Trade-off in Data Privacy and Model Accuracy in ChatGPT
The proliferation of Large Language Models (LLMs) like OpenAI's ChatGPT marks a paradigm shift in artificial intelligence, offering unprecedented capabilities in content generation, data analysis, and human-computer interaction.


The proliferation of Large Language Models (LLMs) like OpenAI's ChatGPT marks a paradigm shift in artificial intelligence, offering unprecedented capabilities in content generation, data analysis, and human-computer interaction. However, this transformative potential is intrinsically linked to a fundamental conflict: the trade-off between model accuracy and data privacy. The very mechanisms that make these models powerful—their training on vast, diverse datasets—are the same mechanisms that create significant privacy risks. This report provides an exhaustive analysis of this trade-off, examining its technical underpinnings, legal and ethical dimensions, and the strategic implications for organizations.
The core of the dilemma lies in a foundational architectural conflict. The design philosophy of LLMs, which relies on ingesting massive, general-purpose datasets to build "foundation models" capable of a wide array of unforeseen tasks, is in direct opposition to established legal privacy principles such as purpose limitation and data minimization, which are cornerstones of regulations like the GDPR. This is not a superficial issue but a deep-seated tension between the engineering goal of maximizing predictive power and the legal mandate of protecting personal information.
This report dissects this conflict by first defining the multi-faceted nature of "accuracy" and "privacy" in the LLM context. Accuracy extends beyond simple factual correctness to include fluency, relevance, and the mitigation of "hallucinations." Privacy, similarly, expands beyond traditional data security to encompass risks of training data memorization, sensitive attribute inference, and the architectural inability to honor data subject rights like the right to erasure.
The analysis then delves into the technical and architectural strategies developed to manage this trade-off. These include statistical methods like Differential Privacy (DP), which provides mathematical guarantees at the cost of model utility; architectural approaches like Federated Learning (FL) and on-premise deployments, which offer data isolation with significant implementation overhead; and data-centric techniques such as anonymization and synthetic data generation, which present their own balance of benefits and limitations. The report finds that no single technology is a panacea. Instead, a layered, defense-in-depth strategy is required.
Furthermore, the report examines the governance and policy landscape, from the provider-side controls offered by companies like OpenAI—which often create a two-tiered system of privacy for enterprise versus consumer users—to the evolving global regulatory environment. The emergence of AI-specific legislation like the EU AI Act signals a critical shift from a focus on data protection to a broader framework of AI risk management, demanding a more holistic and proactive approach to governance from organizations.
The report concludes with strategic recommendations. Organizations must move beyond reactive compliance and establish proactive, multi-disciplinary AI governance frameworks. This involves conducting comprehensive AI Impact Risk Assessments (AIRA), classifying data, managing vendor risk, and adopting a risk-based approach to implementing a layered defense of privacy-enhancing technologies. The future of enterprise AI will likely trend towards smaller, data-efficient, specialized models that offer a more manageable balance of performance and privacy. Ultimately, navigating the privacy-accuracy dilemma is not a purely technical challenge; it is a core strategic imperative that requires a nuanced understanding of technology, law, and ethics to unlock the full potential of AI responsibly.
Section 1: The Twin Pillars of Modern LLMs: Accuracy and Privacy
To comprehend the central trade-off governing the development and deployment of Large Language Models (LLMs), it is essential to first establish a nuanced understanding of its two constituent poles: model accuracy and data privacy. In the context of generative AI, these terms transcend their traditional definitions. "Accuracy" is not a singular metric of correctness but a multi-dimensional measure of a model's utility, quality, and safety. "Privacy" is not merely about preventing data breaches but encompasses a complex web of risks related to data memorization, inference, and the fundamental rights of individuals whose data fuels these systems. This section deconstructs these two pillars, revealing the inherent complexities and tensions that set the stage for their direct conflict.
1.1 The Pursuit of Performance: Defining and Evaluating LLM Accuracy
The performance of an LLM like ChatGPT is not measured by a simple binary of right or wrong. Instead, "accuracy" is a holistic and multifaceted concept that evaluates the overall quality, utility, and reliability of the model's generated output. This evaluation is critical for developers seeking to refine their models and for businesses aiming to deploy them in real-world applications, from customer service chatbots to complex research analysis. The core of this evaluation process involves testing the models against extensive datasets specifically designed to probe the limits of their performance across several key dimensions.
Key Evaluation Metrics
A comprehensive framework for LLM evaluation must consider multiple axes of performance, as a model can excel in one area while failing in another.
Fluency and Coherence: At the most basic level, a model must be able to generate text that is grammatically correct, readable, and logically structured. This is a foundational capability learned from the immense corpora of text processed during training, which allows the model to understand the rules of grammar and the flow of human language.
Relevance: A critical measure of utility is whether the model's output is pertinent to the user's query or prompt. A fluent and factually correct response is useless if it does not address the user's specific need. This is a high-priority metric, especially for consumer-facing applications where user satisfaction is paramount.
Factual Correctness (Mitigating Hallucination): One of the most significant challenges in LLM accuracy is the phenomenon of "hallucination," where a model generates statements that are factually incorrect, nonsensical, or illogical but are presented with seeming confidence. These fabrications can damage an individual's reputation or lead to poor decisions based on false information. Consequently, a key evaluation vector is a model's truthfulness. Benchmarks such as
TruthfulQA are specifically designed to assess a model's ability to avoid generating plausible-sounding falsehoods learned from human text.
Task-Specific Accuracy: For specialized applications, generic fluency is insufficient. Performance is measured using task-specific metrics. For example, the BLEU (Bilingual Evaluation Understudy) score is widely used in machine translation to measure the similarity between a machine-generated translation and one or more high-quality human translations. Similarly, the
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) score is a set of metrics used to evaluate automatic summarization by assessing how much of the content in a reference summary is captured by the model-generated summary.
Stability and Robustness: A reliable model must demonstrate consistent performance across a wide range of inputs, domains, and operational conditions. Evaluation must test for robustness to ensure that small, irrelevant changes in a prompt do not lead to wildly different or degraded outputs.
Utility and User Experience: Ultimately, the real-world value of an LLM is judged by its users. This broader evaluation includes quantitative measures like latency (the end-to-end response time) and qualitative measures like user satisfaction, which can be gauged through direct feedback, engagement metrics, and the model's ability to gracefully handle errors or misunderstandings.
The Foundational Role of Training Data
The remarkable capabilities of LLMs are a direct result of their training process. These models are built on a "transformer" architecture and trained on massive corpora of text, often containing billions of pages scraped from the internet and other sources. Through this process, which involves predicting the next word in a sentence based on the preceding context, the model learns the intricate patterns of grammar, semantics, logic, and conceptual relationships embedded in human language. The sheer volume and diversity of this training data are what enable the model to generate coherent, contextually relevant, and often highly accurate responses across a vast range of topics. The pursuit of higher accuracy, therefore, has historically been synonymous with the pursuit of larger and more comprehensive datasets, a reality that directly sets the stage for a collision with data privacy principles.
