transfer model is not only more convenient for the user (as it doesn't require local storage or use personal bandwidth) but is also more secure, as it reduces the number of points at which the data could be exposed. The DTP provides a practical, collaborative solution to fulfilling the "technically feasible" clause of Article 20(2), and its open-source nature means that even smaller companies without extensive engineering resources can adopt its tools to offer robust portability options.
5.3 The Interoperability Conundrum: Overcoming Data Harmonization and Standardization Hurdles
Data portability is fundamentally a form of interoperability—the ability of different systems to exchange information and use it meaningfully. Achieving true, seamless interoperability is one of the greatest technical challenges in the digital economy and a primary barrier to the success of data portability.
The core challenges are multifaceted:
Lack of Universal Standards: While formats like JSON and CSV are common, there is no single, universally mandated standard for how data should be structured within those formats. A "contact" in Google's system may have different fields and structure than a "contact" in Microsoft's system. This requires complex data mapping and transformation to align the data from the source to the destination, a process that can be error-prone and result in data loss. Existing standards and adaptation tools are often insufficient for the flexibility that users and businesses require.
Data Harmonization: This goes beyond format to the semantic meaning of data. Organizations must align not just the structure but also the vocabularies and data models to ensure that the data is understood consistently across systems. This is a massive challenge, especially in complex sectors like healthcare.
Technical and Financial Burden: Implementing the necessary infrastructure for interoperability is a significant undertaking. It requires substantial investment in modernizing legacy systems, developing robust APIs, and dedicating skilled engineering resources to the task.
Business and Cultural Resistance: True interoperability often requires a level of technical integration and sharing of data models that can run counter to a business model built on creating a unique and self-contained ecosystem. Companies may be reluctant to make it too easy for their data to be used by a competitor, creating a business disincentive that hinders technical collaboration.
Section 6: Securing Data in Transit
6.1 A Shared Responsibility: Mitigating Risks of Data Breaches and Misuse
The act of moving data from one system to another inherently introduces security risks. Transferring large volumes of personal, often sensitive, data across the internet increases the digital "attack surface" and creates new opportunities for data breaches, corruption, or misuse. Managing these risks requires a clear understanding of the chain of responsibility.
The source controller (the organization providing the data) is legally responsible for ensuring the security of the data transfer process itself. This includes verifying the user's identity and using secure methods to transmit the data. However, once the data has been successfully and securely delivered to the individual or to the designated receiving controller, the source controller's responsibility for that copy of the data ends. They are not liable for any subsequent processing or potential security lapses by the individual or the new organization. This creates a "shared responsibility" model, where each party in the chain—the source, the user, and the recipient—has a distinct role to play in protecting the data. A failure by any party can compromise the entire process, and a significant challenge is that these parties, especially consumers, may not fully understand their respective responsibilities.
6.2 Technical Safeguards: Encryption, Authentication, and Secure Protocols
To mitigate the risks inherent in data transfer, a multi-layered approach to security is essential. Organizations must implement a suite of technical safeguards to protect data throughout the portability lifecycle.
Encryption: This is the most critical safeguard. Data must be protected with strong encryption both "in transit" (while it is moving across the network) and "at rest" (when it is stored on a server or device). For data in transit, this is achieved using secure transport protocols like HTTPS (Hypertext Transfer Protocol Secure) and TLS (Transport Layer Security). For data at rest, strong encryption standards like AES-256 should be applied.
Identity and Access Management (IAM): IAM is crucial for ensuring that only the legitimate data subject can initiate a portability request and that the data is delivered only to an authorized destination. This involves two key components:
Authentication: Verifying the user's identity using robust methods, preferably Multi-Factor Authentication (MFA), which combines something the user knows (a password), something they have (a security key or phone), or something they are (a fingerprint).
Authorization: Ensuring that systems have the correct permissions to access and transfer data, following the principle of least privilege so that they only have access to the data necessary for the task.
Secure Infrastructure and Protocols: For large-scale or highly sensitive data transfers, organizations should utilize secure network connections, such as Virtual Private Network (VPN) tunnels or dedicated private connections (e.g., AWS Direct Connect, Azure ExpressRoute), to create a secure channel between environments. Secure file transfer protocols should also be used.
6.3 Privacy by Design: Embedding Portability Security into System Architecture
Security for data portability cannot be a bolt-on feature; it must be integrated into the very fabric of an organization's systems and processes. This aligns with the core GDPR principle of "Privacy by Design", which mandates that data protection be considered from the outset of any new system, product, or process design.
Applying this principle to data portability means that organizations should proactively build security into their portability architecture. This includes:
Developing automated tools for data mapping and discovery to ensure that only the correct data is retrieved for a request, minimizing the risk of accidental over-sharing.
Implementing automated and standardized identity verification workflows to ensure consistency and robustness.
Building secure logging and monitoring systems to track the entire transfer process. This allows for the identification of anomalous activity, potential breach attempts, or transmission failures, providing a crucial audit trail.
By embedding these security measures into the system architecture, businesses can move from a reactive to a proactive security posture, ensuring that they can fulfill portability requests not only in a compliant manner but also in a way that protects their users' data and maintains their trust.
Part IV: A Critical Evaluation and Future Outlook
This final part provides a critical assessment of the RtDP's real-world impact and looks ahead to its future in an increasingly complex technological landscape.
Section 7: The Efficacy of Data Portability: A Critical Review
7.1 The Competition Conundrum: Does Portability Truly Dismantle Walled Gardens?
The promise that data portability would act as a powerful pro-competitive tool has been a central justification for the right since its inception. The theory is compelling: by reducing switching costs for consumers, the RtDP should increase competitive pressure on incumbent firms, forcing them to innovate, improve service quality, and offer more attractive pricing to retain customers. The classic analogy is to telephone number portability, which was mandated in the U.S. in 1996. Studies have shown that this policy led to tangible consumer benefits, with mobile plan prices dropping as customers could more easily switch carriers without losing their established phone number.
However, the application of this logic to the complex digital platform economy has yielded far more ambiguous and often disappointing results. In some sectors, portability has had little discernible impact on consumer behavior. A notable example is the UK banking sector, where the introduction of a seamless Current Account Switching Service (CASS) did not lead to a significant increase in switching activity, which remained anemic. This suggests that data inertia and other factors can outweigh the benefits of a frictionless transfer process. More concerningly, some economic research has suggested that, under certain market conditions, data portability regulations could paradoxically lead to less competition and higher market concentration, as it may alter firms' strategic incentives in unforeseen ways.
The critique of the right's competitive efficacy deepens when applied to dominant digital platforms that benefit from strong network effects. The reasons for its limited success in this context are fundamental:
The Problem of Incomplete Data: A user cannot replicate their experience on a service like Facebook simply by porting their own data. The exported data includes their posts, photos, and comments, but it crucially lacks the context in which that data was shared, the inferred data the platform has generated about them, and, most importantly, the social graph—the web of connections and interactions with other users. Trying to rebuild a social network from exported user data has been compared to trying to reproduce an office building using only the furniture that was inside it.
The Power of Network Effects: The primary value of a messaging service like WhatsApp or a social network like LinkedIn is not the user's individual data but the network of other people who also use that service. This network cannot be "ported". A user could move all their messages to a new app, but if their contacts are not there, the new app is useless. This collective action problem creates a massive and persistent barrier to switching that data portability, in its current form, is ill-equipped to solve.
7.2 Academic and Practical Critiques: The Limitations of an Individual-Centric Right
Beyond its mixed results on competition, the Right to Data Portability has faced trenchant academic and practical criticism for its fundamental design as an individual-centric right tasked with solving systemic problems.
A primary critique is that the right places an unrealistic and excessive onus on the individual. In a world where a single person's data is processed by hundreds, if not thousands, of organizations, the idea that individuals can meaningfully manage their privacy by exercising their rights on a case-by-case basis is impractical. Individuals generally lack the time, the technical expertise, and the scale to make this an effective form of regulation. The power imbalance between a single consumer and a large technology corporation is immense; attempting to correct it with individual rights has been described as "arming an individual with a dagger to fight an entire army".
A second major limitation arises from the problem of interrelated personal data. Much of the data held by platforms is not purely individual but social and interconnected. A photo album contains pictures of friends and family. A contact list contains the personal information of others. A genetic dataset shared with a research platform reveals information not just about the individual, but about their blood relatives. When one person exercises their right to port this data, it has direct privacy implications for other people, creating a conflict of rights that the GDPR does not clearly resolve.