1.2 The Mandate for Protection: Data Privacy in the Age of AI
While LLMs strive for maximal accuracy through maximal data ingestion, they operate within a global legal and ethical environment that increasingly mandates the protection of personal data. Data privacy is not merely a question of data security (i.e., protecting data from unauthorized access) but a broader principle concerning the proper and lawful handling of information related to identifiable individuals. The European Union's General Data Protection Regulation (GDPR) has become a de facto global standard, and its core principles present profound and direct challenges to the fundamental architecture and operation of modern LLMs.
Core Data Protection Principles and Their Collision with LLM Architecture
The principles articulated in Article 5 of the GDPR provide a robust framework for understanding the friction points between LLM technology and privacy law.
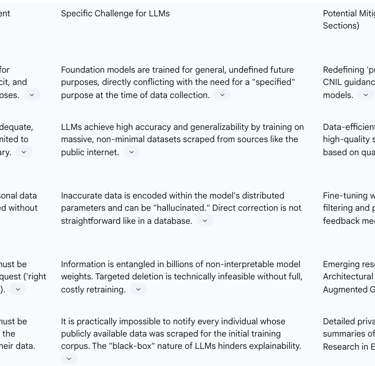
Lawfulness, Fairness, and Transparency: This principle requires that personal data be processed lawfully and that individuals be informed about how their data is collected and used. LLMs challenge this on multiple fronts. First, the "black-box" nature of their neural networks makes it exceedingly difficult to provide a transparent explanation of how a specific piece of data influenced a particular output. Second, when training data is scraped from the public internet, it is often practically impossible to provide notice to every individual whose personal data (e.g., a blog post, a public comment) was ingested, as required by GDPR's Article 14.
Purpose Limitation: This cornerstone principle mandates that data be "collected for specified, explicit, and legitimate purposes" and not be used for incompatible future purposes. This is perhaps the most direct architectural conflict with LLMs. LLMs are a type of "foundation model," defined by their training on broad, general-purpose data to enable a wide variety of
unforeseen and undefined future applications. A model trained for potentially
any purpose cannot, by definition, have a specific purpose determined at the time of data collection. This tension is a central legal and ethical challenge for the entire field.
Data Minimization: This principle requires that data processing be "adequate, relevant and limited to what is necessary" for the specified purpose. The very design philosophy of LLMs runs counter to this. Their performance and generalizability are seen as a function of the massive scale of their training data. The goal is often to ingest a maximalist dataset, not a minimal one, in direct contradiction to the legal principle.
Accuracy: The GDPR grants individuals the right to have inaccurate personal data about them rectified. LLMs, trained on the unfiltered internet, inevitably learn and can reproduce inaccurate information. Worse, they can "hallucinate" entirely new falsehoods about individuals that appear credible. Correcting this is not as simple as editing a database entry; the inaccuracy is encoded within the model's billions of parameters, making targeted rectification a significant technical hurdle.
Storage Limitation and The Right to Erasure (Art. 17): This principle dictates that data should be kept in a form that permits identification of individuals for no longer than is necessary. It is directly linked to the "right to be forgotten," which allows individuals to request the deletion of their personal data. For LLMs, this presents a near-insurmountable technical challenge. Information from the training data is not stored in discrete, retrievable records but is transformed and distributed across the model's vast network of non-interpretable numerical parameters, or "weights". Excising the influence of a single person's data from these interconnected weights without damaging the model's overall integrity and performance is currently technically infeasible at scale and would likely require complete, and prohibitively expensive, retraining of the model from scratch.
This analysis reveals that the conflict between LLM technology and privacy principles is not a matter of fixing minor bugs or closing security loopholes. It is a foundational architectural conflict. The design choices that make LLMs powerful and versatile—their scale, their general-purpose training, and their distributed method of storing knowledge—are the very same choices that place them in direct tension with the legal and ethical frameworks designed to protect individual privacy. An organization cannot simply decide to be "more accurate" and "more private" without confronting the reality that, under the current technological paradigm, these two goals are often in opposition. Addressing this requires a sophisticated understanding of both the technology's capabilities and its inherent legal friction points, as detailed in Table 1.
Table 1: GDPR Provisions and Their Challenges for LLMs

Section 2: The Inherent Conflict: Unpacking the Privacy-Accuracy Trade-off
The relationship between data privacy and model accuracy in Large Language Models is not one of simple coexistence but of inherent tension. Efforts to enhance privacy often directly degrade model performance, and conversely, the pursuit of maximum accuracy frequently amplifies privacy risks. This section unpacks the mechanics of this conflict. It begins by examining how LLMs can leak sensitive data through processes like memorization and regurgitation, driven by their fundamental training objectives. It then analyzes how the very technologies designed to prevent these leaks—such as differential privacy and data anonymization—introduce noise or reduce information content, thereby imposing a direct cost on the model's utility and accuracy.
2.1 The Mechanics of Memorization and Data Leakage
The privacy risks associated with LLMs are not limited to traditional security breaches where an attacker gains unauthorized access to a database. A more insidious risk arises from the model's own internal workings and outputs. Because LLMs are trained on vast datasets scraped from the internet, they inevitably ingest massive amounts of personal, sensitive, and proprietary information. This can include personally identifiable information (PII) like names, email addresses, and phone numbers, as well as confidential business data such as source code or internal financial reports. The model's ability to learn from this data creates multiple vectors for leakage.
Verbatim Memorization and Regurgitation
A primary mechanism of data leakage is the model's capacity to memorize and then reproduce verbatim sequences from its training data. This is not necessarily a flaw in the model's learning process but a direct consequence of its optimization objective. An LLM is trained to predict the next word in a sequence with the highest probability. For text that appears frequently or is highly unique within the training data, the most statistically accurate prediction is to simply reproduce it. Research has consistently shown that this risk of memorization increases with the model's size (number of parameters) and the frequency of a data point's appearance in the training corpus.
This phenomenon has been demonstrated in several documented cases. In one notable experiment, researchers found that prompting ChatGPT to repeat a word like "poem" indefinitely caused it to deviate from its instructions and begin outputting verbatim passages from its training data, including the real names, email addresses, and phone numbers of individuals. Earlier attacks on the GPT-2 model successfully extracted personal addresses and phone numbers that had been memorized from the training set. Beyond research settings, real-world incidents have highlighted this risk, such as when Samsung employees inadvertently leaked sensitive corporate source code by pasting it into ChatGPT for assistance, making that information part of the model's interaction data and risking its inclusion in future training cycles.
Typology of Privacy Attacks
The risk of data leakage is not purely accidental; it can be actively exploited by malicious actors through a variety of attack methods. Understanding this threat landscape is crucial for developing effective defenses.
Prompt Injection and Jailbreaking: In this type of attack, an adversary crafts a malicious prompt designed to trick the LLM into ignoring its safety protocols and revealing sensitive information. This could involve instructing the model to disregard previous instructions and output its underlying system prompt, which might contain confidential configuration details, or to role-play as a system without ethical constraints. This exploits the model's ability to follow instructions, turning its primary function into a vulnerability.
Membership Inference Attacks (MIA): The goal of an MIA is not necessarily to extract the content of a data record but to determine whether a specific individual's data was part of the model's training set. By carefully analyzing a model's outputs and confidence scores in response to certain queries, an attacker can infer membership. In many contexts, such as a model trained on patient data from a specific cancer clinic, simply confirming that a person's data was in the training set constitutes a severe privacy breach.
Attribute Inference: Even if a model does not leak PII verbatim, it can be used to infer sensitive attributes about a person that were not explicitly provided. For example, based on a series of queries about symptoms, a healthcare chatbot could infer a user's likely medical condition. Similarly, an analysis of writing style, topics of interest, and colloquialisms in prompts can allow a model to infer characteristics like a user's age, location, occupation, or political affiliation. This inferential capability turns the model into a powerful, and potentially privacy-invasive, analytical tool.
Model Inversion and Data Extraction: These attacks are more ambitious, aiming to reconstruct portions of the raw training data by repeatedly querying the model and analyzing its outputs. While difficult, successful extraction attacks have been demonstrated, posing a direct threat to the confidentiality of the entire training dataset.
These mechanisms demonstrate that privacy risk in LLMs is multifaceted. It stems from the model's core design, which incentivizes memorization, and is exacerbated by vulnerabilities that can be exploited by determined adversaries. Table 2 provides a structured overview of these attack vectors.
Table 2: Typology of Data Leakage Attacks on LLMs


2.2 The Cost of Privacy: How Privacy-Enhancing Technologies (PETs) Impact Model Utility
In response to the risks of data leakage, a suite of Privacy-Enhancing Technologies (PETs) has been developed. However, these technologies are not a free lunch; they operate by introducing mechanisms that inherently limit, obscure, or partition the information the model can learn from. This creates a direct and often quantifiable trade-off: stronger privacy guarantees typically come at the cost of reduced model accuracy, utility, and performance.
The fundamental nature of this trade-off arises because accuracy is achieved by maximizing the "signal" a model can extract from data, while privacy is achieved by introducing "noise" or uncertainty to obscure the contribution of any individual data point.
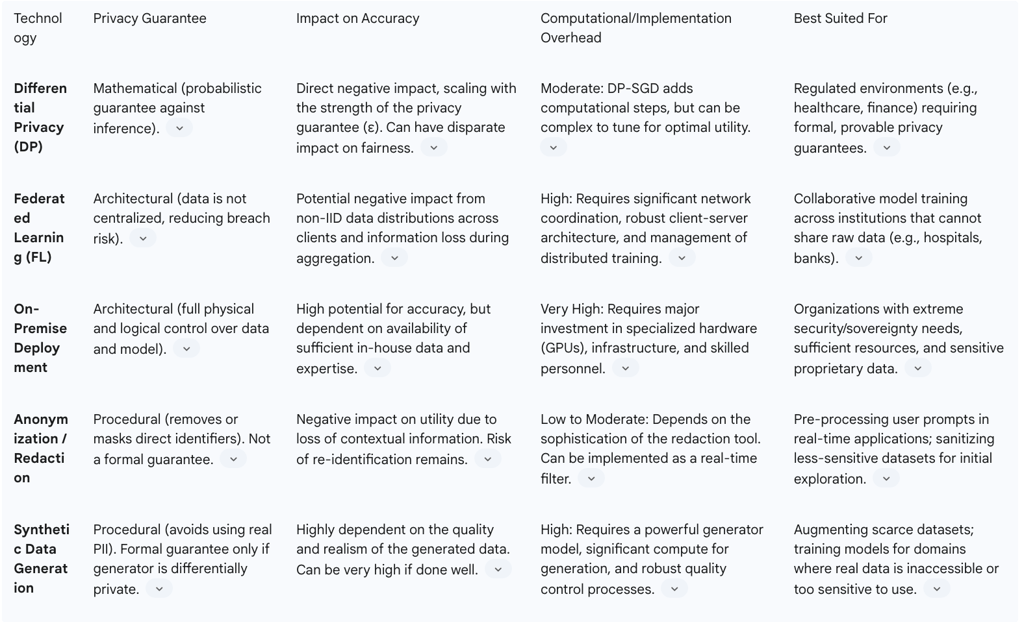
Impact of Differential Privacy (DP): Differential Privacy is considered the gold standard for statistical privacy, providing a formal, mathematical guarantee that the output of a computation is statistically similar whether or not any single individual's data is included in the input dataset. In the context of LLM training, this is typically implemented via an algorithm called Differentially Private Stochastic Gradient Descent (DP-SGD). This process involves two key steps that impact accuracy: 1)
Gradient Clipping, which limits the maximum influence any single data point can have on the model's update, and 2) Noise Injection, which adds carefully calibrated random noise to these clipped gradients. While this process effectively masks individual contributions, it also systematically degrades the quality of the information the model uses to learn. The introduced noise can obscure subtle but important patterns in the data, leading to a model that is less accurate and converges more slowly. The strength of the privacy guarantee is controlled by a parameter, epsilon (
ε). A lower epsilon signifies stronger privacy, but requires more noise to be added, resulting in a greater hit to model utility.
Impact of Federated Learning (FL): Federated Learning is an architectural approach to privacy where a model is trained across many decentralized devices or servers without the raw data ever leaving those locations. This inherently enhances privacy by preventing data centralization. However, it can reduce accuracy for several reasons. The central "global" model never sees the complete, raw dataset and must learn from aggregated, and potentially noisy, updates from the clients. If the data across these clients is not identically and independently distributed (a common scenario known as non-IID), the aggregated updates may pull the global model in conflicting directions, hindering convergence and reducing overall accuracy.
Impact of Data Anonymization and Redaction: A seemingly straightforward approach to privacy is to scrub training data of all PII before training. Techniques can range from simple redaction (replacing a name with ``) to more sophisticated anonymization or pseudonymization. However, this process is fraught with challenges. Firstly, it is difficult to do perfectly; quasi-identifiers can remain, allowing for potential re-identification. Secondly, and more critically for the trade-off, this scrubbing process can significantly reduce the utility of the data. The information that is removed—such as names, locations, or specific dates—often provides crucial context that helps the model learn complex relationships and patterns. For example, in a medical dataset, understanding the relationship between a patient, a hospital, and a treatment might be lost if all identifiers are removed. Overly aggressive data scrubbing can lead to a less informed and therefore less accurate model.
This trade-off is not only a matter of overall performance but also has critical implications for fairness. The accuracy penalty from PETs is not distributed evenly across all data subgroups. Research has demonstrated a "disparate impact," where the application of techniques like DP disproportionately harms the model's performance on data from underrepresented minorities or more complex, harder-to-learn examples. The mechanisms of gradient clipping and noise addition have a greater effect on the larger, more distinct signals produced by these subgroups during training. The result is that the "poor get poorer": the model's accuracy drops more significantly for the very groups that were already at a disadvantage. This transforms the issue from a simple two-way trade-off between privacy and accuracy into a more complex, three-way dilemma involving privacy, accuracy, and fairness. Organizations must therefore recognize that implementing privacy controls is not merely a technical adjustment but an ethical decision with the potential to amplify existing societal biases.