Finally, as previously noted, the exclusion of inferred and derived data from the right's scope is a critical flaw. This is often the most valuable data from a competitive standpoint, representing the proprietary insights and intellectual property of the platform. By leaving this data behind, the user is only ever able to transfer the raw ingredients, not the finished product, which severely limits the ability of a rival service to compete on a level playing field.
7.3 The Chicken-and-Egg Problem: The Lack of Receiving Services and User Apathy
Perhaps the most significant practical failure of the Right to Data Portability is the stark reality of the market: there are very few viable services ready and willing to receive ported data. A study of Facebook's data transfer tool, for example, found that it allowed users to send their data directly to a handful of cloud storage services like Google Drive or Dropbox, but not to any competing social media platforms. This creates a classic "chicken-and-egg problem" that stifles the entire portability ecosystem.
This vicious cycle works as follows: without compelling new services to migrate to, users have little reason or incentive to go through the process of exercising their portability rights. And without a critical mass of users bringing their data with them, new startups and challenger services cannot gain the traction, network effects, or data inputs needed to effectively compete with entrenched incumbents. This market failure is compounded by empirical evidence suggesting that many organizations handle portability requests poorly, with significant delays, incomplete data transfers, or a complete lack of response, which further discourages users from even trying.
The limitations of the GDPR's RtDP have not gone unnoticed by policymakers. The right's failure to organically generate the desired competitive outcomes has led directly to the creation of new, more forceful regulatory instruments. This reveals a pattern of regulatory evolution, where the insufficiency of the initial tool has prompted the development of more prescriptive and targeted mandates. The EU's Digital Markets Act (DMA), for instance, imposes specific and stringent data portability and, crucially, interoperability obligations directly on designated "gatekeeper" platforms. Similarly, the EU's Data Act aims to broaden the scope of portability for data generated by IoT devices, explicitly including "passively observed" data and applying the right to non-personal data as well. This legislative progression demonstrates a clear causal link: the perceived shortcomings of the GDPR's principle-based RtDP created a policy vacuum that these newer, more interventionist regulations are designed to fill. Data portability is therefore not a static concept but an evolving regulatory battleground, shifting from a general right toward more aggressive, market-shaping mandates.
Section 8: The Next Frontier: Portability in the Age of AI and IoT
8.1 The Data Deluge: Portability Challenges and Opportunities in IoT and Smart Ecosystems
The proliferation of the Internet of Things (IoT) is set to create a data explosion of unprecedented scale. By 2025, it is estimated that there will be over 27 billion interconnected devices, from smart home appliances and wearable sensors to industrial machinery and smart city infrastructure. This "data deluge" presents both immense challenges and profound opportunities for data portability.
The primary challenge is one of sheer complexity and scale. The volume, velocity, and variety of data generated by IoT ecosystems are enormous. Achieving interoperability in a smart home, for example, which may contain dozens of devices from different manufacturers using different communication protocols, is a significant technical hurdle. Ensuring the security of these countless data streams is a paramount concern, as each connected device represents a potential vulnerability.
The opportunities, however, are equally vast. Effective data portability in an IoT context could empower users in transformative ways. Imagine being able to switch your entire smart home ecosystem from one controlling platform (e.g., Amazon Alexa) to another (e.g., Google Home) with a single click, taking all your devices, routines, and historical data with you. Users could also aggregate data from various sources—their smart thermostat, their connected car, their fitness tracker—and feed it into a centralized personal AI for holistic lifestyle analysis and optimization. Industry initiatives like the Matter protocol, which aims to create a unified, IP-based connectivity standard for smart home devices, are a crucial step toward solving the foundational interoperability problem and making such scenarios possible.
8.2 AI-Driven Portability: Enhancing, Automating, and Complicating Data Transfers
Artificial Intelligence (AI) and data portability have a deeply symbiotic relationship. Each technology has the potential to both enable and complicate the other.
On one hand, AI can enhance and automate the process of data portability. AI and machine learning algorithms can be deployed to tackle the data harmonization problem, automatically mapping and transforming data from disparate sources into a common, usable format. AI-driven systems can manage the complex, real-time data flows required for direct, continuous portability between services, optimizing resource allocation and ensuring data integrity.