Section 3: Technical and Architectural Mitigation Strategies
Navigating the complex trade-off between privacy and accuracy requires a sophisticated toolkit of technical and architectural solutions. These strategies are not mutually exclusive; rather, they represent different layers of a comprehensive defense-in-depth approach to responsible AI deployment. This section provides a detailed analysis of the three primary categories of mitigation: statistical privacy methods like Differential Privacy, structural approaches such as Federated Learning and on-premise deployments, and data-centric techniques including anonymization and the use of synthetic data. For each, the analysis examines the practical implementation, empirical effectiveness, and inherent limitations.
3.1 Statistical Privacy: The Promise and Peril of Differential Privacy (DP)
Differential Privacy (DP) stands out as a powerful tool for LLM privacy because it offers a formal, mathematical guarantee of protection. Instead of relying on ad-hoc measures, DP provides a provable bound on how much the output of a model can be influenced by any single individual's data in the training set.
Implementation and Empirical Impact
In the context of training LLMs, DP is most commonly implemented through an algorithm called Differentially Private Stochastic Gradient Descent (DP-SGD). During each step of the training process, the algorithm calculates the updates (gradients) for the model's parameters, clips these gradients to a certain maximum size to limit the influence of any single data point, and then adds a carefully calibrated amount of random (typically Gaussian) noise before applying the update.
Empirical studies consistently demonstrate the core trade-off of this approach. The application of DP substantially reduces privacy risks, making it much harder for attacks like membership inference or data extraction to succeed, even when using a relatively high (less private) privacy budget, denoted by the parameter epsilon (ε). However, this privacy gain comes at a direct cost to model utility. The injected noise degrades the training signal, leading to a reduction in model accuracy. The extent of this utility degradation is not uniform; it varies significantly depending on the fine-tuning method employed. Research shows that full model fine-tuning and parameter-efficient methods like LoRA tend to be more robust to the effects of DP, maintaining a better balance of privacy and utility. In contrast, other methods like prefix-tuning suffer from severe performance degradation, making them unsuitable for deployment in privacy-sensitive applications requiring DP.
The Disparate Impact and the User-Level Challenge
A critical and often overlooked consequence of DP is its disparate impact on fairness. The accuracy penalty is not borne equally across all subgroups within the data. Because data from underrepresented groups or examples that are more complex to learn often generate larger, more distinct gradients, the process of clipping and adding noise disproportionately affects them. This can amplify existing biases in the dataset, leading to a model that is significantly less accurate for minority subgroups than for the majority. This creates a challenging three-way trade-off between privacy, overall utility, and fairness that organizations must carefully navigate.
Furthermore, a crucial distinction exists between example-level DP and user-level DP. Example-level DP protects a single data record (e.g., one sentence), while user-level DP protects all data contributed by a single user. User-level DP provides a much stronger and more realistic privacy guarantee, as it aligns with how data is actually owned. However, achieving it requires adding significantly more noise to the training process, which poses a greater challenge to model accuracy. A significant area of ongoing research is focused on developing more efficient algorithms that can provide robust user-level DP guarantees with a minimized impact on utility, making this stronger form of privacy more feasible for large-scale LLM fine-tuning.
3.2 Structural Privacy: Federated Learning and Decentralized Architectures
Beyond adding statistical noise, privacy can be enhanced through architectural choices that fundamentally alter how and where data is processed. These structural approaches focus on data isolation and decentralization.
Federated Learning (FL) for LLMs
Federated Learning is a training paradigm that directly addresses the privacy risks of data centralization. In an FL setup, a global model is trained collaboratively across numerous decentralized clients (e.g., different hospitals, individual mobile devices) without the raw data ever leaving those clients' control. Instead, clients receive the current global model, perform local training on their private data, and then send only the resulting model updates (e.g., gradients or weights) back to a central server for aggregation. This architecture is particularly well-suited for fine-tuning LLMs on sensitive, distributed datasets, such as in healthcare or finance.
However, FL is not a complete privacy solution on its own. The model updates, while not raw data, can still leak information about the training data to a malicious server or other participants. Therefore, the most robust implementations of FL are those that combine the architectural privacy of decentralization with the statistical privacy of DP. In such a system, clients add differential privacy noise to their local model updates before transmitting them, providing a multi-layered defense.
Private, On-Premise Models and PEFT
For organizations with the highest security requirements and sufficient resources, the ultimate structural solution is to deploy LLMs entirely on-premise. By hosting models on their own infrastructure, companies maintain complete control over their data, eliminating the risks associated with sending sensitive information to third-party API providers. This approach, however, demands significant capital investment in specialized hardware like GPUs and the in-house expertise to manage complex AI systems.
A more accessible and efficient architectural approach involves Parameter-Efficient Fine-Tuning (PEFT) techniques, such as LoRA (Low-Rank Adaptation). Instead of fine-tuning all of the billions of parameters in an LLM, LoRA involves training only a small, low-rank "adapter" matrix that is added to the model. This dramatically reduces the computational cost of fine-tuning. From a privacy perspective, this approach can be combined with data isolation. For example, a service provider can maintain a single, customer-agnostic base model and load small, customer-specific LoRA adapters at runtime for each user request. This ensures a strong logical and physical separation of customer data, preventing the kind of cross-customer data leakage that can occur when a shared model is continuously trained on all user data.
3.3 Data-Centric Privacy: Anonymization, Redaction, and Synthetic Data
The final category of mitigation strategies focuses not on the model's algorithm or architecture, but on the data itself. These data-centric approaches aim to remove or replace sensitive information before it ever reaches the model.
Data Redaction and Anonymization
Data redaction involves identifying and masking or removing PII from text, either before it is used for training or in real-time as part of a user's prompt. Modern tools can use a combination of rule-based methods (regex) and machine learning models to detect a wide range of sensitive entities.
While this is an essential first line of defense, its effectiveness is limited. First, perfect anonymization is notoriously difficult. Even if direct identifiers (like names and social security numbers) are removed, an individual can often be re-identified by linking the remaining quasi-identifiers (like age, zip code, and occupation) with other publicly available data. Sophisticated LLMs are particularly adept at making these connections. Second, the process of anonymization can degrade data utility. Removing information, especially in a way that disrupts the context of the text, can make the data less valuable for training, leading to a less accurate model. Studies have shown that even with state-of-the-art anonymization tools, a significant risk of re-identification through inference can remain.
Synthetic Data Generation
A highly promising data-centric approach is the use of synthetic data. Instead of training a model on real, sensitive data, an organization can use a powerful generator model (often another LLM) to create a large, artificial dataset that mimics the statistical properties and patterns of the real data but contains no actual PII.