On the other hand, data portability is a critical fuel for AI innovation. The ability for users to aggregate their own data from multiple silos—combining their financial data from open banking, their health data from wearables, and their social data from online platforms—is what will power the next generation of truly personalized AI applications. Without portability, these AI services would be limited to the data held within a single company's walled garden.
However, the rise of AI also introduces new complications for the concept of portability. The most valuable output of many AI systems is not raw data but inferred knowledge—the "learnings" that a model has developed about a user's preferences, behaviors, and likely future actions. This brings the issue of "inferred vs. provided" data to the forefront in a much more complex form. How does one "port" the personalized state of a trained neural network? This question pushes the boundaries of the current legal framework and will be a central challenge for future regulation.
8.3 The Human-Centric Paradigm: Towards Decentralized Data Ecosystems
The limitations of the current platform-centric data model, combined with the possibilities unlocked by new technologies, are driving a future vision for data governance that is more "human-centric". This paradigm shift reframes personal data not as a corporate asset to be controlled by service providers, but as a fundamental component of an individual's digital identity that should be under their own control.
In this model, individuals would aggregate their data in secure, personal data stores or "pods," granting services permission to access specific data for specific purposes, rather than handing over control of the data itself. This approach would give individuals true ownership and control, allowing them to build their own AI-powered applications on top of their personal data ecosystem.
Emerging technologies could provide the technical backbone for such a system. Blockchain and other distributed ledger technologies, for example, could be used to create immutable, transparent, and secure logs of data access and transfer, enhancing trust and accountability within a decentralized data-sharing ecosystem. While still largely conceptual, this human-centric vision represents the ultimate endpoint of the journey that began with the Right to Data Portability: a digital world where data flows are directed not by platforms, but by the individuals themselves.
Section 9: Strategic Recommendations and Conclusion
9.1 For Policymakers: Strengthening Frameworks and Fostering Interoperability
The experience with the GDPR's Right to Data Portability offers clear lessons for policymakers seeking to empower individuals and foster competitive data economies. The primary recommendation is to recognize the limitations of a purely individual-centric right and move towards more direct regulatory interventions that foster a functional ecosystem.
First, policymakers should continue the trend seen in the DMA and Data Act by mandating technical standards and true interoperability in key digital markets, particularly those dominated by gatekeeper platforms. This involves moving beyond general principles to define specific requirements for open APIs and common data formats.
Second, regulators must play a more active role in solving the "chicken-and-egg problem." This can be achieved by encouraging and certifying industry-led development of common standards and codes of conduct. Public-private partnerships can help define the rules of engagement and build trust between data holders and data recipients.
Finally, governments should fund and support common infrastructure projects like the Data Transfer Project. Building the neutral, open-source "plumbing" for the data economy is a public good that will lower the barrier to entry for all players and provide the foundation upon which a vibrant and competitive market can be built.
9.2 For Businesses: Moving Beyond Compliance to Strategic Data Enablement
For businesses, the strategic imperative is to shift their perspective on data portability from a compliance burden to a strategic enabler. Viewing portability through a lens of opportunity can unlock significant long-term value.
First, businesses should invest in modern, API-first data architectures. This not only ensures compliance with current and future regulations but also positions the company to be agile in a future where data flows more freely. A flexible architecture allows a business to act as both a secure data source and an innovative data recipient.
Second, organizations should proactively collaborate with industry peers to develop common data standards. While it may seem counterintuitive to help competitors, a lack of interoperability creates friction for the entire market. By working together to build the "rules of the road," businesses can create a more efficient ecosystem for everyone, reducing collective costs and improving the customer experience.
Finally, businesses must explore new business models predicated on receiving and adding value to ported data. Instead of focusing solely on protecting their own data silo, forward-thinking companies should ask how they can use imported data to offer superior, more personalized, and more innovative services that will attract customers in a competitive, open-data environment.
9.3 Concluding Thoughts: The Evolving Role of Data Portability in the Digital Economy
The Right to Data Portability is a landmark legal concept that has fundamentally altered the conversation around data ownership and control. Its introduction in the GDPR was a crucial and necessary first step, establishing the principle that individuals have a right to not only access but also reuse their personal data. However, its practical implementation has revealed the profound challenges of translating a legal right into a functional market reality.
The right's inherent limitations—its narrow scope, its inability to overcome network effects, and its reliance on an overburdened individual—have shown that a legal principle alone is insufficient to restructure entrenched digital markets. The true legacy of the GDPR's RtDP may be the lessons learned from its shortcomings. These lessons have catalyzed a regulatory evolution towards more direct, assertive, and technically-minded interventions like the Digital Markets Act and the Data Act.
The future of data portability lies in this dynamic interplay between individual rights, technical innovation, and market-shaping regulation. As the digital world becomes ever more interconnected through IoT and transformed by AI, the ability to move data securely and meaningfully will only become more critical. The journey that began with Article 20 is far from over; it has simply opened the door to a more complex and vital debate about how to build a digital economy that is not only innovative and competitive, but also fundamentally empowering for the individuals at its core.
FAQ
What is the Right to Data Portability (RtDP) and what are its core objectives?
The Right to Data Portability (RtDP), primarily codified in Article 20 of the EU's General Data Protection Regulation (GDPR), is a significant innovation in data protection law. It was conceived with a dual purpose: firstly, to empower individuals by granting them greater control over their personal data, reinforcing their right to informational self-determination. This aims to enable users to manage their digital identity across various services and move their data freely. Secondly, it seeks to reshape digital markets by dismantling data silos and fostering competition. By lowering switching costs and reducing "vendor lock-in," the RtDP theoretically levels the playing field for smaller businesses and new entrants to compete with established platforms.
What types of data are included and excluded from the scope of data portability under the GDPR?
Under Article 20 of the GDPR, the Right to Data Portability applies to "personal data concerning him or her, which he or she has provided to a controller." This is broadly interpreted to include two categories:
Actively and Knowingly Provided Data: Information consciously given by the user, such as name, email address, or data filled into online forms.
Observed Data: Data generated by the individual's activity while using a service or device, including search history, website usage, location data, or "raw" data from IoT devices like fitness trackers.
Crucially, the right explicitly excludes inferred or derived data. This is data that the controller creates through analysis or algorithmic processing of the provided data, such as a credit score, an advertising user profile, or an algorithmic recommendation. This exclusion is a significant limitation, as inferred data often represents a platform's most valuable asset and competitive advantage.
How does data portability under the GDPR compare to similar provisions in the California Consumer Privacy Act (CCPA/CPRA)?
While both the GDPR and the CCPA (as amended by CPRA) aim to empower consumers, their approaches to data portability differ significantly:
Legal Basis: GDPR is a fundamental rights framework, whereas CCPA focuses on consumer rights and privacy protection.
Scope of Application: GDPR applies broadly to any controller processing EU data, regardless of location or size. CCPA applies specifically to for-profit businesses meeting certain revenue or data processing thresholds in California.
Nature of the Right: GDPR establishes a standalone "Right to Data Portability" with two clear components: the right to receive data and the right to direct controller-to-controller transmission. CCPA's right is more accurately an "enhanced Right to Access," focusing on providing data to the consumer in a portable and usable format, without an explicit right to compel direct transmission between controllers.
Consent Model: GDPR generally operates on an "opt-in" consent model, requiring affirmative consent. CCPA typically uses an "opt-out" model, particularly for the sale or sharing of personal information.
These differences mean a compliance strategy for CCPA would likely fall short of the GDPR's more stringent requirements.
What are the main practical applications and benefits of data portability for consumers?
Data portability offers tangible benefits across various sectors, translating theoretical rights into real-world advantages for consumers:
Financial Services (Open Banking): Consumers can transfer transaction history to fintech apps for budgeting, financial analysis, or finding better deals on loans.
Social Media and Content Platforms: Users can export photos, contacts, and post history for personal backup or migration to new services.
Health and Fitness: Data from wearables (e.g., step counts, heart rate) can be exported and imported into different health platforms, shared with trainers, or provided to healthcare professionals.
Music and Entertainment Streaming: Users can migrate curated playlists and listening history between streaming services.
Telecommunications and Utilities: Consumers can obtain usage data (e.g., energy consumption) to find more competitive tariffs or port preferences to a new mobile carrier for personalised service.
E-commerce: Purchase history and product preferences can be transferred between online marketplaces to receive relevant recommendations on new platforms.
These applications facilitate convenience, enable new services, and provide valuable personal insights.
What are the key technical requirements for implementing data portability, particularly regarding data formats and transfer mechanisms?