The privacy benefits are significant: this approach allows models to be trained on realistic data without the inherent risk of memorizing and leaking real individuals' information. It is particularly valuable in domains where real data is scarce or too sensitive to use directly, such as in healthcare or finance. However, this technique also has trade-offs. The utility of the final model is entirely dependent on the quality of the synthetic data. If the generated data is of low quality, contains factual inaccuracies, or amplifies biases from the generator model, the resulting trained model will inherit these flaws. Furthermore, it is crucial to understand that synthetic data alone does not provide a formal privacy guarantee like DP. If the generator model was trained on sensitive data, it could still leak information into the synthetic data it creates. For a rigorous privacy guarantee, the synthetic data itself must be generated by a model that was trained with differential privacy.
Ultimately, no single technology offers a complete solution. The most effective strategies will employ a layered, defense-in-depth approach. For instance, a highly secure application might be built on a private, on-premise model (architectural) that is fine-tuned using a synthetically generated dataset (data-centric) that was itself created by a differentially private generator model (statistical). This combination of controls provides multiple, compounding barriers to privacy breaches. This layered approach is reflected in the comparative analysis in Table 3.
Furthermore, a synergistic relationship is emerging between the drive for privacy and the economic push for more efficient AI. The immense cost of training ever-larger models is creating a strong incentive to develop data-efficient techniques that can achieve high performance with smaller, higher-quality datasets. Methods that focus on intelligently selecting data based on quality and diversity, rather than simply ingesting more data, can simultaneously reduce computational costs and shrink the privacy attack surface. This suggests a future where the goals of economic efficiency and privacy are not entirely at odds, but can be pursued in tandem by shifting focus from raw scale to curated quality.
Table 3: Comparison of Privacy-Enhancing Technologies (PETs)
Section 4: Governance, Policy, and User Agency
While technical and architectural solutions form the bedrock of privacy protection, they are insufficient on their own. A robust strategy for managing the privacy-accuracy trade-off must be situated within a comprehensive framework of governance, policy, and a clear understanding of user rights. This section examines the controls and policies implemented by major LLM providers like OpenAI, analyzes the rapidly evolving regulatory landscape that is shaping the future of AI, and delves into the unresolved ethical and legal questions surrounding the use of public data and the ownership of AI-generated content.
4.1 Provider-Side Controls: OpenAI's Approach to Enterprise and Consumer Privacy
Leading LLM providers like OpenAI have responded to market and regulatory pressures by developing a multi-tiered approach to data privacy, creating a significant distinction between their services for individual consumers and those for enterprise clients. This differentiation has become a cornerstone of their business model and a critical factor in organizational risk assessment.
Differentiated Service Tiers and Data Usage Policies
A fundamental strategy employed by OpenAI is the separation of its consumer-facing products from its business-oriented platforms. This separation comes with starkly different default data handling policies:
Consumer Services (e.g., ChatGPT Free, Plus, Pro): For these services, the default policy is that user conversations and other content may be used to train and improve OpenAI's models. This means that unless a user actively changes their settings, their interactions are contributing to the ongoing development of the underlying AI. In this model, user data is, in effect, part of the payment for the service.
Business Services (e.g., API Platform, ChatGPT Team, ChatGPT Enterprise): In stark contrast, for these enterprise-grade services, OpenAI's policy is that customer data is not used to train their models by default. This is a crucial contractual assurance that allows businesses to use the powerful models without the risk of their proprietary or confidential information being absorbed into a general-purpose AI that could be accessed by others, including competitors.
This two-tiered system is a classic "freemium" business model applied to data privacy. It creates a clear value proposition for enterprises: pay for a premium service to gain control and ensure the privacy of your data. For organizations, this has a critical implication: the use of free, consumer-grade AI tools for any task involving sensitive, confidential, or proprietary information constitutes a significant and explicit data governance risk. The choice of service tier has become a primary security and policy decision.
User Controls, Data Retention, and Security
To provide users with agency, OpenAI has implemented several data control features. Within the account settings, a "Data Controls" section allows individual users of consumer services to explicitly opt-out of having their conversations used for model training. While this does not retroactively remove data already used, it prevents future conversations from being included in training sets. Additionally, OpenAI offers a "Temporary Chat" feature, which creates conversations that are not saved to the user's history and are not used for training.
For its enterprise clients, OpenAI offers more robust controls, including configurable data retention policies. Qualifying organizations can dictate how long their business data is retained, with some having the option for zero data retention on the API platform. To meet growing compliance demands, OpenAI also provides data residency options, allowing businesses to store their data at rest in specific geographic regions like the U.S. or Europe to comply with data sovereignty requirements. These features are backed by stated security measures, such as AES-256 encryption for data at rest and TLS 1.2+ for data in transit.
The Gap Between Policy and Reality
Despite these policies and controls, the real-world implementation of complex systems is never flawless. Vulnerabilities can and do lead to privacy incidents. In March 2023, OpenAI disclosed a bug in an open-source library that caused an outage and, for a small number of users, the unintended visibility of other users' chat history titles and payment-related information. While the issue was patched, the incident serves as a stark reminder that even with strong contractual policies, implementation errors and software vulnerabilities can still lead to data breaches. This underscores the need for organizations to conduct thorough due diligence and not rely solely on a provider's terms of service.
4.2 The Regulatory Horizon: Navigating the Evolving Legal Landscape
The legal framework governing AI is in a state of rapid evolution. While existing data protection laws like the GDPR provide a foundation, their application to the unique challenges of LLMs is complex and often contested. In response, governments worldwide are developing new, AI-specific legislation that will profoundly shape the future of the industry.
A discernible trend in this new wave of regulation is a conceptual shift away from focusing solely on the protection of input data and towards a broader framework of managing the risks of the AI system itself. Compliance is no longer just about having a lawful basis to process personal data; it is increasingly about assessing, mitigating, and being transparent about the potential harms of the AI application's outputs and decisions.
Emerging AI-Specific Legislation
The EU AI Act: Expected to set a global benchmark, the EU AI Act is the world's first comprehensive legal framework for AI. It adopts a risk-based approach, categorizing AI systems into tiers of risk (unacceptable, high, limited, minimal). Systems deemed "high-risk"—such as those used in employment, credit scoring, or critical infrastructure—will be subject to stringent requirements, including mandatory risk assessments, high levels of accuracy, robust data governance, transparency, and human oversight. General-purpose AI models like ChatGPT will also face specific compliance obligations, including technical documentation and transparency about training data.
U.S. State Laws (Colorado and California): In the absence of comprehensive federal AI legislation in the United States, individual states are taking the lead. The Colorado AI Act, set to take effect in 2026, also targets "high-risk AI systems" and imposes distinct duties on both the "developers" and "deployers" of these systems. Deployers will be required to conduct risk management and impact assessments and to provide consumers with rights to notice, explanation, and correction regarding consequential automated decisions. Similarly, California is advancing regulations that will mandate greater transparency regarding the data used to train generative AI systems and will regulate the use of automated decision-making technology under its existing privacy framework.
Predictions for 2025 and Beyond
The clear trajectory is towards stricter and more specific regulation of AI. Key themes that will dominate the compliance landscape include:
Transparency Mandates: Regulators will increasingly require developers to disclose details about their training data, including high-level summaries of datasets and whether they contain copyrighted or personal information.
Risk Management Frameworks: Conducting and documenting AI Impact Risk Assessments (AIRAs) will shift from a best practice to a legal requirement in many jurisdictions.
Human Oversight: For high-stakes applications, regulations will mandate meaningful human oversight to prevent and correct errors or biases in AI-driven decisions.
Regulatory Fragmentation: It is unlikely that a single, unified global AI regulatory framework will emerge in the near term. Businesses operating internationally will need to navigate a complex patchwork of laws in different regions, requiring agile and adaptable governance models.
This evolution means that AI compliance can no longer be the sole responsibility of a data protection officer. It demands the creation of multi-disciplinary AI governance committees that can assess the holistic risks of an AI application—including bias, fairness, and safety—not just the privacy of its underlying data.
4.3 The Ethics of Ingestion: Debating the Use of Public Data and Data Ownership
Underpinning the entire LLM ecosystem is a contentious legal and ethical question: is it permissible to use the vast trove of publicly available information on the internet to train commercial AI models? While developers have largely operated under this assumption, it is being challenged on grounds of both consent and copyright.
The "Publicly Available" Data Dilemma
Most foundation models are trained on datasets like Common Crawl, which are massive archives of the public web. This practice is facing increasing scrutiny.
Consent and Privacy Expectations: From a legal perspective, particularly under GDPR, the fact that data is "publicly available" does not automatically grant a license for any and all processing. An entity processing personal data—even data a person posted on their own blog—may still need to establish a lawful basis, such as legitimate interest, and fulfill transparency requirements. Ethically, there is a disconnect between a user's expectation when they post content online and its subsequent use in training a multi-billion dollar commercial product. Most users do not reasonably expect their product reviews or social media comments to become fuel for a corporate AI.
Copyright and Intellectual Property: A more direct legal challenge comes from copyright law. The use of copyrighted books, articles, and images in training datasets without permission or compensation has led to high-profile lawsuits, most notably The New York Times Co. v. Microsoft Corp. and OpenAI, Inc.. The outcome of these cases will have profound implications for the future of AI development and the definition of "fair use" in the digital age.
The Unresolved Question of Ownership
The use of LLMs creates a cascade of unresolved ownership questions that are a legal minefield for businesses.
Ownership of Inputs, Outputs, and Insights: While a business generally retains ownership of its own proprietary data that it inputs into a model, the ownership of the output is far less clear. If a user provides a creative prompt to generate an image, who owns the copyright to that image: the user, the AI provider, or neither? If an LLM analyzes a company's sales data and generates a novel market insight, does that insight belong exclusively to the company, or does the AI provider have some claim, given its model created it?.
Ownership of Model Improvements: If a company uses its unique, high-quality data to fine-tune a general-purpose model, thereby improving its capabilities, does that company have any ownership stake in the improved model? Should it be compensated if that improvement benefits other users? These are complex questions of intellectual property that are currently being negotiated in custom enterprise licensing agreements but lack clear legal precedent.
Navigating this terrain requires robust data governance, clear contractual agreements with AI providers, and a keen awareness of the evolving legal landscape.
Section 5: Strategic Recommendations and Future Outlook
The intricate and persistent trade-off between privacy and accuracy in Large Language Models is not a problem to be "solved" but a complex risk to be managed. For organizations seeking to harness the power of AI, success will depend on moving beyond ad-hoc adoption and implementing a deliberate, strategic, and proactive governance framework. This final section synthesizes the report's findings into actionable recommendations for businesses and provides a forward-looking perspective on how this fundamental trade-off is likely to evolve with future research and technological advancements.
5.1 A Framework for Risk-Based Implementation
A reactive, compliance-only approach to AI is insufficient and unsustainable given the rapid pace of technological change and the fragmented, lagging nature of regulation. Organizations must instead adopt a proactive, risk-based posture. The following steps provide a framework for responsible implementation.
Conduct AI Impact Risk Assessments (AIRA): Before deploying any LLM-powered system, especially for high-stakes use cases, organizations must conduct a comprehensive risk assessment. As mandated by emerging laws like the Colorado AI Act, this assessment must go beyond traditional data privacy concerns to evaluate the full spectrum of AI risks, including the potential for algorithmic bias, the generation of inaccurate or harmful "hallucinations," security vulnerabilities like prompt injection, and the potential for misuse. This process should document the model's intended purpose, the data used, and the potential impact on individuals.
Establish an AI Governance Committee: Effective AI governance cannot be siloed within a single department. It requires the creation of a multi-stakeholder committee comprising representatives from Legal, IT, Cybersecurity, Human Resources, relevant business units, and ethics and compliance teams. This body is responsible for setting enterprise-wide AI usage policies, reviewing and approving new use cases, overseeing risk assessments, and ensuring alignment with both legal obligations and the organization's ethical principles.
Implement a Layered Defense Strategy: As established in Section 3, there is no single technical solution to the privacy-accuracy dilemma. The most robust approach is a defense-in-depth strategy that combines multiple layers of controls based on the sensitivity of the data and the risk of the application. For example, highly sensitive financial analysis might be performed using a specialized, on-premise model (architectural control) that processes only synthetically generated data (data-centric control), with strict input and output redaction filters (technical control).
Data Mapping and Classification: An organization cannot protect what it does not understand. A foundational step in AI governance is to conduct thorough data mapping to identify all workflows where data is being sent to or processed by LLMs. This data must then be classified according to its sensitivity (e.g., public, internal, confidential, PII, PHI). This classification scheme is the basis for applying appropriate, risk-tiered security and privacy controls.
Scrupulous Vendor Risk Management: When using third-party AI providers, organizations must perform rigorous due diligence that goes beyond marketing claims. It is critical to scrutinize contracts, terms of service, and technical documentation to fully understand the vendor's data handling practices. Key questions to answer include: Is business data used for model training by default? What are the data retention and deletion policies? Where is data stored and processed (data residency)? What security certifications (e.g., SOC 2) do they hold?. Relying on a vendor's default settings without this level of scrutiny is a significant governance failure.
5.2 The Future of Research: Towards Data-Efficient and Inherently Private Models
The privacy-accuracy trade-off is a moving target. Ongoing research is actively seeking to shift its boundaries, driven by both the need for privacy and the immense economic pressure to make LLMs more efficient. The future outlook suggests a move away from a monolithic "bigger is better" paradigm towards more specialized, efficient, and inherently private models.
The Rise of Data-Efficient Learning: The computational and financial cost of training massive LLMs is a major bottleneck. This has spurred a wave of research into data-efficient learning techniques. Instead of relying on sheer data volume, these methods focus on improving data quality. Techniques like
Ask-LLM, which uses an LLM to assess the quality of training examples, and Density sampling, which selects data to maximize diversity and coverage, have shown that models can achieve superior performance while being trained on a fraction of the data. This trend is highly beneficial for privacy; smaller, higher-quality training sets inherently reduce the attack surface for memorization and membership inference.