Article 20 of the GDPR mandates that portable data be provided in a "structured, commonly used, and machine-readable format."
Structured: Data must be organised deterministically, retaining context and relationships.
Commonly Used: Formats should be open and widely supported (e.g., CSV, JSON, XML) to prevent proprietary formats from hindering reuse.
Machine-Readable: Data must be automatically readable and processable by a computer for seamless transfer and integration.
For direct controller-to-controller transmission, Application Programming Interfaces (APIs) are the most efficient and secure method. Initiatives like the Data Transfer Project (DTP), an open-source collaboration by major tech companies, aim to build common frameworks and tools for secure, direct service-to-service data portability via APIs, eliminating the need for users to download and re-upload data themselves. However, a significant challenge remains in achieving true interoperability due to a lack of universal standards for data structures and semantic meanings across different systems, requiring complex data harmonisation and transformation.
What are the main challenges and criticisms regarding the efficacy of data portability in achieving its pro-competitive goals?
Despite its intentions, the RtDP has faced significant challenges in achieving its pro-competitive goals, leading to mixed results and criticism:
Incomplete Data: Portability often excludes crucial context, inferred data, and the "social graph" (network of connections), making it difficult for users to replicate their experience on a new platform.
Network Effects: The primary value of many digital services lies in the network of other users, which cannot be "ported." This collective action problem creates a massive barrier to switching.
Individual Onus: The right places an unrealistic burden on individuals to understand and exercise their rights across potentially thousands of services, a task many lack the time or technical expertise to perform effectively.
"Chicken-and-Egg Problem": There's a severe lack of compelling receiving services ready and willing to accept ported data. Without attractive destinations, users have little incentive to port their data, and without a critical mass of portable data, new services struggle to emerge and compete.
Market Concentration: Some research even suggests that, under certain conditions, portability regulations could paradoxically lead to less competition or higher market concentration.
These limitations have led to a regulatory evolution towards more prescriptive mandates, such as the EU's Digital Markets Act and Data Act, to force the data-sharing and interoperability outcomes the GDPR's RtDP aimed to encourage.
How does data portability interact with other GDPR data subject rights, such as access and erasure?
The Right to Data Portability exists within a suite of GDPR rights and is distinct from others:
Right of Access (Article 15): This right allows individuals to obtain a copy of all their personal data (including inferred/derived data) to verify its accuracy and understand processing. The format can be a simple "copy" (e.g., PDF). Its purpose is verification.
Right to Data Portability (Article 20): This right applies only to data "provided by" the subject (actively or observed) and is for reuse. It mandates a "structured, commonly used, and machine-readable format" suitable for automated processing. Its purpose is enablement and transfer.
Right to Erasure (Article 17): Also known as the "right to be forgotten," this is a separate right to request the deletion of personal data. Exercising portability does not automatically delete data from the source controller's systems; a separate request under Article 17 is required. This right is also subject to specific conditions and exceptions.
Understanding these distinctions is crucial for both individuals exercising their rights and organisations fulfilling their obligations, as each right carries different scopes, format requirements, and consequences.
What is the future outlook for data portability, particularly in the context of AI and IoT, and what is the concept of a "human-centric" data ecosystem?
The future of data portability will be profoundly shaped by the proliferation of the Internet of Things (IoT) and Artificial Intelligence (AI).
IoT: The immense volume, velocity, and variety of data from billions of interconnected devices present both massive challenges (complexity, security, interoperability between diverse manufacturers) and opportunities. Effective IoT data portability could allow users to seamlessly switch entire smart home ecosystems or aggregate data from various devices for holistic personal analysis.
AI: AI can enhance portability by automating data harmonisation and transformation, managing complex real-time data flows. Conversely, data portability fuels AI innovation by allowing users to aggregate their diverse personal data from multiple silos, powering next-generation personalised AI applications. However, AI also complicates portability, especially concerning how to "port" valuable "inferred knowledge" or the state of a trained AI model, which goes beyond raw data.
These developments are pushing towards a "human-centric" paradigm for data governance. This vision redefines personal data as a fundamental component of an individual's digital identity, not a corporate asset. In this model, individuals would control their data in secure, personal data stores or "pods," granting services permission for specific uses rather than surrendering control. Technologies like blockchain could provide the technical backbone for such decentralised data ecosystems, empowering individuals to truly own and direct their digital information.