A Shift to Sparse and Specialized Models: The future of enterprise AI may not be a single, giant, general-purpose model, but rather an ecosystem of smaller, "sparse expert" models that are fine-tuned for specific domains and tasks. A model specialized for legal contract analysis or medical diagnostics, trained on a curated, high-quality dataset for that domain, can often outperform a general-purpose model while presenting a much more manageable privacy and security risk profile. This shift from raw scale to efficient specialization will be a key strategic differentiator for businesses.
Privacy-by-Design Architectures: While current PETs often "bolt on" privacy to existing architectures, future research aims to build models that are private by design. This includes several promising avenues:
Machine Unlearning: Active research is focused on developing effective and efficient algorithms for "machine unlearning," which would allow for the targeted and provable removal of specific data points' influence from a trained model. This would be a technical breakthrough, providing a path to truly honoring the "right to be forgotten".
Explainable AI (XAI): A major privacy challenge is the "black-box" nature of LLMs. XAI research aims to develop techniques that can provide meaningful explanations for a model's outputs, bringing transparency to its internal decision-making processes and making it easier to audit for bias or privacy violations.
Concluding Outlook
The fundamental tension between a model's need to learn from data and the imperative to protect that same data is likely to remain a central challenge in the field of artificial intelligence for the foreseeable future. The privacy-accuracy trade-off is not a temporary problem but an inherent characteristic of the current generation of data-driven models.
However, the parameters of this trade-off are not static. The convergence of economic pressures for efficiency and regulatory demands for privacy is driving innovation in a positive direction. The move towards smaller, specialized models trained on high-quality, curated, and potentially synthetic data offers a promising path to mitigating the worst aspects of this trade-off.
For organizations, the path forward is clear. A strategy of "hope for the best" or waiting for perfect technical solutions is untenable. The only viable approach is to embrace proactive governance. By building robust internal frameworks, conducting diligent risk assessments, and making deliberate, risk-informed choices about which models and data to use for which tasks, businesses can navigate the complexities of the current landscape. They can unlock the immense productivity and innovation promised by LLMs while upholding their legal and ethical responsibilities to protect data and build trust in an increasingly AI-powered world.
FAQ
1. What is the core conflict or "dilemma" at the heart of Large Language Models (LLMs)?
The core conflict in Large Language Models (LLMs) is the fundamental trade-off between model accuracy and data privacy. LLMs achieve their impressive capabilities by training on vast, diverse datasets, which maximises their predictive power and general applicability. However, this extensive data ingestion inherently creates significant privacy risks, as it clashes with established legal privacy principles such as purpose limitation, data minimisation, and the right to erasure, which are cornerstones of regulations like the GDPR. Essentially, the architectural design that makes LLMs powerful – their reliance on massive, general-purpose datasets – is in direct opposition to the legal and ethical mandate to protect personal information. An organisation cannot simultaneously achieve maximum accuracy and maximum privacy with current LLM technology; there is an intrinsic tension where enhancing one often degrades the other.
2. How is "accuracy" defined for LLMs, and what are the main privacy risks associated with their operation?
"Accuracy" in LLMs is a multifaceted concept that extends beyond simple factual correctness. It encompasses fluency and coherence (grammatical correctness and logical structure), relevance (pertinence to the user's query), factual correctness (mitigating "hallucinations" or fabricated information), task-specific accuracy (performance on specialised tasks like translation or summarisation), stability and robustness (consistent performance across varied inputs), and overall utility and user experience (response time and user satisfaction).
The main privacy risks associated with LLMs stem from their internal workings and outputs, not just traditional security breaches. These risks include:
Verbatim Memorisation and Regurgitation: LLMs can memorise and reproduce exact sequences, including Personally Identifiable Information (PII) or confidential data, from their training sets. This happens because the model's objective is to predict the next word with the highest probability, leading to literal reproduction of unique or frequent data points.
Prompt Injection and Jailbreaking: Malicious prompts can bypass safety protocols, causing the LLM to reveal sensitive internal configurations or ignore ethical constraints.
Membership Inference Attacks (MIA): Adversaries can infer whether a specific individual's data was included in the model's training set by analysing its responses and confidence scores.
Attribute Inference: LLMs can infer sensitive attributes (e.g., health conditions, income bracket, location) about a person based on their queries or writing style, even if the information was not explicitly provided.
Model Inversion and Data Extraction: More sophisticated attacks aim to reconstruct portions of the raw training data by repeatedly querying and analysing the model's outputs.
3. How do current data protection regulations like GDPR challenge the fundamental architecture of LLMs?
Current data protection regulations, particularly the GDPR, pose profound and direct challenges to the fundamental architecture and operation of modern LLMs due to several core principles:
Lawfulness, Fairness, and Transparency: LLMs' "black-box" nature makes it difficult to explain how specific data influenced an output. Furthermore, it's practically impossible to notify every individual whose publicly available data (e.g., blog posts) was scraped for training, as required by GDPR Article 14.
Purpose Limitation: GDPR mandates data collection for "specified, explicit, and legitimate purposes." However, LLMs are "foundation models" trained on broad data for a wide array of unforeseen and undefined future applications, directly contradicting the need for a specific purpose at data collection.
Data Minimisation: This principle requires data processing to be "adequate, relevant and limited to what is necessary." LLMs, conversely, achieve performance and generalisability by ingesting massive, maximalist datasets, not minimal ones.
Accuracy (Right to Rectification): Individuals have the right to have inaccurate personal data rectified. LLMs can reproduce or "hallucinate" falsehoods about individuals, but correcting these inaccuracies is technically challenging as the information is diffused across billions of model parameters, not stored in discrete, editable records.
Storage Limitation and the Right to Erasure (Art. 17): GDPR dictates that data should not be kept longer than necessary, and individuals have the "right to be forgotten." For LLMs, excising a single person's data influence from the interconnected model weights without damaging overall integrity is currently technically infeasible at scale, often requiring prohibitively expensive full retraining.
4. What are the main types of Privacy-Enhancing Technologies (PETs) used for LLMs, and how do they impact accuracy?
The main types of Privacy-Enhancing Technologies (PETs) for LLMs include:
Statistical Privacy (e.g., Differential Privacy - DP): DP provides mathematical guarantees that the output of a model is statistically similar whether or not any single individual's data was included. It's implemented by "gradient clipping" (limiting influence of individual data) and "noise injection" (adding random noise to gradients during training).
Impact on Accuracy: DP directly degrades model utility. The injected noise obscures subtle but important patterns, leading to reduced accuracy and slower convergence. Stronger privacy guarantees (lower epsilon) require more noise and thus cause a greater hit to model performance. It can also have a "disparate impact," disproportionately harming accuracy for underrepresented groups.
Structural Privacy (e.g., Federated Learning - FL, On-Premise Deployment): FL trains a model collaboratively across decentralised devices without raw data leaving those locations. On-premise deployment involves hosting LLMs entirely on an organisation's own infrastructure.
Impact on Accuracy: FL can reduce accuracy because the central model learns from aggregated, potentially noisy, updates from clients, and non-identically distributed data across clients can hinder convergence. On-premise models depend on the availability of sufficient in-house data and expertise but can achieve high accuracy if well-resourced.
Data-Centric Privacy (e.g., Anonymisation/Redaction, Synthetic Data Generation): These techniques focus on removing or replacing sensitive information before it reaches the model. Anonymisation involves scrubbing PII, while synthetic data involves creating artificial datasets that mimic real data's statistical properties without actual PII.
Impact on Accuracy: Anonymisation can significantly reduce data utility because removed information (names, locations) often provides crucial context needed for the model to learn complex patterns, potentially leading to a less accurate model. Synthetic data's utility is highly dependent on its quality; if the generated data is poor or biased, the resulting model will inherit these flaws. For a rigorous privacy guarantee, the synthetic data generator itself must often be differentially private.
5. How are leading LLM providers like OpenAI addressing privacy for different user types?
Leading LLM providers like OpenAI employ a multi-tiered approach to data privacy, distinguishing significantly between their services for individual consumers and their offerings for enterprise clients:
Consumer Services (e.g., ChatGPT Free, Plus, Pro): By default, user conversations and content on these services may be used to train and improve OpenAI's models. This means user interactions effectively contribute to the AI's ongoing development, implicitly serving as "payment" for the service. Users can typically opt-out of this training in their account settings for future conversations or use "Temporary Chat" for sessions that are neither saved nor used for training.
Business Services (e.g., API Platform, ChatGPT Team, ChatGPT Enterprise): For these enterprise-grade services, OpenAI's policy is that customer data is not used to train their models by default. This contractual assurance is a critical value proposition for businesses, allowing them to use powerful models without risking their proprietary or confidential information being absorbed into a general-purpose AI. These services also offer more robust controls, such as configurable data retention policies (including zero data retention options for some), data residency options, and enterprise-grade security measures like encryption.
This differentiated approach creates a clear business model where enterprises pay a premium for enhanced data control and privacy guarantees, while consumer users often implicitly contribute data in exchange for free or lower-cost access.
6. What is the emerging trend in AI regulation, and how does it differ from traditional data protection laws?
The emerging trend in AI regulation marks a significant conceptual shift from focusing solely on protecting input data to a broader framework of managing the risks of the AI system itself, particularly its outputs and decisions. While existing data protection laws like GDPR provide a foundation, their application to the unique challenges of LLMs is complex and often contested. New AI-specific legislation, such as the EU AI Act and state laws in the US (e.g., Colorado AI Act), adopts a risk-based approach. This means:
Categorisation of AI Systems: AI systems are classified into tiers of risk (unacceptable, high, limited, minimal), with high-risk systems (e.g., in employment, credit scoring, critical infrastructure) facing stringent requirements.
Focus on Systemic Risk and Outputs: Compliance is no longer just about the lawful basis for processing personal data; it increasingly demands assessing, mitigating, and being transparent about the potential harms and biases arising from the AI application's outputs and decisions.
Mandatory Requirements: High-risk systems will face mandatory requirements including risk assessments (AI Impact Risk Assessments - AIRAs), high levels of accuracy, robust data governance, transparency about training data, and human oversight.
Transparency Mandates: Regulators will increasingly require developers to disclose details about their training data, including summaries and whether it contains copyrighted or personal information.
Accountability for Developers and Deployers: New laws impose distinct duties on both those who develop and those who deploy AI systems.
This evolution means AI compliance requires multi-disciplinary governance committees to assess holistic risks (bias, fairness, safety) beyond just data privacy. The regulatory landscape is also becoming fragmented, necessitating agile governance models for international businesses.
7. What ethical and legal debates surround the use of publicly available data for LLM training and the ownership of AI-generated content?
Significant ethical and legal debates surround the use of publicly available internet data for LLM training and the ownership of AI-generated content:
The "Publicly Available" Data Dilemma:Consent and Privacy Expectations: While data may be "publicly available" (e.g., blog posts, social media comments), this does not automatically grant a licence for its use in commercial AI training. Under GDPR, processing personal data still requires a lawful basis and transparency. Ethically, there's a disconnect between a user's expectation when posting online and their content being used to fuel commercial AI products.
Copyright and Intellectual Property: The use of copyrighted materials (books, articles, images) in LLM training datasets without permission or compensation is a major legal challenge, leading to high-profile lawsuits (e.g., The New York Times Co. v. Microsoft Corp. and OpenAI, Inc.). The outcomes of these cases will redefine "fair use" in the digital age and have profound implications for AI development.
Unresolved Questions of Ownership:Ownership of Inputs, Outputs, and Insights: While a business generally owns its proprietary input data, the ownership of the AI's output is ambiguous. For instance, who owns the copyright to an image generated from a user's creative prompt: the user, the AI provider, or neither? If an LLM generates novel market insights from a company's data, does that insight belong exclusively to the company?
Ownership of Model Improvements: If a company uses its unique data to fine-tune and improve a general-purpose model, does it gain any ownership stake in that improved model? Should it be compensated if its data-driven improvements benefit other users of the AI provider's services? These are complex intellectual property questions currently being negotiated in bespoke enterprise licensing agreements, lacking clear legal precedent.
8. What strategic recommendations are given for organisations to responsibly manage the privacy-accuracy dilemma and what does the future of LLM development look like?
For organisations, managing the privacy-accuracy dilemma requires a proactive, risk-based strategic framework:
Conduct AI Impact Risk Assessments (AIRA): Before deployment, comprehensively assess all AI risks, including bias, hallucinations, security vulnerabilities (like prompt injection), and potential misuse, documenting the model's purpose and impact.
Establish an AI Governance Committee: Form a multi-stakeholder committee (Legal, IT, Cybersecurity, HR, Business Units) to set enterprise-wide AI policies, approve use cases, oversee risk assessments, and ensure ethical alignment.
Implement a Layered Defense Strategy: Adopt a "defense-in-depth" approach, combining multiple PETs (e.g., on-premise models, synthetic data, input/output redaction) based on data sensitivity and application risk.
Data Mapping and Classification: Thoroughly map workflows where data interacts with LLMs and classify data by sensitivity to apply appropriate, risk-tiered controls.
Scrupulous Vendor Risk Management: Rigorously scrutinise third-party AI provider contracts, data handling practices, retention policies, data residency, and security certifications, rather than relying solely on default settings.
The future of LLM development is shifting towards more specialised, efficient, and inherently private models:
Rise of Data-Efficient Learning: Research is focusing on improving data quality over sheer volume, enabling high performance with smaller, curated datasets. This reduces computational costs and shrinks the privacy attack surface.
Shift to Sparse and Specialized Models: The trend is towards an ecosystem of smaller, "sparse expert" models fine-tuned for specific domains (e.g., legal, medical). These can outperform general models while presenting a more manageable privacy and security risk.
Privacy-by-Design Architectures: Future research aims to build models with inherent privacy, exploring "machine unlearning" for targeted data removal and "Explainable AI (XAI)" to bring transparency to model decisions.
Ultimately, the privacy-accuracy trade-off is an inherent characteristic of current LLMs. Organisations must embrace proactive governance, make deliberate risk-informed choices, and leverage innovation towards efficient, specialised models to responsibly unlock AI's potential while protecting data and building trust.